
 Mar 04, 2020
Mar 04, 2020  6k
6k

14
AugMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Data Science Blogs -
Deep learning is a hot technology nowadays. Why is this so special and what makes it unique from other aspects of machine learning? We need to learn basic concepts to get answers to these questions.
A neural network is an integration of basic elements neurons. Another term for neural network is artificial neural network, which is made of artificial neurons. The neural network can be connected to a biological neural network made up of real biological neurons and is used for solving artificial intelligence use cases. The biological neurons are connected, and the connection is represented as weights.
Deep Learning and Neural Network's main use cases as self-driving cars, Video Analytics, image recognition in Medical fields, face recognition, Object detection, Voice recognition, etc.
Neural Networks or Artificial Neural Network concept has been evolved from the human nervous system works.
Below is the basic structure of Neuron.
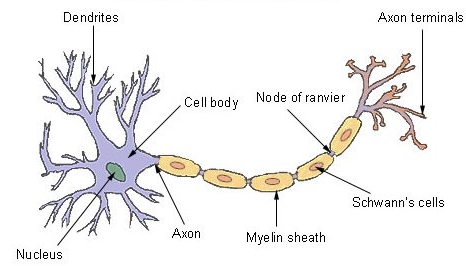
Below are major components of the neuron:
Dendrites- It takes input from other neurons in the pattern of an electrical impulse
Cell Body– It accepts the inputs and decide what action to take
Axon terminals– this generates outputs in the form of electrical impulse
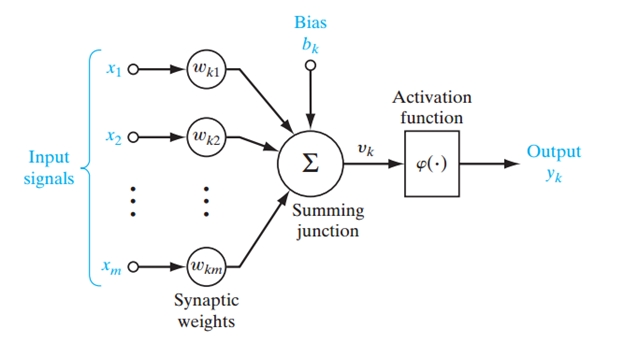
ANN also does the processing in the same way. Its general flow diagram can be as below.

This figure depicts a typical neural network with the working of a single neuron explained separately. Let’s understand this.
Read: How to work with Deep Learning on Keras?
Dendrites are input for neurons. Neuron collates all the inputs and performs an operation on them. In the end, it transmits the output to all other neurons of further next layer. Neural Network structure can be divided into 3 layers.
A single layer perceptron has one layer of weights connecting the inputs and output. It is the simplest kind of feed-forward network. In this network, the information always flows in the forward direction.
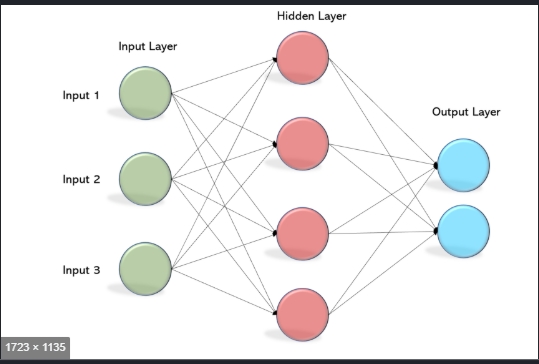
A multilayer perceptron is a subclass of feedforward artificial neural network. Multilayer perceptrons are also referred to as "vanilla" neural networks if they have only one hidden layer.
A multilayer perceptron (MLP) has one input layer, one output payer and there can be one or more hidden layers. Each layer has many neurons that are interconnected with each other by some weights. On a broad level, it is good to have a count of neurons in the input layer as a number of features in the dataset, while neurons in the output layer will be the number of classes in the dependent feature.
Activation functions introduce non-linearity into the output. In the Neural network, the sum of products of inputs(X) and their corresponding Weights(W) is calculated and the Activation function f(x) is applied over it to get the output of that layer and feed it as an input to the next layer.
A neural network without an activation function is simply just a linear regression model whose usage is very limited power and can solve only simple use cases. Neural Network not just learns and computes a linear function but expected to do something more complicated(images, videos, audio, speech data) analysis.
Data Science Training - Using R and Python

Some commonly used Activation functions
Sigmoid Activation function: It is an activation function with formula f(x) = 1 / 1 + exp(-x) The sigmoid transformation generates a range between 0 and 1. It is a S-shaped curve. It is easy to understand and apply but it has below issues which made its usage a bit limited.
Vanishing gradient problem (Its gradient is low so when multiplied with weight, weights become low passing through different hidden layers)
Read: Top 10 Data Science Influencers and Blogs to Follow in 2025
its output isn’t zero centered. That’s why gradient updates go too far in different directions.
Vanishing gradient problem (Its gradient is low so when multiplied with weight, weights become low passing through different hidden layers)
its output isn’t zero centered.

Hyperbolic Tangent function- Tanh: This function enables activation functions to range from -1 to +1. It is a shifted version of the sigmoid function. Tanh functions always perform better than sigmoid function.
f(x) = tanh(x) = 2/(1 + e-2x) - 1
ReLU- Rectified Linear units: The full form for this activation function is rectified linear unit. This is one of the most popular activation functions. One condition is that this can be implemented in only hidden layers of network. As per study using this function has given six times improvement in convergence compared to Tanh function. The major benefit of this is that it avoids vanishing gradient problems.
The output of the function is X for all values of X>0 and 0 for all values of X<=0. The function looks like this:
SoftMax Function: SoftMax activation functions usually used in the last output layer for architecture which gives final classification output. It is similar to the sigmoid function, the only difference is being that the outputs are normalized, to sum up to 1.
It is commonly used for multiple class classification problem statements. The SoftMax function compresses the outputs for each class and it gives probabilities for each class in the target field.
Cost Function – Cost function is used to increase the accuracy and performance of the neural network model. The cost function increases the performance of the model by penalizing the network when it makes errors. So the target should be to reduce the cost function which will reduce error value and hence prediction accuracy will be increased. The cost function is like a mean squared error.
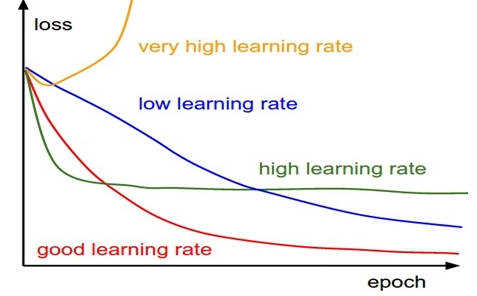
Learning Rate – Learning rate basically regulates the speed of the training network and how soon loss can be optimized. We can say the learning rate is defined as the amount of reduction in the cost function in each iteration. This learning rate is like tuning hyperparameters for designing and an optimizing network. The learning rate is an important configuration hyperparameter that can be tuned for training neural network models. It has a positive value normally between 0 and 1. We should select the optimum learning rate value. Its value should not be very high so that the optimal solution is passed and neither value should be very low so that a lot of time is required to converge the network.
Read: What do you Understand by AutoEncoders (AE)?
Epochs – As we know we don’t all input data in one single iteration. We pass in many batches for more stable training. One complete training iteration for all batches in both forward and backpropagation is called epochs. One epoch is a single forward and backwards pass of the entire dataset. Batch-size must be less than a number of samples in the training dataset.
Generally, networks with a higher number of epochs would give a more accurate model, but the high value of epoch may force networks to converge in a long time also the large value of epoch may cause overfitting also.
Dropout – Dropout layer is placed in the neural network to tackle overfitting. It is a type of regularization technique. In the Dropout layer, few neurons in the hidden layer are dropped in a random fashion. So, there will be different network combinations with a different random neuron connected. This can be thought of as different training networks as resembling. So there will be different network architectures where the output of multiple networks is then used to produce the final output. So the Dropout layer implements an ensembling algorithm.
Data Science Training - Using R and Python

If the Neural network has many hidden layers, dropout layers then training on input data goes deeper layers and this architecture is referred to as learning. If input datasets size is high for example in the case of image data, deep neural network is advantageous because it can process more complex information quickly and find complex relationships in data.
Neural networks cannot learn anything an intelligent human could not theoretically learn given enough time from the complex data. For example LinkedIn, for instance, neural networks along with linear text classification models to detect spam toxic content in their live feed LinkedIn also uses neural nets to different content categories posted on LinkedIn — for example whether it’s news articles or jobs or online classes. This content categorization can be used for Building live recommender systems. Here are further current examples of NN business applications:
Data Science Training - Using R and Python

Conclusion
With this blog, we have understood the concept of a series of networks, that is a neural network. Hope you will now be able to perform time-series predictions, anomaly detection, and understand natural language processing. Please let us know in the comment section below if you have more questions.
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Data Science Course
Interviews









 Apr 01, 2019
Apr 01, 2019 849.1k
849.1k

 849.1k
849.1k