
 Apr 14, 2020
Apr 14, 2020  5.5k
5.5k

14
AugMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Data Science Blogs -
Deep learning is an artificial intelligence work that mimics the functions of the human brain in preparing information and making designs for use in dynamic or can say decision making. Deep learning is a subpart of machine learning in artificial intelligence that has systems fit for taking in unaided from information that is unstructured or unlabeled.
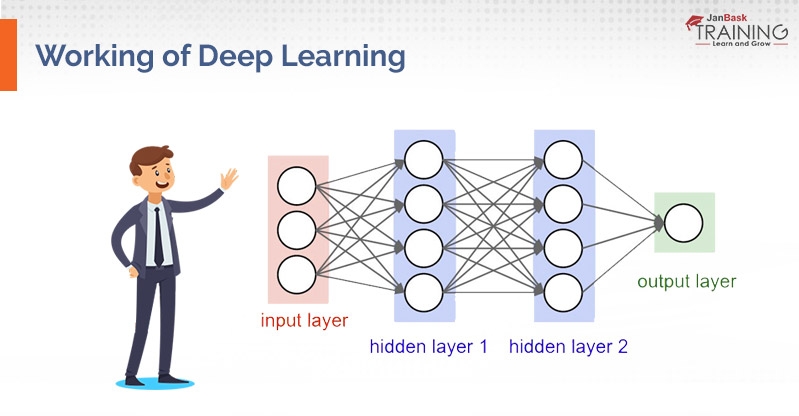
Deep Learning has progressed with the digital era, which has achieved a blast of information in all structures and from each region of the world. A large amount of data simply known as Big Data, are all drawn from sources like businesses, social platforms, media, search engines and many others. This huge measure of information is promptly available and can be shared through applications like distributed computing.
An enormous amount of unstructured data will take a lot of time to get analyzed so for that type of data we need to increase potential from the company by adapting AI for automated support so that we can increase the potential of the data
Keras consists of high-level neural networks API which is capable of running on Theano, Tensorflow and CNTK. It empowers quick experimentation through an elevated level, easy to use, measured and extensible API. Keras can run on CPU and GPU both.
Keras gives seven distinctive datasets, which can be stacked in utilizing Keras legitimately. These incorporate image datasets. The most straightforward method for making a model in Keras is by utilizing the successive API, which lets you stack one layer after the other. The issue with the consecutive API is that it doesn't permit models to have different sources of info or yields, which are required for certain issues.
Data Science Training - Using R and Python

Deep learning using Keras is performed by the following series of steps, which are:
Installation of Keras
For Keras installation, we can use either pip or conda command.
Command: pip install Keras
Understanding and splitting the dataset into training and testing set.
For this article, we are using a dataset that contains 80000 grayscale images with different classes.
Keras splits the dataset into two parts training and testing dataset. The training dataset consists of 70000 instances whereas the testing dataset contains 10000 instances.

Since it is an image dataset; we will process this dataset CNN (Convolutional Neural Network). Reshape method is used for the transformation of the dataset into four dimensions.
Code:
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
x_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
x_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
Now, labels are transformed using the to_categorical method of Keras.
Code:
from Keras.utils import to_categorical
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
There are two approaches for designing a deep learning model, one with sequential API and another with Functional API.
For this article, Functional API is used; It is simple, flexible and easily understandable. Functional API eases the building of complex network structures.
Code:
from Keras.models import Model
from Keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout, Input
inputs = Input(shape=x_train.shape[1:])
x = Conv2D(filters=32, kernel_size=(5,5), activation='relu')(inputs)
x = Conv2D(filters=32, kernel_size=(5,5), activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2))(x)
x = Dropout(rate=0.25)(x)
x = Conv2D(filters=64, kernel_size=(3,3), activation='relu')(x)
x = Conv2D(filters=64, kernel_size=(3,3), activation='relu')(x)
x = MaxPool2D(pool_size=(2, 2))(x)
x = Dropout(rate=0.25)(x)
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
x = Dropout(rate=0.5)(x)
predictions = Dense(10, activation='softmax')(x)
model = Model(inputs=inputs, outputs=predictions)
Data Science Training - Using R and Python

In Functional API, the previous layer acts as an input for the current layer which makes complex computation a bit easy compared to sequential API.
Model is compiled before training because it gives an idea of how efficiently the model is working which is defined by loss function and optimizer is used to minimize the loss by updating weights using gradients.
Code:
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
Since, image dataset is used to illustrate the concept of deep learning. Now, image data is augmented to create more data from the existing data. Image augmentation involves rotation of images, noise addition etc.
Since image dataset is used to illustrate the concept of deep learning. Now, image data is augmented to create more data from the existing data. Image augmentation involves rotation of images, noise addition etc.
Image augmentation makes the model more robust and makes it efficient when there is a huge amount of data. ImageDataGenerator method from Keras is used for image augmentation. It will generate new images of rotated or edited images.
Code:
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=10,
zoom_range=0.1,
width_shift_range=0.1,
height_shift_range=0.1
)
Fitting the designed model and Visualizing the training and test dataset.
After the compilation of the model, the dataset is ready to train. For training of dataset, fit_generator was used instead of the fit method from Keras because we are implementing DataGenerator. A number of epochs, X any Y dimension were passed to generator.
To monitor the loss and accuracy, a validation set is also passed to the generator.
Code:
epochs = 3
batch_size = 32
history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size), epochs=epochs,
validation_data=(x_test, y_test), steps_per_epoch=x_train.shape[0]//batch_size)
The output appears as:

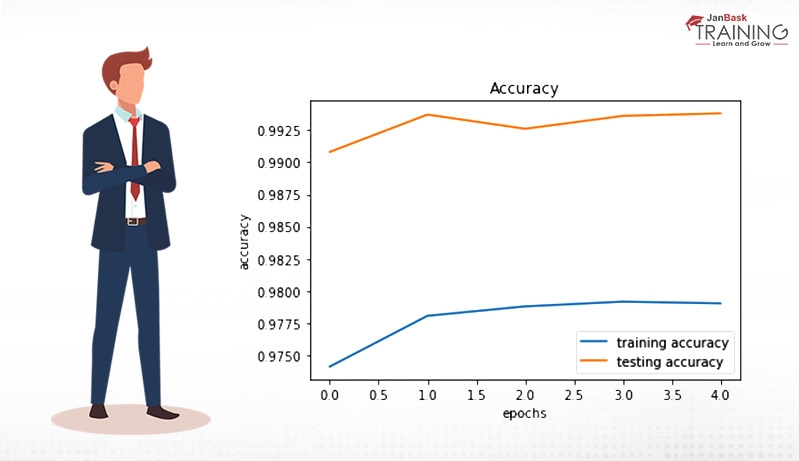
Now, for visualization of training and testing dataset and mapping its accuracy is performed as follows:
Matplotlib.pyplot is used for visualization of training, testing accuracy and loss for each epoch to make a better understanding of the model.
Code:
import matplotlib.pyplot as plt
plt.plot(history.history['acc'], label='training accuracy')
plt.plot(history.history['val_acc'], label='testing accuracy')
plt.title('Accuracy')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.legend()
The output appears as:
For understanding the loss pattern during training and testing are as follows:
Code:
plt.plot(history.history['loss'], label='training loss')
plt.plot(history.history['val_loss'], label='testing loss')
plt.title('Loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend()
The output appears as:
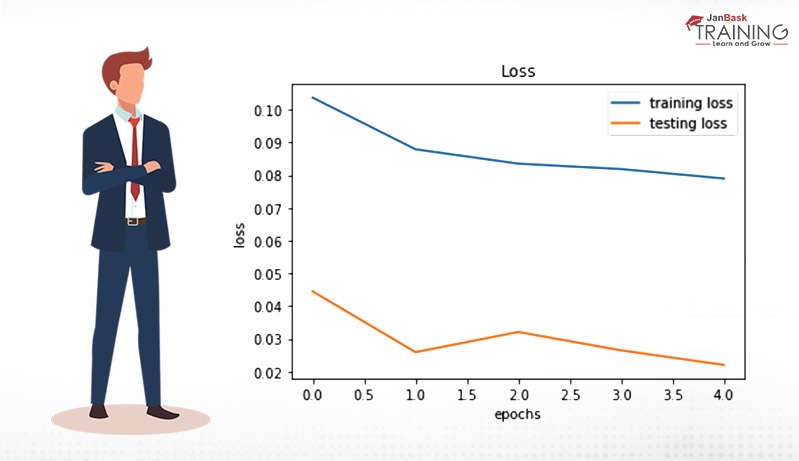
From the above graph, we can easily observe that the model is not overfitting. In that case, we need to train more epochs because of decrement in validation loss.
Keras is an elevated level neural systems API, fit for running on TensorFlow, Theano and CNTK. It empowers quick experimentation because it is quite easy to understand and scalable. In today era, everything needs to be robust and performs complex computation with ease so that the use of deep learning with Keras becomes popular. It is used in various medical applications and researches.
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
How Online Training is Better Than In-Person Training?
 163.9k
163.9k
Top 5 Python Testing Frameworks for Automation in 2025
6.8k
Deep Learning Tutorial Guide for Beginners
6.5k
Job Description & All Key Responsibilities of a Data Scientist
566.6k
What is Hypothesis Testing | Steps, Types, and Applications
2k
Receive Latest Materials and Offers on Data Science Course
Interviews









 Jan 04, 2022
Jan 04, 2022 163.9k
163.9k
