
 Feb 12, 2018
Feb 12, 2018  828.1k
828.1k

17
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Hadoop Blogs -
Apache Hive is a data warehouse infrastructure facilitates data summarization, data analysis, and data querying to manage large datasets that reside inside distributed storage system. Hive is an open source Hadoop platform that converts data queries into MapReduce jobs for quick handling of voluminous datasets and easy to execute as well.
In this blog, we will discuss on various Hive concepts and why it is important to learn Hive technology for a quick career progression in the competitive IT world.
The main highlights of blog include –
Let us explore each of the concepts in detail one by one for your reference.
Apache Hadoop is considered as the most popular technology when it comes to handling Big Data for enterprises. Hadoop is an ocean that offers a wide array of tools and technologies to work with Big Data effectively. One of the popular tools is Apache Hive that is deployed by data researcher to work on large datasets and data queries.
Apache Hive is a data warehouse infrastructure facilitates data summarization, data analysis, and data querying to manage large datasets that reside inside distributed storage system. Hive is an open source Hadoop platform that converts data queries into MapReduce jobs for quick handling of voluminous datasets and easy to execute as well.
Hive supports HiveQL query language that converts SQL-like queries into MapReduce jobs for easy execution and quick data handling. As a result, Hive technology is responsible to increase the flexibility of schema design and causes effective Data Serialization and De-serialization too.
Read: Key Features & Components Of Spark Architecture
Read More: Hive Interview Questions and Answers
Hive looks very much similar to SQL but Hive is based on Hadoop platform and MapReduce operations, so there are several key differences between two.
In this section, we will discuss on major components of Hive framework and how they work together to process Big Data more effectively as needed by the organizations. 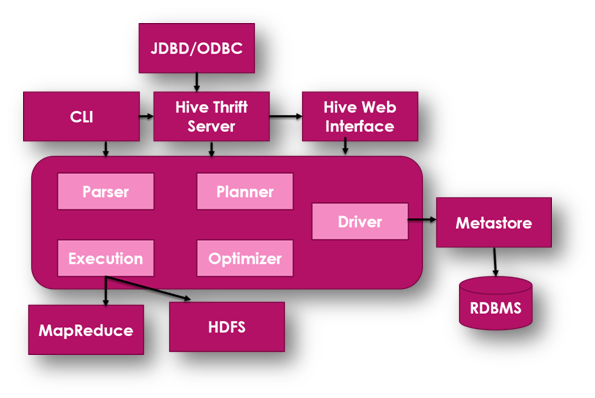
As the name suggests, metastore is the repository for metadata that is responsible to store location and schema of various data tables. It also holds information for partition metadata that allows you monitor the progress of various distributed data nodes stored in the cluster. Metastore generally works as traditional RDBMS systems that keep track of data, replicates data, and assures data recovery too.
The Driver works similar to a controller where HiveQL sends queries or statements. It monitors the progress of various executions and their lifecycle too. As soon as, HiveQL statement is executed, it creates metadata for the executed statement. Further, the query is managed by the MapReduce jobs and Driver collects the final query results.
A ‘Compiler’ is responsible to convert HiveQL queries into MapReduce inputs that include step by step guide to execute the tasks as output is further fed to MapReduce as required.
An ‘Optimizer’ is assigned the task of splitting data into small jobs or more optimized inputs that can be quickly processed by the Hive platform. As a result, the overall scalability and efficiency of the platform are enhanced.
Read: How to install Hadoop and Set up a Hadoop cluster?
The executor assigned the task of executing jobs when it is compiled and optimized. Further, Executor directly interacts with the Hadoop job tracker to schedule tasks that need to run.
The Command Line Interface and User Interface submit queries and monitors processes so that users can interact with the Hive Platform whenever required. At the same time, Thrift Server enables external clients to interact with the Hive platform.
Basically, Apache Hive is a data warehouse infrastructure facilitates data summarization, data analysis, and data querying to manage large datasets that reside inside distributed storage system. Here, are some popular reasons why Hive technology is gaining immense popularity by organizations.

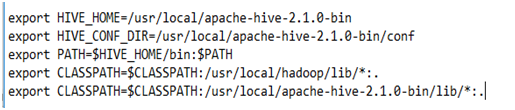

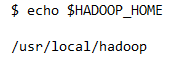


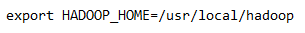
With these steps, Hive installation is complete on Ubuntu Linux and you just need an external database to configure Metastore.
Read: Top 10 Reasons Why Should You Learn Big Data Hadoop?
Hive learning allows you to work with Hadoop in a very efficient way. Hive has the capability to manage large datasets that are distributed across the network and users are able to connect freely with Command Line Tools and JDBC driver. Hive is base don Hadoop platform and plenty of tools from Hadoop can be integrated with Hive platform to make it even more powerful and useful.
Apache Hive is just the wonderful choice to master and it is popular across industries especially those handling voluminous every day. Most of the industries seeking for the right skills that can efficiently manage their Big data stored across the network and meaningful decisions can also be taken accordingly. Thankfully, Big data experts or Hive specialists enjoy higher salaries worldwide, so this would be a perfect choice learning Hive from reputed learning platform to give a right boost to your career.
Final Words:
With this blog, you clearly understood the concept the Apache Hive, its architecture, installation and why learning Hive is so important? Once you have gone through the blog, the time has come to take the right decision for your career. Let JanBask Training Hive Hadoop training and certification help you to boost your career.
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Hadoop Course
Interviews









 Jan 16, 2025
Jan 16, 2025 878.8k
878.8k

 878.8k
878.8k