
 Jul 19, 2019
Jul 19, 2019  12.4k
12.4k

31
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Hadoop Blogs -
One of the most beneficial technical skills is the capability to analyze huge data sets. In this blog, we are going to specifically guide you to use Python and Spark together to analyze Big Data, Data Science, and Python.
Apache Spark is an open-source cluster-computing framework which is easy and speedy to use. Python, on the other hand, is a general-purpose and high-level programming language which provides a wide range of libraries that are used for machine learning and real-time streaming analytics. PySpark is a Python API for Spark.
Apache Spark is a real-time processing framework which performs in-memory computations to analyze data in real-time. Initially, Apache Hadoop MapReduce was performing batch processing only and was lacking in the feature of real-time processing. This was the reason Apache Spark was introduced. Apache Spark can perform stream processing in real-time and also takes care of batch processing. It supports interactive queries and iterative algorithms. Apache Spark has its own cluster manager where it can host its application.
Apache Spark is written in Scala programming language. To support Python with Spark, the community of Apache Spark released a tool named PySpark.
Well, truly, there are many other programming languages to work with Spark. But here are the top advantages of using Python with Spark-
Using PySpark, you can work with RDD’s which are building blocks of any Spark application, which is because of the library called Py4j. RDD stands for: -
Following are the features of PySpark: -
Learning Prerequisites
Before proceeding further to PySpark tutorial, it is assumed that the readers are already familiar with basic-level programming knowledge as well as frameworks. It is recommended to have sound knowledge of –
Software Prerequisites
To install PySpark in your system, Python 2.6 or higher version is required. By using a standard CPython interpreter to support Python modules that use C extensions, we can execute PySpark applications.
PySpark requires the availability of Python on the system PATH and use it to run programs by default. By setting a PYSPARK_PYTHON environment variable in conf/spark-env.sh (or .cmd on Windows), an alternate Python executable may be specified.
By including Py4j, all of PySpark’s library dependencies are in a bundle with PySpark. Further, using the bin/pyspark script, Standalone PySpark applications must run. Also, using the settings in conf/spark-env.sh or .cmd, it automatically configures the Java and Python environment as well. When it comes to the bin/pyspark package, the script automatically adds to the PYTHONPATH.
/usr/local/spark
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv sp
ark-2.4.0-bin-hadoop2.7 /usr/local/spark
# exit
export PATH = $PATH:/usr/local/spark/bin$ source ~/.bashrc$ spark-shell
Spark assembly has been built with Hive, including Datanucleus jars on the classpath
Using Spark’s default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: Hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: Hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service ‘HTTP class server’ on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ ‘_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
# ./bin/pyspark

SPARK_HOMEC:\Program Files (x86)\spark-2.4.0-bin-hadoop2.7\binSystem variables:
PATHC:\Windows\System32;C:\Program Files (x86)\spark-2.4.0-bin-hadoop2.7\binC:\Program Files (x86)\spark-2.4.0-bin-hadoop2.7\bin
When you click on the link provided above to download the windows utilities, it should take you to a Github page as shown in the above screenshot.
Spark-shellpysparkTo run PySpark applications, the bin/pyspark script launches a Python interpreter. At first build Spark, then launch it directly from the command line without any options, to use PySpark interactively:
$ sbt/sbt assembly
$ ./bin/pyspark
To explore data interactively we can use the Python shell and moreover it is a simple way to learn the API:
Read: Difference Between Apache Hadoop and Spark Framework
words = sc.textFile("/usr/share/dict/words")
words.filter(lambda w: w.startswith("spar")).take(5)
[u'spar', u'sparable', u'sparada', u'sparadrap', u'sparagrass']
help(pyspark) # Show all pyspark functions
However, the bin/pyspark shell creates SparkContext that runs applications locally on a single core, by default. Further, set the MASTER environment variable, to connect to a non-local cluster, or also to use multiple cores.
For example:
If we want to use the bin/pyspark shell along with the standalone Spark cluster: $ MASTER=spark://IP:PORT ./bin/pyspark
Or, to use four cores on the local machine: $ MASTER=local[4] ./bin/pyspark
Resilient Distributed Datasets: These are basically datasets that are fault-tolerant and distributed in nature. There are two types of data operations performed in RDD: Transformations and Actions. Transformations are the operations that work on input data set and apply a set of transform method on them. And Actions are applied by direction PySpark to work upon them.
Data frames: These are a collection of structured or semi-structured data which are organized into named columns. This supports a variety of data formats such as JSON, text, CSV, existing RDDs, and many other storage systems. These data are immutable and distributed in nature. Python can be used to load these data and work upon them by filtering, sorting, and so on.
Machine learning: In Machine learning, there are two major types of algorithms: Transformers and Estimators. Transforms work with the input datasets and modify it to output datasets using a function called transform(). Estimators are the algorithms that take input datasets and produces a trained output model using a function named as fit().
Without Pyspark, one has to use Scala implementation to write a custom estimator or transformer. Now, with the help of PySpark, it is easier to use mixin classes instead of using scala implementation.
You can make Big Data analysis with Spark in the exciting world of Big Data. Apache Spark is considered as the best framework for Big Data. Apache Spark is among the most popular frameworks of Big Data, which is used for scaling up your tasks in a cluster. It was created to utilize distributed in-memory data structures to improve data processing speed.
PySpark is called as a great language to perform exploratory data analysis at scale, building machine pipelines, and creating ETL’s (Extract, Transform, Load) for a data platform. If you are familiar with Python and its libraries such as Panda, then using PySpark will be helpful and easy for you to create more scalable analysis and pipelines.
The Jupyter team created a Docker image to run Spark with AWS. Spark instance needs to be created for this. Amazon Elastic MapReduce or EMR is an AWS mechanism for Big Data analysis and processing. It helps in the management of a vast group of Big Data use cases, such as Bioinformatics, Scientific simulation, Machine learning, and Data transformations.
The purpose is to learn the fundamental level programming of PySpark.
Basic operations with PySpark
Let’s read a file in the interactive session. We will read “FILE.txt” file from the spark folder here. RDDread = sc.textFile("file://opt/spark/FILE.txt”)
The above line of code has read the file FILE.txt in RDD named as “RDDread.”
How does it look like? Let’s see the contents of the RDD using the collect () action- RDDread.Collect()
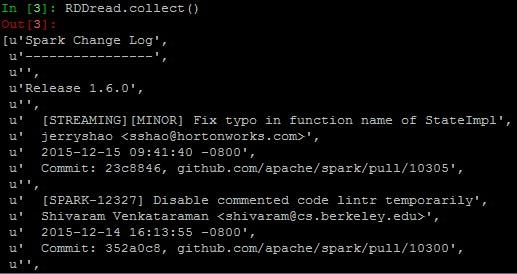
// Too much of output
So much of text is loaded in just a matter of few seconds and that’s the power of Apace Spark. This action is not at all recommended on a huge file as it would overload the driver memory with too much of text on the console. When performing collect action on a larger file, the data is pulled from multiples node, and there is a probability that the driver node could run out of memory.
Read: What Is Hue? Hue Hadoop Tutorial Guide for Beginners
To display the content of Spark RDD’s there in an organized format, actions like “first (),”” take (),” and “take a sample (False, 10, 2)” can be used.
2). Take (n)
This will return the first n lines from the dataset and display them on the console.
Example
RDDread.Take(5)
In [4]: RDDread.take(5)
Out [4]: [u’Spark Change Log’, u’-----------‘,u’’, u’Release 1.6.0’, u’’]
//The above line of code reads first five lines of the RDD
TakeSample (withReplacement, n, [seed]) - This action will return n elements from the dataset, with or without replacement (true or false). Seed is an optional parameter that is used as a random generator.
Example
RDDread. TakeSample(False,10,2)
In [5]: RDDread.takeSample(False,10,2)
Out[5]:
[u’ 2015-02-07 19:41:30 +0000’,
u’ [SPARK-5585] Flaky test in MLlib python’,
u’ [SPARK-10576] [BUILD] Move .java files out of src/main/scala’,
u’ ’,
u’ ’,
u’ ‘, [SPARK-8866][SQL] use 1us precision for timestamp type’,
u’ ’,
u’ 2015-11-07 19:44:45 -0800’,
u’ [SPARK-5078] Optionally read from SPARK_LOCAL_HOSTNAME’,
u’ Janbask Training janbask@janbasktraining.com’]
//This reads random ten lines from the RDD. The first parameter says the random sample has been picked with replacement. The last parameter is simply the seed for the sample.
3). def keyword
The basic functions in PySpark which are defined with def keyword, can be passed easily. This is very beneficial for longer functions that cannot be shown using Lambda.
def is_error(line):
return "ERROR" in line
errors = logData.filter(is_error)
4). Select columns
You can select and show the rows with select and the names of the features. Below, age and fnlwgt are selected.
df.select('age','fnlwgt').show(5)
+---+------+
|age|fnlwgt|
+---+------+
| 39| 77516|
| 50| 83311|
| 38|215646|
| 53|234721|
| 28|338409|
+---+------+
only showing top 5 rows
5). Count ()
It is used to know the number of lines in a RDD
Example
RDDread. Count()
In [6]: RDDread.count()
Out [6]: 34172
6). Count by group
together. In the example below, you count the number of rows by the education level.
df.groupBy("education").count().sort("count",ascending=True).show()
+------------+-----+
| education|count|
+------------+-----+
| Preschool| 51|
| 1st-4th| 168|
| 5th-6th| 333|
| Doctorate| 413|
| 12th| 433|
| 9th| 514|
| Prof-school| 576|
| 7th-8th| 646|
| 10th| 933|
| Assoc-acdm| 1067|
| 11th| 1175|
| Assoc-voc| 1382|
| Masters| 1723|
| Bachelors| 5355|
|Some-college| 7291|
| HS-grad|10501|
+------------+-----+
7). Describe the data
To get a summary statistics, of the data, you can use describe(). It will compute the :
Read: Your Complete Guide to Apache Hive Data Models
df.describe().show()
+-------+------------------+-----------+------------------+------------+-----------------+--------+----------------+------------+------------------+------+------------------+----------------+------------------+--------------+-----+
|summary| age| workclass| fnlwgt| education| education_num| marital| occupation|relationship| race| sex| capital_gain| capital_loss| hours_week|native_country|label|
+-------+------------------+-----------+------------------+------------+-----------------+--------+----------------+------------+------------------+------+------------------+----------------+------------------+--------------+-----+
| count| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561| 32561|32561|
| mean| 38.58164675532078| null|189778.36651208502| null| 10.0806793403151| null| null| null| null| null|1077.6488437087312| 87.303829734959|40.437455852092995| null| null|
| stddev|13.640432553581356| null|105549.97769702227| null|2.572720332067397| null| null| null| null| null| 7385.292084840354|402.960218649002|12.347428681731838| null| null|
| min| 17| ?| 12285| 10th| 1|Divorced| ?| Husband|Amer-Indian-Eskimo|Female| 0| 0| 1| ?|<=50K| | max| 90|Without-pay| 1484705|Some-college| 16| Widowed|Transport-moving| Wife| White| Male| 99999| 4356| 99| Yugoslavia| >50K|
+-------+------------------+-----------+------------------+------------+-----------------+--------+----------------+------------+------------------+------+------------------+----------------+------------------+--------------+-----+
If you want the summary statistic of only one column, add the name of the column inside describe()
df.describe('capital_gain').show()
+-------+------------------+
|summary| capital_gain|
+-------+------------------+
| count| 32561|
| mean|1077.6488437087312|
| stddev| 7385.292084840354|
| min| 0|
| max| 99999|
+-------+------------------+
8). Crosstab computation
In some occasion, it can be interesting to see the descriptive statistics between two pairwise columns. For instance, you can count the number of people with income below or above 50k by education level. This operation is called a crosstab.
df.crosstab('age', 'label').sort("age_label").show()
+---------+-----+----+
|age_label|<=50K|>50K|
+---------+-----+----+
| 17| 395| 0|
| 18| 550| 0|
| 19| 710| 2|
| 20| 753| 0|
| 21| 717| 3|
| 22| 752| 13|
| 23| 865| 12|
| 24| 767| 31|
| 25| 788| 53|
| 26| 722| 63|
| 27| 754| 81|
| 28| 748| 119|
| 29| 679| 134|
| 30| 690| 171|
| 31| 705| 183|
| 32| 639| 189|
| 33| 684| 191|
| 34| 643| 243|
| 35| 659| 217|
| 36| 635| 263|
+---------+-----+----+
only showing top 20 rows
You can see no people have revenue above 50k when they are young.
9). Drop column
There are two intuitive API to drop columns:
Below you drop the column education_num
df.drop('education_num').columns
['age',
'workclass',
'fnlwgt',
'education',
'marital',
'occupation',
'relationship',
'race',
'sex',
'capital_gain',
'capital_loss',
'hours_week',
'native_country',
'label']
10). Filter data
You can use filter() to apply descriptive statistics in a subset of data. For instance, you can count the number of people above 40-year-old - df.filter(df.age > 40).count() 13443
11). Descriptive statistics by group
You can group data by group and compute statistical operations like the mean.
df.drop('education_num').columns
['age',
'workclass',
'fnlwgt',
'education',
'marital',
'occupation',
'relationship',
'race',
'sex',
'capital_gain',
'capital_loss',
'hours_week',
'native_country',
'label']10). Filter data
You can use filter() to apply descriptive statistics in a subset of data. For instance, you can count the number of people above 40-year-old
df.filter(df.age > 40).count() 13443
11). Descriptive statistics by group
You can group data by group and compute statistical operations like the mean.
df.groupby('marital').agg({'capital_gain': 'mean'}).show() +--------------------+------------------+ | marital| avg(capital_gain)| +--------------------+------------------+ | Separated| 535.5687804878049| | Never-married|376.58831788823363| |Married-spouse-ab...| 653.9832535885167| | Divorced| 728.4148098131893| | Widowed| 571.0715005035247| | Married-AF-spouse| 432.6521739130435| | Married-civ-spouse|1764.8595085470085| +--------------------+------------------+
With this blog, we want to conclude that Apache Spark has so many use cases in various sectors. You can collaborate PySpark with Data Science, AWS, or Big Data to get most of its benefit as per your requirement. Concatenation of Python with Spark is amazing. Python is easy to learn and also collaborating Python with Spark framework, will help you in building blocks and operations of Spark using different technologies. In short, PySpark is truly a gift from Apache Spark’s community. Utilize this boon to get yourself into the latest trends of technology. Happy Learning!
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Hadoop Course
Interviews









 Jun 11, 2024
Jun 11, 2024 648k
648k

 648k
648k