 Mar 21, 2025
Mar 21, 2025  5.8k
5.8k

16
JanNew Year Special : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Data Science Blogs -
Deep Learning, Machine Learning & Artificial Intelligence have become trending words of the IT sector today.
But how many of you know what it is in reality? How many of you know what deep learning is ?
This blog that you will read today is an attempt towards making you well-versed with deep learning concepts as it will work as a Deep Learning tutorial.
Deep learning is an AI method that encourages PCs to do what easily falls into place for people: learn by model. Deep learning is a key innovation behind driverless autos, empowering them to perceive a stop sign or to recognize a passerby from a lamppost. It is the way to voice control in shopper gadgets like telephones, tablets, TVs, and sans hands speakers. Deep learning is getting heaps of consideration of late and all things considered. It's accomplishing results that were impractical previously.
In deep learning, a PC model figures out how to perform order errands straightforwardly from pictures, content, or sound. Deep learning models can accomplish best in class exactness, once in a while, surpassing human-level execution. Models are prepared by utilizing a huge arrangement of marked information and neural system structures that contain numerous layers.
At its easiest, deep learning can be thought of as an approach to computerize prescient investigation. While customary AI calculations are direct, deep learning calculations are stacked to expand multifaceted nature and deliberation.
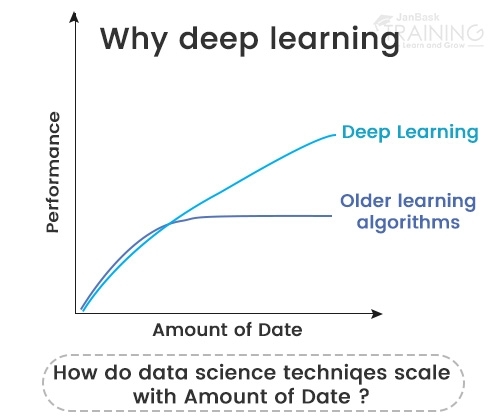
If it was to be a word, it would be exactness.
Profound learning accomplishes acknowledgment exactness at more significant levels than at any other time. This enables purchaser hardware to meet client desires, and it is pivotal for basic security applications like driverless autos. Ongoing signs of progress in profound learning have improved to the point where profound learning outflanks people in certain undertakings like grouping objects in pictures.
While profound learning was first speculated during the 1980s, there are two primary reasons it has as of late gotten helpful:
Deep learning requires a lot of market information. For instance, driverless vehicle advancement requires a large number of pictures and a huge number of long stretches of video.
Deep learning requires considerable figuring power. Elite GPUs have parallel engineering that is effective for profound learning. At the point when joined with bunches or distributed computing, this empowers improvement groups to diminish preparing time for a profound taking in organize from weeks to hours or less.
Data Science Training - Using R and Python

Here are some of the widely accepted benefits of deep learning-
Research from Gartner uncovered that a gigantic level of an association's information is unstructured because most of it exists in various kinds of arrangements like pictures, writings and so forth. For most AI calculations, it's hard to break down unstructured information, which means it's remaining unutilized and this is actually where profound learning gets valuable.
You can utilize various information configurations to prepare profound learning calculations and still get bits of knowledge which are important to the reason for the preparation. For example, you can utilize profound learning calculations to reveal any current relations between industry investigation, web-based life gab, and more to foresee up and coming stock costs of a given association.
In AI, highlight building is essential employment as it improves precision and now and again the procedure can require area information about a specific issue. Probably the greatest preferred position of utilizing a profound learning approach is its capacity to execute highlight building without anyone else's input.
Read: An Insight into the Intriguing World of the Data Scientist
In this methodology, a calculation filters the information to distinguish highlights which correspond and afterward join them to advance quicker learning without being advised to do so unequivocally. This capacity encourages information researchers to spare a lot of work.
People get eager or tired and, in some cases commit reckless errors. About neural systems, this isn't the situation. When prepared appropriately, a profound learning model gets ready to perform a large number of standard, monotonous undertakings inside a generally shorter timeframe contrasted with what it would take for an individual. Also, the nature of the work never debases, except if the preparation information contains crude information that doesn't speak to the issue you're attempting to settle.
Reviews are exceptionally costly, y and for certain ventures, a review can cost an association with a large number of dollars indirect expenses. With the assistance of profound learning, abstract imperfections which are difficult to prepare like minor item marking mistakes and so forth can be identified.
Profound learning models can likewise recognize surrenders which would be hard to identify something else. At the point when reliable pictures become testing on account of various reasons, profound learning can represent those varieties and learn important highlights to make the examinations robust.
The process of data labeling can be a costly and tedious activity. With a profound learning approach, the requirement for well-named information gets out of date as the calculations exceed expectations at learning with no rules. Different kinds of AI approaches are not as fruitful as this sort of learning.
Did you like all the benefits that Deep Learning has to offer? If yes, then you can avail of a free demo to get a better insight into this Deep Learning Tutorial.
Data Science Training - Using R and Python

Well, it is easier to follow a path in order to acquire a new skill, right?
Read: Data Science vs Machine Learning - What you need to know?
Relapse examination appraises the connection between measurable information factors to anticipate a result variable. Calculated relapse is a relapse model that utilizations input factors to foresee a straight out result variable that can take on one of a restricted arrangement of class esteems, for instance, "malignant growth"/"no disease", or a picture classification, for example, "Bird"/"vehicle"/"hound"/"feline"/"horse".
Strategic relapse applies the calculated sigmoid capacity to weighted information esteems to create a forecast of which of two classes the info information has a place with (or if there should be an occurrence of multinomial calculated relapse, which of various classes).
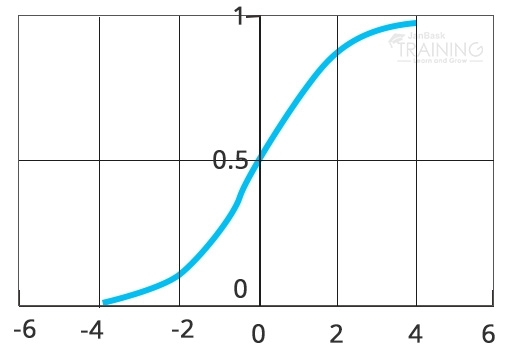
In profound learning, the last layer of a neural system utilized for the order can regularly be translated as a calculated relapse. In this specific circumstance, one can consider a to be learning calculation as different element learning stages, which at that point pass their highlights into a strategic relapse that arranges a piece of information.
Read: 10 Most In-demand Skills of Data Scientist to Flourish in Your Career
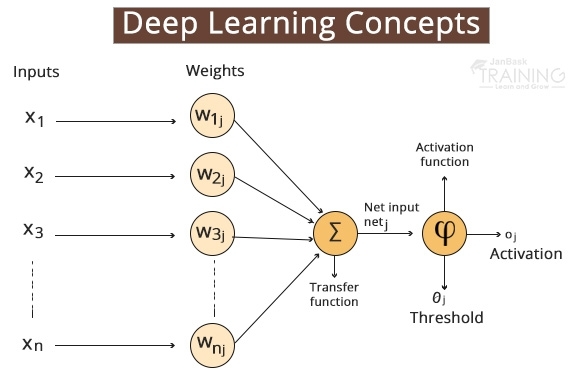
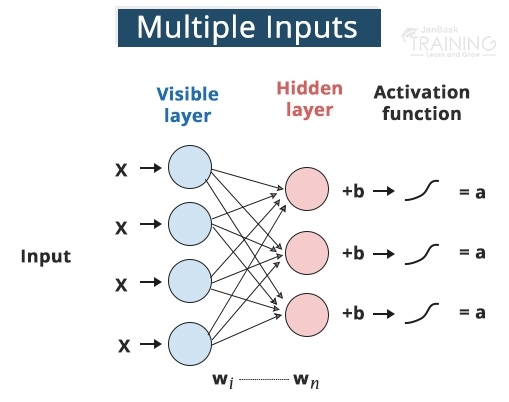
A system of the artificial neural network takes some data information and changes this information by figuring a weighted aggregate over the sources of info and applies a non-straight capacity to this change to ascertain a middle of the road state. The three stages above comprise what is known as a layer, and the transformative capacity is frequently alluded to as a unit. The halfway states—frequently named highlights—are utilized as the contribution to another layer.
Through reiteration of these means, the counterfeit neural system learns different layers of non-straight includes, which is at that point consolidates in the last layer to make an expectation.
The neural system learns by creating a mistake signal that estimates the contrast between the expectations of the system and the ideal qualities and afterward utilizing this blunder sign to change the loads (or parameters) so forecasts get progressively precise.
A unit frequently alludes to the enactment work in a layer by which the sources of info are changed through a nonlinear initiation work (for instance by the calculated sigmoid capacity). Generally, a unit has a few approaching associations and a few active associations.
Read: Data Science vs Machine Learning - What you need to know?
Notwithstanding, units can likewise be progressively mind-boggling, as long momentary memory (LSTM) units, which have various enactment capacities with an unmistakable design of associations with the nonlinear actuation capacities, or max out units, which figure the last yield over a variety of nonlinearly changed information esteem. Pooling, convolution, and other information changing capacities are typically not alluded to as units.
The word the artificial neuron—or regularly just neuron—is a proportional term to unit, yet suggests a nearby association with neurobiology and the human mind while profound learning has almost nothing to do with the cerebrum (for instance, it is presently imagined that natural neurons are more like whole multilayer perceptrons as opposed to a solitary unit in a neural system). The term neuron was empowered after the last AI winter to separate the more fruitful neural system from falling flat and relinquished perceptron.
Notwithstanding, since the wild accomplishments of profound learning after 2012, the media regularly grabbed on the expression "neuron" and tried to clarify profound learning as mimicry of the human cerebrum, which is deluding and possibly perilous for the view of the field of profound learning. Presently the term neuron is disheartened and the more elucidating term unit ought to be utilized.
Data Science Training - Using R and Python

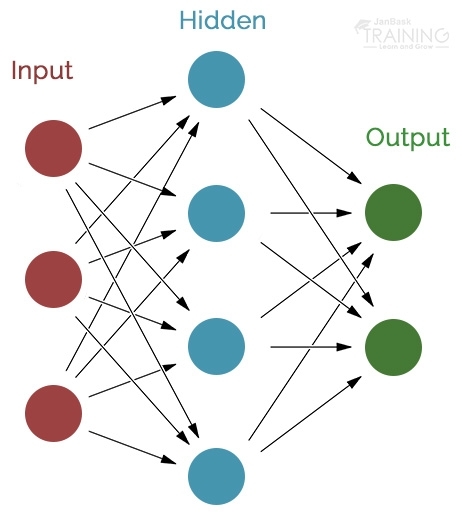
A layer is the most significant level building obstruct in profound learning. A layer is a holder that typically gets weighted input, changes it with a lot of generally non-direct capacities and afterward passes these qualities as yield to the following layer. A layer is generally uniform, that is it just contains one sort of enactment work, pooling, convolution and so forth with the goal that it very well may be effectively contrasted with different parts of the system. The first and last layers in a system are called info and yield layers, individually, and all layers in the middle are called concealed layers.
Pooling is a method that takes contribution over a specific region and lessens that to a solitary worth (subsampling). In convolutional neural systems, this convergence of data has the helpful property that active associations, as a rule, get comparative data (the data is "channeled" into the ideal spot for the info highlight guide of the following convolutional layer). This gives fundamental invariance to revolutions and interpretations. For instance, if the face on a picture fix isn't in the focal point of the picture yet marginally deciphered, it should at present work fine because the data is channeled into the correct spot by the pooling activity so that the convolutional channels can identify the face.
The bigger the size of the pooling region, the more data is dense, which prompts thin systems that fit all the more effectively into GPU memory. In any case, if the pooling region is excessively enormous, an excessive amount of data is discarded and prescient execution diminishes.
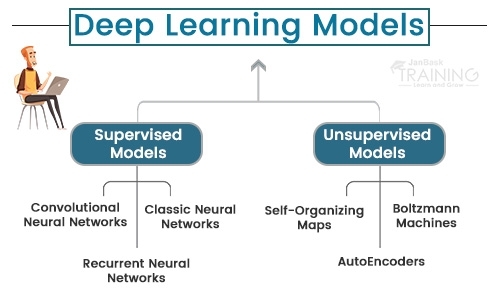
Various highlights recognize the two, however, the most indispensable purpose of distinction is in how these models are prepared. While administered models are prepared through instances of a specific arrangement of information, solo models are just given info information and don't have a set result they can gain from. With the goal that y-segment that we're continually attempting to foresee isn't there in a solo model. While directed models have assignments, for example, relapse and characterization and will deliver an equation, unaided models have bunching and affiliation rule learning.
Classical Neural Networks can likewise be alluded to as Multilayer perceptrons. The perceptron model was made in 1958 by American therapist Frank Rosenblatt. Its solitary nature enables it to adjust to fundamental paired examples through a progression of sources of info, reproducing the learning examples of a human-cerebrum. A Multilayer perceptron is the exemplary neural system model comprising multiple layers.
An increasingly proficient and propelled variety of exemplary fake neural systems, a Convolutional Neural Network (CNN) is worked to deal with a more noteworthy measure of intricacy around pre-preparing, and calculation of information.
CNN's were intended for picture information and maybe the most proficient and adaptable model for picture arrangement issues. Although CNN's were not especially worked to work with non-picture information, they can accomplish dazzling outcomes with non-picture information also.
Intermittent Neural Networks (RNNs) were created to be utilized around anticipating successions. LSTM (Long momentary memory) is a well known RNN calculation with numerous conceivable use cases.
Read: An Easy To Interpret Method For Support Vector Machines
Self-Organizing Maps or SOMs work with solo information and generally help with dimensionality decrease (diminishing what number of irregular factors you have in your model). The yield measurement is constantly 2-dimensional for a self-sorting out guide. So on the off chance that we have over 2 information includes, the yield is decreased to 2 measurements. Every neural connection associating out info and yield hubs have a weight allocated to them. At that point, every datum point seeks a portrayal in the model. The nearest hub is known as the BMU (best coordinating unit), and the SOM refreshes its loads to draw nearer to the BMU. The neighbors of the BMU continue diminishing as the model advances. The closer to the BMU a hub is, the more its loads would change.
Note: Weights are an attribute of the hub itself, they speak to where the hub lies in the info space
In the 4 models over, there's one thing in like manner. These models work in a specific heading. Even though SOMs are unaided, regardless of whether they work in a specific bearing as do regulated models. By heading, I mean:
Boltzmann machines don't pursue a specific course. All hubs are associated with one another in a round sort of hyperspace like in the picture.
A Boltzmann machine can likewise produce all parameters of the model, as opposed to working with fixed input parameters.
Such a model is alluded to as stochastic and is not the same as all the above deterministic models. Confined Boltzmann Machines are increasingly common sense.
Autoencoders work via consequently encoding information dependent on information esteems, at that point playing out an enactment capacity, lastly deciphering the information for yield. A bottleneck or some likeness thereof forced on the information highlights, packing them into fewer classifications. Hence, if some innate structure exists inside the information, the autoencoder model will recognize and use it to get the yield.
When you are carrying out a search like, you will come across the keywords like “deep learning tutorial python” or deep learning tutorial” or deep learning tutorial TensorFlow”. We also hear about new courses every day. Deep learning tutorial Stanford, Online Deep learning courses and keep getting confused. However, you can now easily start learning these amazing deep learning tutorials with JanBask Training. You can sign up for their Data Science Certification course.
The course is prepared with much craft and analysis. It covers all the essentials of deep learning that you will require to ace an interview or a job profile.
Liked the course? Sign up here and become a Deep Learning professional.
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Interviews









 Nov 16, 2023
Nov 16, 2023 5.7k
5.7k

James Wilson
"This deep learning tutorial is exactly what I needed! The step-by-step explanation makes it so much easier to understand the complex concepts behind neural networks. Great job!"
Michael Adams
"Amazing tutorial! I appreciate how you’ve explained deep learning fundamentals and included real-world applications. This will definitely help me as I dive deeper into AI and machine learning."