
 Apr 25, 2020
Apr 25, 2020  7k
7k

17
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Data Science Blogs -
ANN (Artificial Neural Networks) is composed of multiple nodes which initiate biological neurons of the human brain. The neuron is connected to each other by links and they interact with each other using that link. The node takes the input data through the input layer and performs the operation on the data in the hidden layer. Result of these operations is passed to the other neurons. After computation, the result is passed to the output layer. The output layer delivers the result to the outer world. Modern AI problems are handled by ANN. If the hidden layer is more than two in any neural network than it is known as a deep neural network. It uses a cascade of multiple layers of non-linear processing units for feature extraction. The output of the current layer is fetched to the next layer as input. Deep Neural network consists of:
Nowadays these three networks are used in almost every field but here we are only focusing on Recurrent Neural Network.
RNN is a branch of neural network which is mainly used for processing sequential data like time series or Natural Language processing.
The ANN where the connection between nodes does not form a cycle is known as a fully feed-forward neural network. In this, the information flows in only one direction i.e. from i/p layer to hidden layer then from there to o/p layer. Hence, this type of processing creates some problem. Issues with the ANN:
To overcome this problem a special type of feed-forward neural network is introduced which is known as RNN. Since RNN allows variable size input and sequential information, therefore, it can be used for time-series data. This special feature makes it better than all existing other networks.
Recurrent neural networks are similar to Turing Machine. It is invented in the 1980s.
ht = fw(ht-1,) where ht = new state, ht-1= previous state, fw = activation function, xt = input vector

Figure 1: Vanilla Architecture
The above structure gives the basic idea behinds the RNN functionality. This structure is very famous and it is known as Vanilla Architecture. This design serves as a base for all other architecture. All the other RNN architectures all developed based on this idea. In RNN, we generally use the tanh activation function for the non-linearity in the hidden layer. In this architecture, the number of features is fixed. In the above design, x represents the input, RNN represents the hidden layer and y represents the output.
Data Science Training - Using R and Python

1. One-to-One: It is the most common and traditional architecture of RNN. It is also known as Vanilla Network. This architecture provides a 1 output for 1 input. It is generally used for the purpose of machine learning problems.

Figure 2: One-to-one
x=1, y=1
2.One-to-Many: It has 1 input and multiple outputs. It used in scenarios where need multiple outputs for a single input. It can be used in various fields like in the music industry where we produce music from a single input note.
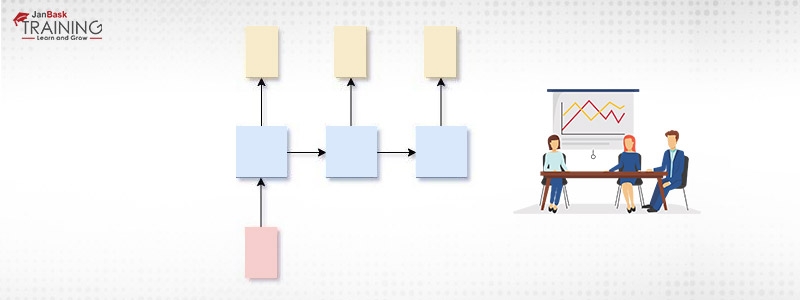 Figure 3: One-to-Many
Figure 3: One-to-Many
x=1, y>1
3. Many-to-One: This model is just the opposite of One-to-Many model. On One-to-Many we have a single input and multiple outputs but here we have multiple inputs and a single output for all of them. It can be used for sentimental analysis where we provide a complete sentence (multiple words as multiple inputs) to the model and it produces the sentiment of the sentence (single output).
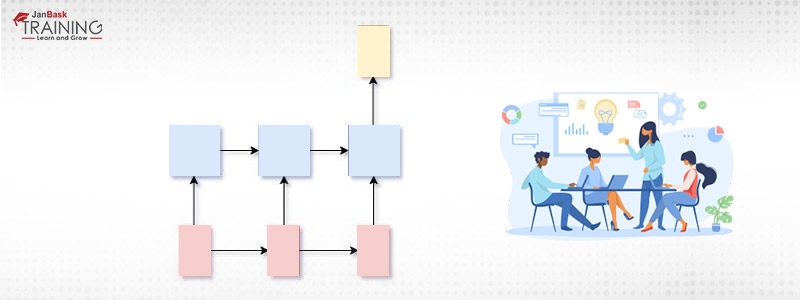
Figure 4: Many-to-One
x>1, y=1
4. Many-to-Many: It has multiple inputs and multiple outputs. This architecture is further divided into two subcategories:
x=y
In this case, the number of inputs to the model is equal to the number of produced outputs. This is used for Named-entity Recognition.
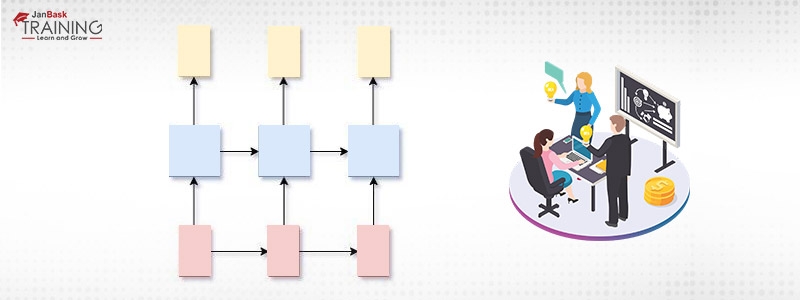
Figure 5: Many-to-Many(input=output)
x!=y
In this case, the number of inputs to the model is not equal to the number of produced outputs. This architecture is famous and is used at a variety of operation, the most common is Machine Translation.
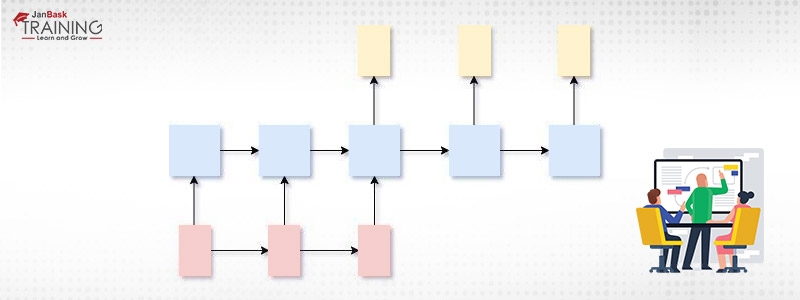
Figure 6:Many-to-Many(input!=output)
training the model, RNN uses a backpropagation algorithm, which is also known Backpropagation-through-time (BPTT) and this algorithm is applied for every timestamp. But using backpropagation also creates some problems which are:
1. Vanishing gradient:
When the value of the gradient is too small and the model stops learning or takes too much time because of that, it is known as the vanishing gradient. Let's see it in detail.
Data Science Training - Using R and Python

The main target behind using backpropagation is to calculate the error or loss. We calculate error by squaring the difference of actual output and estimated output.
e=(Estimated output – Actual output)2
After calculating error, we will calculate gradient which is the rate of change in error with respect to the rate of change in weight if this gradient is very very less than 1 then we can say gradient is vanishing. AS time goes this causes loss in the information.
2. Exploring gradient:
When an algorithm assigns high importance to weight without reason then it causes the gradient to be increasing in each iteration at a very high rate which eventually tends to infinity i.e. gradient is very-very large than 1 and may crash the model.
Various research proposed many methodologies, some of them are:
Data Science Training - Using R and Python

Here we are not discussing these techniques; we will discuss it in some other blog.
Data Science Training - Using R and Python

Speech Recognition,
Language Translation,
Video Analysis,
Text Mining,
Sentimental Analysis,
Time Series Prediction,
Machine Translation, etc.
So, guys, this is all about Recurrent Neural Network in a nutshell. In this blog, we understood about Artificial Neural Networks and Deep Learning. Then we saw how Recurrent Neural Network (RNN) is introduced, what it is about. After that, we discussed the architecture of RNN and its types and their applications in detailed. At last, we went through the problems in RNN and their solutions; also, the applications of RNN. Now in the next blog, we will learn about Long Short-Term Memory (LSTM).
Please leave query and comments in the comments section.
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Data Science Course
Interviews









 Apr 03, 2025
Apr 03, 2025 7k
7k

 7k
7k