 Jun 14, 2024
Jun 14, 2024  276k
276k

02
JanChristmas Offer : Get Flat 35% OFF on Live Classes + $999 Worth of Study Material FREE! - SCHEDULE CALL
- Hadoop Blogs -
More and more businesses are looking for experts with experience in Pig programming as Pig gains popularity in big data processing. It's critical to be familiar with the most typical questions if you're getting ready for a Pig interview. To assist you in preparing for your upcoming interview, we've prepared a list of the top 45 Pig interview questions and responses in this article. This list will be useful for brushing up on your skills and getting ready for your Pig interview, whether you're a novice or an experienced Pig programmer. Consider enrolling in a Big Data Hadoop training that will assist you in cracking your interview and landing your dream job as an Apache.
Before we move to the Apache Pig interview questions and answers, there are some key concepts you should know about Apache Pig:
Apache Pig is an Apache Software Foundation project, which is used for high-level language analyzing large data sets that consists of expressing data analysis programs. For executing data flows in parallel on Hadoop, Pig serves as an engine.
Rational operations are
This is how you should answer the Pig questions asked during the interview.
Pig Latin is the Scripting Language for the data flow that defines large data sets. A Pig Latin program consists of a series of operations, which is then applied to the input data in order to get the required output.
Pig Engine is the platform to execute the Pig Latin programs. Pig engine converts Pig Latin operators into a series of MapReduce job. This is one of the toughest Pig questions that’s why, many candidates don't pay attention to it.
Pig execution can be done in two modes.
Here is a quick go-through of the Hadoop Big Data tutorial for beginners to understand the concept better.
In MapReduce, The development cycle is very long. Writing mappers and reducers, compilingand packaging the code, submitting jobs, and retrieving the results is a time consuming process. Performing Dataset joins is very difficultLow level and rigid, and leads to a great deal of custom user code that is hard to maintain and reuse is complex.
In Pig, Compiling or packaging of code need not be done in Pig. Internally the Pig operators will be converted into the map or reduce the tasks.All of the standard data-processing operations are provided by Pig Latin, high-level abstraction for processing large data sets is possible.
When a Pig Latin Script is converted into MapReduce jobs, Pig passes through some steps. After performing the basic parsing and semantic checking, Pig produces a logical plan. The logical operators are described by the logical plan that is executed by Pig during execution. After this, Pig produces a physical plan. The physical operators that are needed to execute the script are described by the physical plan.
Pig is a high-level platform which makes executing many Hadoop data analysis issues simpler. A program written in Pig Latin resembles the query written in SQL, where an execution engine is utilized to execute the query. Pig engine is capable of converting the program into MapReduce jobs, where, MapReduce acts as the execution engine.
There are three ways in which Pig programs or commands can be executed
The Grunt acts as an Interactive Shell Pig. The major features are of Grunt are:
A bag is one of the data models present in Pig. The bag is an un-ordered collection of tuples with possible duplicates used to store collections while grouping. The size of bag equals the size of the local disk, this means that the size of the bag is limited. When the bag is full, then Pig will spill this bag into the local disk and keep only some parts of the bag in memory. There is no necessity that the complete bag should fit into memory. We represent bagswith "{}".
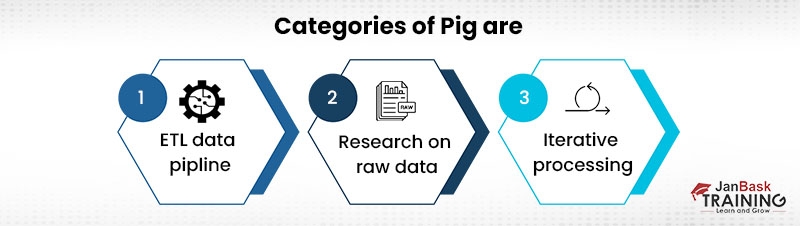
Most common use case for pig is data pipeline.
The scalar data types are:
During the Interview, these are the guidelines or ways in which you can answer similar pig questions. Learn more about SCala with this comprehensive Scala tutorial.
The group statement collects together records with the same key. In SQL the group by clause creates a group that must feed directly into one or more aggregate functions. No direct connection between group and aggregate functions is present in Pig Latin.
Sorting of data, producing a total order of the output data is done by the order statement. The syntax of order is similar to group ie by using the key or set of keys. The distinct statement removes The duplicate records is done by the distinct statement. It works only on entire records, not on individual fields.
Yes, it is possible to join multiple fields in pig scripts. Joining the select records from one input and to another input is done by indicating keys for each input. When the keys become equal, the two rows are successfully joined. One of the most challenging Pig questions is this one since so many candidates don't pay attention to it.
Yes, it is possible to display a limited no of results. The limit allows seeing only a limited number of results when needed.
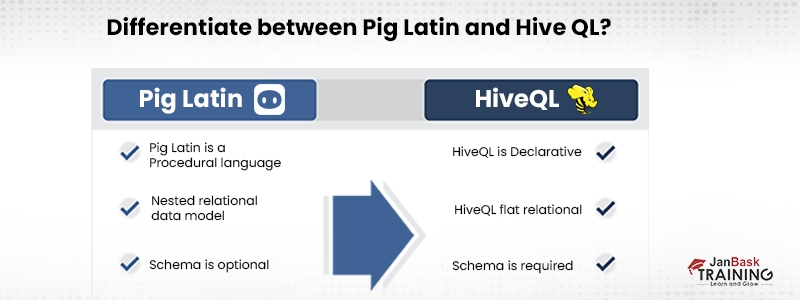
The user must explicitly define the type of every variable in a strongly typed language. When you describe the data schema in Apache Pig, it anticipates that the data will arrive in the same manner. However, the script will change to the real data types at runtime if the schema is unknown. So it may be claimed that PigLatin is firmly typed in the majority of circumstances, but gently typed in a small number of cases, i.e., it keeps working with data that does not meet its expectations.
The GROUP and COGROUP operators can both work with one or more relations and are functionally equivalent. The COGROUP operator can be used to group the data in two or more relations, whereas the GROUP operator is typically used to group the data in a single relation for better readability. COGROUP gathers the tables based on a column and then joins them on the grouped columns, which is more like a mix of GROUP and JOIN. Up to 127 relations can be Cogrouped at one time.
When counting the number of elements in a bag, the COUNT function does not include the NULL value, whereas the COUNT STAR (0 method does values while counting. Make sure to prepare for these types of Pig questions to crack your interview at the first attempt.
The Co-group only groups one specific data set when joining the data collection. The items are grouped according to their shared field, and after that, a collection of records containing two distinct bags is returned. The records of the first data set with the common data set are in the first bag, and the records of the second data set with the same data set are in the second bag.
No, the user-defined function "FUNCTIONAL" is not a keyword (UDF). Some functions must be overridden while using UDF. Obviously, you must complete your work using only these features. However, the keyword "FUNCTIONAL" has an inherent function, i.e. a pre-defined function, therefore it does not work as a UDF.
After processing, the data appears on the terminal and is dumped, but it is not saved. The output is executed in a folder and the store is stored in the local file system or HDFS. Hadoop developers most frequently used the store command to store data in the HDFS in a protected environment.
Because of this, running a pig script on a Hadoop cluster that is Kerberos secured can only go for as long as these Kerberos tickets are still valid. This could become a problem when performing really complicated analyses because the operation might need to continue for longer than these ticket times allow. This is how you should answer the Pig questions asked during the interview.
The Flatten modifier in Pig can be used to eliminate the level of nesting from data that is sometimes contained in a tuple or a bag. Flatten tuples and un-nested bags. Un-nesting bags is a little more difficult because it necessitates the creation of new tuples, whereas the Flatten operator for tuples will substitute the fields of a tuple in place of a tuple. This is how you should answer the Pig questions asked during the interview.
When a Pig Latin Script is transformed into MapReduce jobs, Pig goes through a few phases. It creates a logical plan after doing the fundamental parsing and semantic testing. The logical plan outlines the logical operations that Pig must carry out while being executed. Pig then creates a physical plan. The physical plan outlines the actual physical operators required to carry out the script.
The term "DEFINE" functions like the name of a function. Following registration, we must define it. Whatever Java program logic you have created, we have both an exported jar and a jar that has been registered with us. The function in the exported jar will now be examined by the compiler. It searches our jar if the function isn't found in the library.
Let's put it this way: Pig is a high-level framework that streamlines the execution of numerous Hadoop data analytic tasks. And for this platform, we use Pig Latin. An SQL query needs an execution engine to be executed, just like a program written in Pig Latin does. As a result, when we built a program in Pig Latin, the pig compiler transformed it into MapReduce jobs. MapReduce serves as an execution engine as a result.
If you are looking for a career alternative apart from Apache, you can think of being an SQL developer. Here is a guide on Microsoft SQL server development.
In essence, it connects the data set by just grouping one specific data set. Additionally, it organizes the elements according to their shared field before returning a set of records that comprise two distinct bags. Records from the first data set with the common data set are contained in one bag, and records from the second data set with the common data set are contained in another bag.
Whether Apache Pig is case-sensitive or case-insensitive is unclear. The function COUNT is not the same as the function count, and X=load "foo" is not the same as X=load "foo," for example, since user-defined functions, relations, and field names in pig are case-sensitive. As an example, the keyword LOAD is the same as the keyword load in Apache Pig.
Although the pig has many built-in functions, there are times when we need to write complicated business logic that may not be possible to accomplish using primitive functions. As a result, Pig offers support for authoring User Defined Functions (UDFs) as a means of defining customized processing.
There are two operating modes for Apache Pig: the "Hadoop MapReduce (Java) Command Mode" and the "Pig (Local Mode) Command Mode." MapReduce requires connection to the Hadoop cluster, whereas Local Mode simply needs access to a single workstation, where all files are installed and run on a local host.
After processing, the data is shown on the terminal using the Dump Command, but it is not saved. Whereas output is executed in a folder and storage is in the local file system or HDFS. Most frequently, Hadoop developers used the store command to store data in the HDFS in a secure environment.
A field is a piece of data, and a tuple is an ordered set of fields. Make sure to prepare for these types of Pig questions to crack your interview at the first attempt.
Pig is simple to understand, which reduces the need to write intricate MapReduce routines to some extent. Pig operates in a step-by-step fashion. As a result, it is simple to write and, even better, simple to read.One of the most challenging Pig questions is this one since so many candidates don't pay attention to it.
One of the data models in Pig is a bag. It is a collection of tuples that is not ordered and may contain duplicates. Collections are kept in bags while being grouped. The size of the bag is constrained because it is equal to the size of the local disc. Make sure to prepare for these types of Pig questions to crack your interview at the first attempt.
A) PigStorage is the function that it uses by default to load and save data. PigStorage supports compressed and uncompressed versions of structured text files in the human-readable UTF-8 encoding. With the help of this function, any Pig data types—both simple and complex—can be read and written. A file, directory, or glob of data can be used as the load's input.
PigStorage([field delimiter], ['options']) is the syntax.
A) Pig loads and stores the temporary data produced by several MapReduce tasks using BinStorage.
Data that is stored on a disc in a machine-readable format is what BinStorage uses. Compression is not supported by BinStorage.
Multiple input sources (files, directories, and globs) are supported by BinStorage.
A region, region server, HBase Master, ZooKeeper, and catalog tables are the essential parts of HBase. These parts work together to store and track the regions in the system, monitor the region, monitor the region server, and coordinate with the HBase master component. One of the most challenging Pig questions is this one since so many candidates don't pay attention to it.
In a map-reduce system, group-by operations are carried out on the reducer side, and projection can be used in the map phase.
Pig Latin also has typical operations like order by, filters, group by, etc. that are similar to MapReduce.
We can examine the pig script to understand the data flows and to detect errors early.
Pig Latin for MapReduce is substantially less expensive to write and maintain than Java code.
A) All Hive UDFs, including UDF, Generic UDF, UDAF, GenericUDAF, and Generic UDTF, are invoked by Pig. You must define the Hive UDF in Pig using HiveUDF (handles UDF and GenericUDF), HiveUDAF (handles UDAF and GenericUDAF), and HiveUDTF (handles GenericUDTF).
The syntax is the same for HiveUDF, HiveUDAF, and HiveUDTF.
HiveUDF(name[, fixed parameters])
This is how you should answer the Pig questions asked during the interview.
AvroStorage uses Avro files to store and load data. Frequently, you may use AvroStorage to load and save data without having much knowledge of the Avros serialization standard. In an effort to translate a pig schema and pig data into avro data or avro data into pig data automatically, AvroStorage will try.
AvroStorage("schema|record name," "options")
A) To create a tuple out of one or more expressions, use the TOTUPLE function.
TOTUPLE(expression [, expression...]) is the syntax. Make sure to prepare for these types of Pig questions to crack your interview at the first attempt.
"Hadoop's Apache Pig is a useful tool for processing and analyzing big datasets. You may impress your potential employer and show off your Pig programming talents by practicing for your interview with our top 45 Pig interview questions and answers. You may approach your Pig interview with ease and land the job you've been looking for armed with the information and assurance you've received from this list However, feel free to use the comment option to ask any questions if you have any. Additionally, if you have already taken part in a Pig interview, we would appreciate it if you would add your Apache Pig interview questions in the comments section. Don’t wait any more. Begin your big data journey today and take the first step towards a fulfilling and rewarding career in the field, join the Big data Hadoop certification training for better understanding of the platform.
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Interviews









 Apr 20, 2017
Apr 20, 2017 121.9k
121.9k
