 Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
As organizations increasingly adopt automation for managing their IT infrastructure, Ansible has emerged as a leading configuration management and orchestration tool. Ansible has gained popularity among DevOps professionals and system administrators with its simplicity, agentless architecture, and robust capabilities.
We have curated a list of essential Ansible interview questions, covering various topics from basic ansible interview questions concepts to advanced ansible interview question scenarios. Each question is accompanied by a concise answer to help you grasp the fundamental concepts and showcase your expertise during the interview. So, let's dive in and explore the world of Ansible together with our DevOps certification courses for professionals.
By familiarizing yourself with these ansible interview questions, you'll gain a solid understanding of Ansible's core principles, its integration with other technologies, and its ability to automate complex IT workflows.
Whether you're a beginner or an experienced Ansible user, this blog will equip you with the knowledge and confidence to tackle Ansible interview questions effectively. So, let's embark on this journey of mastering Ansible and prepare ourselves to shine in any Ansible interview!
DevOps Training & Certification Course

Q1: What is Ansible?
Ans:- Starting with the most basic Ansible interview questions, you can answer them like:-
Ansible is an open-source automation tool that simplifies the management and configuration of systems, applications, and infrastructure. It uses declarative language to describe the desired state of a system, allowing for easy orchestration and automation of tasks.
Q2: How does Ansible work?
Ans:- Ansible works by connecting to remote systems via SSH or WinRM and executing tasks on them using modules. It uses YAML-based playbooks to define the desired state and sequence of tasks to be performed on target hosts. Ansible's agentless architecture allows for easy setup and management.
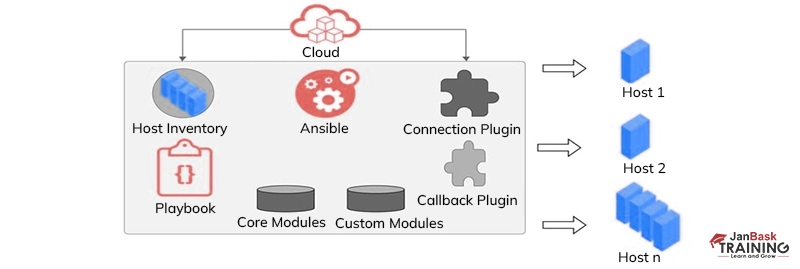
Q3: What is the Ansible playbook?
Ans:- Ansible playbooks are YAML files that define a set of tasks to be executed on remote hosts. Playbooks describe the desired state of a system and can include various tasks such as package installation, file manipulation, service management, and more. Playbooks can also include variables, conditionals, and loops to handle complex configurations.
Q4: What is an Ansible role?
Ans:- When you answer such Ansible interview questions, make sure to not go into details and answer it as:- An Ansible role is a pre-defined set of tasks, variables, and handlers organized in a structured way. Roles provide a modular approach to organizing and reusing Ansible code. They allow for easy sharing and reuse of common configurations, making it simpler to manage and maintain complex infrastructure.
Q5: How does Ansible differ from other configuration management tools?
Ans:- Ansible differentiates itself from other configuration management tools by its agentless nature, simplicity, and ease of use. Unlike tools like Puppet or Chef, Ansible does not require any agents to be installed on remote hosts. It uses SSH or WinRM for communication, making it lightweight and easy to set up.
Q6: How can you handle variables in Ansible?
Ans:- Ansible allows the use of variables to make playbooks more flexible and reusable. Variables can be defined at different levels, including host variables, group variables, and playbook variables. Variables can be assigned values inline or stored in separate variable files or inventories.
Q7: How do you handle error handling and retries in Ansible?
Ans:- Ansible provides various error-handling mechanisms. You can use the "failed_when" statement to specify conditions that determine task failure. Additionally, you can use the "ignore_errors" option to ignore errors and continue with the playbook execution. For retries, you can use the "until" and "retries" parameters in tasks to retry a task until a certain condition is met.
These are just a few basic questions and answers related to Ansible. Depending on the depth and level of the interview, more advanced and specific Ansible interview questions may be asked.
Q8: What is Ansible Fact?
Ans:- Ansible Facts are system properties and variables automatically discovered and collected by Ansible. They provide information about the target hosts, such as network interfaces, operating system details, hardware information, and custom facts. Facts can be used in playbooks to make dynamic decisions based on the characteristics of the target hosts.
Q9: How do you access shell environment variables in Ansible?
Ans:- You can answer such Ansible interview questions as:-
In Ansible, getting hold of existing shell environment variables is made simple using the 'env' lookup plugin.
For instance, if you're looking to retrieve the value of the Office environment on the management machine, you can effortlessly do so by incorporating the 'env' lookup plugin in your command, like this:
---
# ...
vars:
local_home: "{{ lookup('env','Office') }}"
I
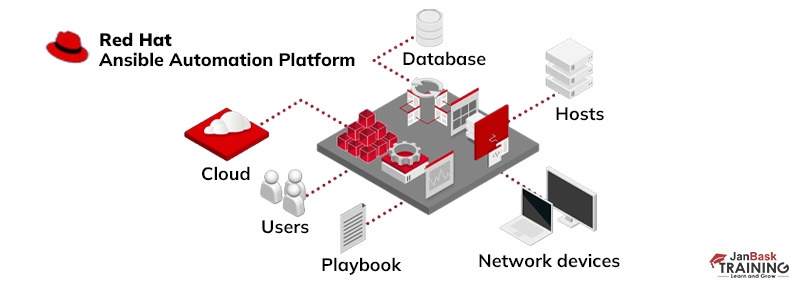
{{ ansible_env.SOME_VARIABLE }} Q10: What is Red Hat Ansible?
Ans:- Red Hat Ansible, encompassing both Ansible and Ansible Tower, stands as a comprehensive end-to-end automation platform. These platforms offer a range of features and functionalities, including:
Q11: How can you handle secrets and sensitive data in Ansible?
Ans:- This might sound like a tough or complicated Ansible interview question, but this can simply be answered as:-
Ansible provides a feature called "Ansible Vault" for securely storing and managing sensitive data such as passwords, API keys, and SSH private keys. Vault encrypts the sensitive data and decrypts it during playbook execution. The encrypted data is stored in an encrypted file, and the decryption key can be provided interactively or through automation.
Q12: Explain the difference between "handlers" and "tasks" in Ansible.
Ans:- In Ansible, tasks represent a set of actions to be performed on a target host. They can include commands, module invocations, or file operations. Tasks are executed in the order they appear in a playbook. Handlers, on the other hand, are special tasks that are only executed when notified by other tasks. They are typically used to restart services or perform actions that are dependent on changes made by previous tasks.
Q13: What is an Ansible inventory?
Ans:- Ansible inventory is a file that defines the hosts and groups of hosts that Ansible manages. It contains information such as IP addresses, hostnames, and groupings of hosts. The inventory file can be a simple text file or a dynamic inventory script that fetches host information from external sources like cloud providers or databases.
Q14: Can you explain the concept of idempotence in Ansible?
Ans:- This question takes a prominent place among interview questions on Ansible. Idempotence in Ansible means that executing a task multiple times should have the same result as executing it once. Ansible ensures idempotence by checking the current state of the system against the desired state described in playbooks. If a task has already been completed successfully, Ansible skips it during subsequent runs, preventing unnecessary changes.
Q15: How can you test Ansible playbooks?
Ans:- Ansible provides a tool called "ansible-playbook" that allows you to test playbooks. You can use the "--syntax-check" option to check the syntax of the playbook without executing it. The "--check" option performs a dry-run of the playbook, showing the changes that would be made without actually applying them. Additionally, you can use Ansible's "ansible-lint" tool to check for best practices and potential issues in your playbooks.
Q16: How does Ansible handle complex deployments involving multiple servers?
Ans:- Ansible uses the concept of inventory and groups to handle complex deployments involving multiple servers. You can define groups in the inventory file and specify which tasks or playbooks should be executed on specific groups or hosts. Ansible also supports parallel execution, allowing tasks to run concurrently on multiple servers.
Q17: What is Ansible Galaxy?
Ans:- Ansible Galaxy is a platform for sharing and discovering reusable Ansible roles. It is a repository of community-contributed roles that can be easily integrated into your playbooks. Ansible Galaxy provides a convenient way to extend Ansible's functionality by leveraging existing roles created by the community.
Q18: Can you explain the difference between Ansible ad-hoc commands and playbooks?
Ans:- Ansible ad-hoc commands are used for executing simple tasks on remote hosts without the need for a playbook. Ad-hoc commands are useful for one-time or quick tasks. Playbooks, on the other hand, are YAML-based files that allow you to define more complex tasks and orchestrate multiple steps. Playbooks provide more flexibility, reusability, and maintainability compared to ad-hoc commands.
This is an important Ansible interview question, make sure to explain this in detail a bit.
Q19: How can you handle the conditional execution of tasks in Ansible?
Ans:- Ansible provides conditional statements such as "when" to control the execution of tasks based on specific conditions. You can define conditions using Jinja2 templating syntax to evaluate variables, facts, or other expressions. Tasks with conditions will only be executed if the condition evaluates to true.
Q20: What is Ansible Tower (AWX)?
Ans:- Ansible Tower, now known as AWX, is an open-source web-based interface and automation platform built on top of Ansible. AWX provides additional features like a graphical dashboard, role-based access control, job scheduling, and a RESTful API. It allows for centralized management and monitoring of Ansible playbooks and provides a more user-friendly interface for managing automation tasks.
Q21: How can you extend Ansible's functionality using custom modules?
Ans:- Ansible allows you to create custom modules written in programming languages like Python. Custom modules enable you to extend Ansible's functionality by performing specific tasks that are not covered by the built-in modules. Custom modules can be used in playbooks like any other module, allowing for greater flexibility and customization.
Q22: What is a YAML file and how to use in Ansible?
Ans:- YAML file, short for "YAML Ain't Markup Language," is often the preferred format for creating complex structures of data, similar to JSON or XML. The use of YAML in Ansible is simple. You can easily create a YAML file and include all of your desired configurations in a single, easy-to-manage file. It's one of the many reasons why Ansible is so powerful and efficient in managing infrastructure.
<{
"object": {
"key": "value",
"array": [
{
"null_value": null
},
{
"boolean": true
},
{
"integer": 1
},
{
"alias": "aliases are like variables"
}
]
}
}
---
object:
key: value
array:
- null_value:
- boolean: true
- integer: 1
- alias: aliases are like variablesEnsure a thorough explanation of these crucial Ansible interview questions for a strong interview performance.
Q23: What is Ansible's task?
Ans:- The unit action of Ansible is called Ansible tasks. These tasks help in breaking a configuration policy into further smaller files pr codes. It can also be used in the automation process. For ex: To install or update software, we use:
Install, update
Q24: How to use YAML files in JAVA, Python, etc?
Ans:- Take a moment to elaborate on these important Ansible interview questions, to show your depth of understanding. YAML is the most versatile tool and can be supported by most high programming languages, it can also easily be used in user programs.
In JAVA, Jackson modules can be used to parse XML and JSON. For e.g.
We need to declare a Topic class with necessary attributes such as name, total_score, user_score, sub_topics
List topics = new ArrayList();
topics.add(new Topic("String Manipulation", 10, 6));
topics.add(new Topic("Knapsack", 5, 5));
topics.add(new Topic("Sorting", 20, 13));
// We want to save this Topic in a YAML file
Topic topic = new Topic("DS & Algo", 35, 24, topics);
// ObjectMapper is instantiated just like before
ObjectMapper om = new ObjectMapper(new YAMLFactory());
// We write the `topic` into `topic.yaml`
om.writeValue(new File("/src/main/resources/topics.yaml"), topic);
---
name: "DS & Algo"
total_score: 35
user_score: 24
sub_topics:
- name: "String Manipulation"
total_score: 10
user_score: 6
- name: "Knapsack"
total_score: 5
user_score: 5
- name: "Sorting"
total_score: 20
user_score: 13Similarly, in YAML it can be read as:
Loading the YAML file from the /resources folder
ClassLoader classloader = Thread.currentThread().getContextClassLoader();
File file = new File(classLoader.getResource("topic.yaml").getFile())
;// Instantiating a new ObjectMapper as a YAMLFactory ObjectMapper om =
new ObjectMapper(new YAMLFactory()); //
Mapping the employee from the YAML file to the Employee
class Topic topic = om.readValue(file, Topic.class)
Similarly, in Python, we can use the Pyraml library to easily read and write in YAML format.
Q25: What is CI/CD?
Ans:- Continuous Integration (CI) is a development practice that makes the process of integrating code changes smoother by automatically combining contributions from different developers into a shared repository.
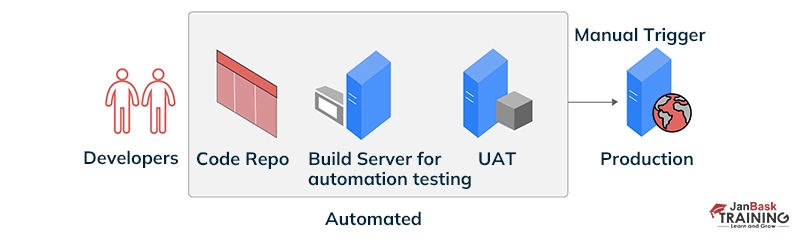
This helps catch integration issues early on, ensuring a more cohesive software development process. On the other hand, Continuous Delivery (CD) ensures that once code changes are pushed to a remote repository, they can be efficiently deployed to production at any time.
Essentially, CI/CD is all about creating a streamlined and automated pipeline to enhance the efficiency of software development and deployment.
Q26: What is Configuration Management?
Ans:- Configuration Management is a fundamental practice designed to help us keep a detailed record of all updates made to a system over time. This becomes particularly beneficial in situations where a significant bug emerges due to recent changes, and we need to address it swiftly with minimal disruption.
Instead of immediately fixing the bug, Configuration Management empowers us to roll back the recent changes that led to the issue, thanks to our meticulous tracking. This proactive approach not only ensures system stability but also streamlines the process of resolving issues effectively.
In your Ansible interview, articulate a detailed response to these key Ansible interview questions for a standout impression.
Q27: Explain Infrastructure as Code.
Ans:- Infrastructure as Code (IaC) is a vital process embraced by DevOps teams to bring greater organization to infrastructure management. Rather than relying on ad-hoc scripts or manual configurations for cloud components, IaC promotes the practice of storing all configurations in a code repository.
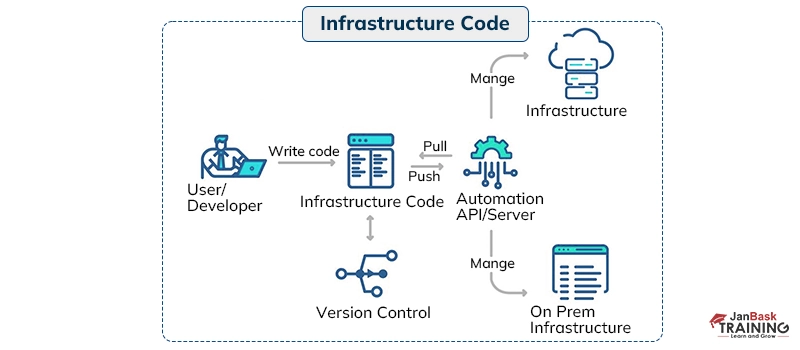
Any adjustments to the configuration are made through this repository, which is also placed under source control for added wisdom. This approach enhances speed, consistency, and accountability in managing infrastructure, offering a more efficient and traceable way of handling changes.
Q28: Explain Ansible modules in detail.
Ans:- Ansible modules serve as functional units or standalone scripts within the Ansible framework, executing specific tasks idempotently. These modules produce a JSON string in stdout as their return value, with input requirements varying based on the module type. They are employed by Ansible playbooks to automate and orchestrate tasks. Ansible modules are categorized into two types:
1. Core Modules: Maintained by the core Ansible team, these modules are bundled with Ansible itself. Issues reported for core modules are prioritized for swift resolution, distinguishing them from those in the "extras" repository.
2. Extras Modules: Managed by the Ansible community, these modules are currently shipped with Ansible but may be discontinued in the future. While still usable, feature requests or reported issues for extra modules may see lower-priority updates.
Notably, popular extra modules have the potential to transition into core modules over time. Separate repositories, namely ansible-modules-core and ansible-modules-extra, house these respective modules.
Q29: Could you walk me through the Ansible architecture?
Ans:- Absolutely. At the heart of Ansible is its automation engine, a pivotal player that collaborates directly with a variety of cloud services, the Configuration Management Database (CMDB), and individuals crafting playbooks to set the Ansible Automation engine in motion.
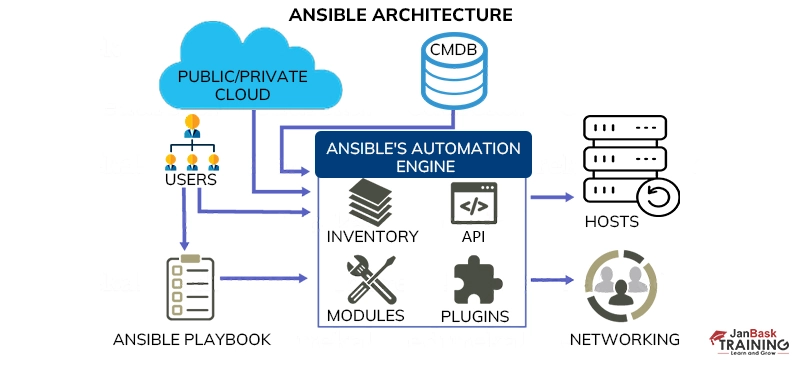
The Ansible Automation engine is composed of several key components:
Such particular Ansible interview questions hold significance; and provide a detailed explanation for maximum impact.
Q30: What does the term 'idempotency' mean?
Ans:- Idempotency is a key feature in Ansible that ensures we avoid unnecessary alterations to managed hosts. In simpler terms, it allows us to run one or more tasks on a server as many times as necessary without impacting anything that is already modified and functioning correctly.
To put it plainly, idempotency only introduces the changes that are required, steering clear of any modifications that are already in effect. This way, Ansible ensures efficiency by executing tasks without causing unnecessary disruptions to a system that's already working as intended.
Q31: What are the Ansible Server requirements?
Ans: Meeting the Ansible server requirements involves a couple of key elements:
Q32: You have a playbook that installs and configures a web server. However, you want to skip the installation task if the server already has the web server software installed. How can you achieve this in Ansible?
Ans:- You can use the Ansible yum or apt module with the state parameter set to present to ensure the package is installed. Additionally, you can use the register keyword to capture the output of the package installation task. Then, you can use the when conditional statement in the subsequent tasks to check if the package was already installed. If it is, you can skip the installation task.
Q33: You are managing a group of servers with different operating systems (Ubuntu and CentOS). You have a playbook that needs to install different packages based on the operating system. How can you achieve this in Ansible?
Ans:- Highlight your expertise by delving into the details of these vital Ansible interview questions with a detailed response.
Ansible allows you to define variables at different levels, including host variables and group variables. You can define variables specific to each operating system in the inventory file or in separate variable files for each group. Then, in your playbook, you can use the when conditional statement to check the value of the ansible_distribution variable and install the appropriate packages based on the operating system.
Q34: You have a playbook that deploys an application and restarts the service afterward. However, you only want to restart the service if there were changes made during the deployment. How can you achieve this in Ansible?
Ans:- Ansible provides a feature called "handlers" for handling tasks that should be executed only when notified. In your playbook, you can define a handler that restarts the service. Then, in the tasks that modify the application or configuration files, you can use the notify keyword to trigger the handler. The handler will only execute if it receives a notification, which will happen when changes are made during the deployment.
Q35: You have a playbook that needs to copy a file to multiple remote servers, but each server requires a different destination path. How can you achieve this in Ansible?
Ans:- Ansible allows you to define variables at different levels, including host variables and group variables. In your inventory file or in separate variable files for each group, you can define the destination path variable specific to each server. Then, in your playbook, you can use the copy module with the dest parameter set to the appropriate variable based on the target host.
Q36: You have a playbook that deploys a configuration file to remote servers. However, the configuration file contains sensitive information that should not be exposed. How can you handle this in Ansible?
Ans:- Ansible provides a feature called "Ansible Vault" for securely storing and managing sensitive data. You can encrypt the configuration file using the ansible-vault command-line tool and provide the decryption key during playbook execution. This way, the sensitive information remains encrypted and is only decrypted during runtime.
Q37: You have a playbook that needs to create a backup of a file on multiple remote servers before making changes to it. How can you achieve this in Ansible?
Ans:- Ansible provides the fetch module, which can be used to retrieve files from remote hosts. In your playbook, before making changes to the file, you can use the fetch module to retrieve a copy of the file from each remote server and store it in a backup directory on the control machine.
Q38: You have a playbook that needs to deploy an application to a group of servers, but you want to limit the number of concurrent connections to a specific number. How can you achieve this in Ansible?
Ans:- An important part of Ansible interview questions and answers, this query requires a thoughtful response, such as.
Ansible allows you to control the number of concurrent connections using the serial keyword. In your playbook, you can specify the number of hosts you want to deploy concurrently by setting the serial value to that number. Ansible will then execute the playbook tasks in batches, limiting the number of simultaneous connections.
Q39: You have a playbook that needs to perform different tasks based on the target host's role or group membership. How can you achieve this in Ansible?
Ans:- Ansible provides the when conditional statement, which allows you to perform tasks conditionally based on certain criteria. In your playbook, you can use the when statement to check if the target host belongs to a specific group or has a particular variable value. Based on the condition, you can execute different tasks or skip certain tasks altogether.
Q40: You have a playbook that needs to manage a set of firewall rules on multiple remote servers. Each server has a different set of firewall rules. How can you achieve this in Ansible?
Ans:- Ansible allows you to define host-specific variables in the inventory file or in separate host variable files. In your playbook, you can define a list variables for the firewall rules specific to each host. Then, you can use a loop and the iptables module (or the appropriate firewall module for the target system) to apply the firewall rules for each host.
Q41: You have a playbook that needs to install multiple packages on remote servers, but you want to ensure that the installation process is idempotent. How can you achieve this in Ansible?
Ans:- Ansible ensures idempotence by default, meaning that running the same playbook multiple times will have the same result as running it once. In your playbook, you can use the package manager modules such as apt or yum with the state parameter set to present. Ansible will automatically skip the installation if the package is already installed, ensuring idempotent execution.
Q42: How can you handle rolling updates or deployments in Ansible?
Ans:- Rolling updates or deployments can be achieved in Ansible by using the serial keyword in your playbook. By setting the serial value to a specific number, Ansible will execute the tasks in batches on a subset of hosts at a time. You can also combine this with strategies like max_fail_percentage to control the number of failures allowed during the deployment.
Q43: You need to deploy a complex application that consists of multiple services and requires specific configurations on each server. How would you structure your Ansible playbook to ensure modularity and reusability?
Ans:- Highlighting an essential component of Ansible interview questions and answers; provide your answer in the following manner.
To structure the playbook for modularity and reusability in a complex application deployment scenario, you can follow the Ansible Roles pattern. Create separate roles for each service or component of the application. Each role can contain tasks, handlers, variables, and templates specific to that service. By using roles, you can easily reuse and share common functionality across multiple playbooks, making the overall playbook structure more modular and maintainable.
Q44: You want to ensure that your Ansible playbooks are consistently formatted and follow a specific coding style. How can you enforce code formatting standards in Ansible?
Ans:- This is more than just a question; it's a fundamental part of Ansible interview questions and answers. Your answer should convey your expertise clearly and professionally:-
To enforce code formatting standards in Ansible playbooks, you can use tools like Ansible-lint or Ansible-lint rules in CI/CD pipelines. These tools check for common style guide violations, best practices, and potential issues in your playbooks. You can configure the rules according to your preferred coding style and include them as part of your automated testing and review process to maintain consistent and well-formatted Ansible code.
Q45: You are managing a large inventory of servers, and you want to perform a task on a specific subset of hosts based on their characteristics (e.g., specific operating system versions or tags). How can you achieve this selective execution in Ansible?
Ans:- Ansible provides several methods to achieve selective execution based on host characteristics:
You can use conditionals within tasks or playbooks, using the when directive, to evaluate specific facts, variables, or host attributes and control task execution based on the condition.
Utilize Ansible's inventory features, such as groups or group variables, to define subsets of hosts based on specific characteristics. You can then target these groups in your playbooks or tasks for selective execution.
Leverage host or group tagging to associate specific attributes or characteristics with hosts. You can then use these tags as filters in your playbooks or ad-hoc commands to target hosts with specific tags for execution.
Q46: You need to manage sensitive data in your Ansible playbooks, such as passwords or API keys. How can you securely handle and store this sensitive information?
Ans:- As you delve into Ansible interview questions and answers, pay special attention to this one. Craft your response meticulously to demonstrate your proficiency.
Ansible provides the Ansible Vault feature to securely handle sensitive data. Ansible Vault allows you to encrypt and decrypt variables, files, or even entire playbooks. You can create encrypted YAML files with sensitive data or encrypt specific variables using the ansible-vault command-line tool. Ansible Vault prompts for a password during decryption, ensuring that the sensitive information remains secure and can be safely stored in version control systems.
Q47: What are callback plugins in Ansible?
Ans:- Callback plugins serve as a control panel for output generation when running cmd programs. These plugins can also generate additional output beyond normal settings, such as playbook event logging with the log_plays callback and failure notification emails with the mail callback. You can introduce custom callback plugins by placing them in the callback_plugins directory near a play in a role or directory source configured in the ansible.cfg file.
Q48: How to install Nginx using the Ansible playbook?
Ans:- You can install Nginx by using the following method:
- hosts: stagingwebservers
gather_facts: False
vars:
- server_port: 8080
tasks:
- name: install nginx
apt: pkg=nginx state=installed update_cache=true
- name: serve nginx config
template: src=../files/flask.conf dest=/etc/nginx/conf.d/
notify:
- restart nginx
handlers:
- name: restart nginx
service: name=nginx state=restarted
- name: restart flask app
service: name=flask-demo state=restarted.The playbook above fetches all hosts for executing tasks on the staging web servers group. It starts by installing Nginx and configuring it, including a flask server for reference. They define handlers to restart Nginx in case of any state changes. Once the playbook is executed, it can be verified whether Nginx is installed or not.
Q49: How can you dynamically generate inventory in Ansible?
Ans:- Ansible allows dynamic inventory by writing custom inventory scripts or plugins. These scripts can fetch inventory information from various sources such as cloud providers, databases, or external systems. By executing the inventory script or plugin, Ansible dynamically generates the inventory based on the fetched information.
Q50: Explain how Ansible integrates with version control systems like Git.
Ans:- Ansible can integrate with version control systems like Git to manage playbooks and other Ansible-related files. Playbooks and associated files can be stored in a Git repository, enabling versioning, collaboration, and change tracking. Ansible can then pull the latest changes from the repository and execute the updated playbooks during deployments.
Q51: How can you secure sensitive data in Ansible playbooks?
Ans:- Ansible provides the ansible-vault command-line tool to encrypt sensitive data within playbooks. This tool allows you to encrypt variables, files, or entire playbooks using a passphrase. During playbook execution, Ansible can prompt for the decryption passphrase or retrieve it from a secure source, ensuring that sensitive data remains protected.
Q52: Explain how Ansible can be used for configuration drift management.
Ans:- Configuration drift occurs when the actual state of a system deviates from the desired state defined in Ansible playbooks. Ansible can be used to detect and remediate configuration drift by regularly executing playbooks against the target hosts. Playbooks can enforce the desired configuration, ensuring that systems are in the desired state and any deviations are corrected.
Q53: How can you achieve high availability with Ansible?
Ans:- This is a fundamental part of the interview questions on Ansible. Your answer should not only convey your understanding but also exude professionalism in addressing these interview questions on Ansible.
Ansible can be used to achieve high availability by leveraging features like load balancing and failover. Playbooks can include tasks to configure load balancers, monitor service health, and perform automatic failover. Additionally, Ansible Tower (AWX) provides clustering and HA features to ensure availability and scalability of the Ansible control plane.
Q54: Explain the difference between Ansible and Ansible Tower (AWX).
Ans:- Ansible is the open-source automation framework, while Ansible Tower (AWX) is a web-based interface and automation platform built on top of Ansible. AWX provides additional features such as a graphical dashboard, role-based access control, job scheduling, and RESTful API. It enhances the management and monitoring capabilities of Ansible and enables centralized automation control.
Q55: How can you handle complex variable management in Ansible?
Ans:- Ansible provides various mechanisms for managing variables in complex scenarios. You can use group variables, host variables, and role defaults to define variables at different levels. Ansible also supports variable precedence, allowing you to override variable values based on the order of precedence. Additionally, you can use the vars_files directive to load variables from external YAML files.
Q56: Explain how Ansible can be integrated with external tools and services.
Ans:- Ansible offers integrations with various external tools and services through modules and plugins. For example, Ansible can integrate with cloud providers like AWS or Azure to provision and manage infrastructure. It can integrate with monitoring systems like Nagios or Prometheus to perform health checks and trigger actions. Ansible also has modules for integration with network devices, databases, and other systems.
Q57: How can you handle complex role dependencies in Ansible?
Ans:- Ansible roles can have dependencies on other roles, allowing for modular and reusable configurations. You can define role dependencies in the meta/main.yml file of a role, specifying the required roles. Ansible will automatically resolve the dependencies and execute the roles in the correct order. You can also use role tags and conditionals to control the execution of dependent roles.
Q58: Explain how Ansible can be used for multi-tier application deployments.
Ans:- Ansible supports multi-tier application deployments by allowing you to define different roles or playbooks for each tier of the application stack (e.g., web server, application server, database server). You can define dependencies between the roles and use variables to configure each tier based on its specific requirements. Ansible's inventory management and group variables help organize and manage the different tiers.
Q59: How can you handle error handling and exception handling in Ansible?
Ans:- Ansible provides error handling mechanisms such as the failed_when directive, which allows you to define conditions for task failure. You can also use the ignore_errors directive to continue executing tasks even if they fail. Ansible supports exception handling through the block and rescue directives, allowing you to define tasks that should be executed in case of exceptions or failures.
Q60: Explain how Ansible can be used for continuous integration and continuous deployment (CI/CD).
Ans:- Ansible can be integrated into CI/CD pipelines to automate application deployments. You can use Ansible playbooks to provision infrastructure, configure environments, deploy applications, and perform testing. Ansible's idempotent nature and infrastructure-as-code approach make it suitable for CI/CD workflows. Ansible Tower (AWX) provides additional features for integrating with CI/CD tools and orchestrating deployments.
Q61: How can you optimize Ansible performance for large-scale deployments?
Ans:- Ansible performance can be optimized by leveraging features such as parallelism, asynchronous tasks, and persistent connections. You can configure the fork setting to control the number of parallel connections. Asynchronous tasks allow for parallel execution of independent tasks. Using persistent connections with SSH ControlMaster can reduce connection overhead. Caching facts and using strategies like free or linear can also improve performance.
Q62: Explain how Ansible integrates with cloud platforms like AWS, Azure, or GCP.
Ans:- Consider this question a pivotal component of Ansible interview questions and answers. Your reply should be thorough and align with the expectations of interviewers.
Ansible provides seamless integration with cloud platforms like AWS, Azure, and GCP through its cloud modules and plugins. These integrations allow you to manage and automate various aspects of cloud infrastructure and services using Ansible playbooks.
AWS Integration:
Azure Integration:
GCP Integration:
Q63: Describe Ansible's configuration management capabilities and how they compare to other tools like Puppet or Chef.
Ans:- Ansible, Puppet, and Chef are configuration management tools that help automate and manage infrastructure. Ansible stands out with its agentless architecture, meaning it doesn't require software installation on managed nodes.
It uses YAML, an easy-to-read language, for configuration. Puppet and Chef follow a client-server model and have their own specific languages. All three tools aim for idempotency, ensuring consistent desired states. Ansible provides resource abstraction with modules for various platforms, while Puppet and Chef have pre-built modules/cookbooks.
Ansible has a shallow learning curve, while Puppet and Chef require more advanced knowledge. All three have active communities and allow extensibility. Ultimately, the choice depends on specific needs and preferences.
Q64: How can you automate the testing of Ansible playbooks?
Ans:- To automate the testing of Ansible playbooks, you can use tools like Ansible Molecule, Test-Infra, CI pipelines, or Ansible Test Kitchen. These tools help you create test environments and run your playbooks automatically to check for errors or misconfiguration.
They allow you to define tests that validate the desired state of your infrastructure and provide feedback on the success or failure of the tests. By automating the testing process, you can ensure that your Ansible playbooks are reliable and produce the expected results, saving time and reducing the risk of errors in your infrastructure deployments.
Q65: How can you manage sensitive data such as passwords and private keys in Ansible?
Ans:- Ansible provides a feature called Ansible Vault for encrypting and storing sensitive data. Vault allows you to encrypt variables, files, or even entire playbooks using a password or a key. This ensures that sensitive information remains secure and can be safely stored in version control systems.
Q66: Explain the difference between the Ansible Playbook and the Ansible Role.
Ans:- An Ansible Playbook is a YAML file that defines a series of tasks to be executed on target hosts. It represents a single automation process or a workflow. On the other hand, an Ansible Role is a reusable and modular component that encapsulates a set of tasks, handlers, variables, and files. Roles help in organizing and reusing code across multiple playbooks.
Q67: How can you handle failures and errors in Ansible?
Ans:- Ansible provides several error-handling mechanisms. You can use the ignore_errors flag to continue executing tasks even if errors occur. Additionally, you can use the failed_when directive to define specific conditions that determine when a task should be considered as failed. Ansible also supports exception handling using the block, rescue, and always keywords.
Q68: What are Ansible Facts, and how can you gather system information using facts?
Ans:- Ansible Facts are system details or variables that are automatically collected by Ansible when it connects to a host. Facts provide information about the target system's hardware, operating system, network interfaces, and more. You can access these facts within playbooks or templates and use them for conditional execution or dynamic configuration.
Q69: How can you handle rolling updates and zero-downtime deployments with Ansible?
Ans:- Ansible provides strategies like rolling updates and canary deployments for achieving zero-downtime deployments. You can use techniques such as dynamic inventory, rolling update playbooks, and health checks to ensure that only a subset of hosts is updated at a time while maintaining the overall availability of the application or service.
Q70: What is the role of Ansible Tower's Workflow feature, and how can you use it?
Ans:- Ansible Tower's Workflow feature allows you to define complex multi-step automation processes. Workflows enable the coordination and chaining of multiple Ansible playbooks or job templates, along with branching, loops, and conditionals. This feature helps in creating more advanced and orchestrated automation workflows, allowing for greater flexibility and control.
Q71: How does Ansible handle the management of network devices?
Ans:- Ansible has built-in network modules and plugins that allow you to manage network devices such as routers, switches, and firewalls. These modules use various protocols like SSH, Telnet, or APIs specific to each device vendor. Ansible provides tasks and modules to configure network settings, manage VLANs, update access control lists (ACLs), and perform other network-related operations.
Q72: Explain the concept of Ansible Callbacks and how you can use them.
Ans:- Ansible Callbacks are plugins that allow you to customize the output and behavior of Ansible during playbook execution. They provide hooks at different stages of playbook execution, such as when a task starts or is completed. Callbacks can be used to generate custom reports, notifications, or perform additional actions based on the playbook's progress and results.
Q73: How can you extend Ansible's functionality using plugins and custom modules?
Ans:- Ansible allows you to extend its functionality through the use of plugins and custom modules. Plugins provide additional features like custom inventory sources, custom connection methods, or new variable types. Custom modules, written in programming languages like Python, enable you to interact with external systems or perform tasks not covered by the built-in modules. These extensions enhance Ansible's capabilities and allow for greater customization and integration with other tools or systems.
Q74: What sets Ansible apart from Puppet?
Ans:- When comparing Ansible and Puppet, several key distinctions come to light:
1. Management and Scheduling:
2. Availability:
3. Setup:
In summary, Ansible emphasizes simplicity and push configurations, while Puppet adopts a client-server model with a specialized language. The choice between them often depends on the specific needs of the user and the complexity of the configurations required.
Q75: What are handlers?
Ans:- Consider this question a cornerstone in Ansible interview questions and answers for experienced individuals. Your response should be a testament to your depth of experience and proficiency in Ansible interview questions and answers for experienced roles.
Handlers are essentially special tasks that come into play only if the associated task includes a "notify" directive. Let's break it down with an example:
yaml
Copy code
tasks:
- name: install nginx
apt: pkg=nginx state=installed update_cache=true
notify:
- start nginx
handlers:
- name: start nginx
service: name=nginx state=startedIn this example, after installing NGINX, the execution triggers the start nginx handler, initiating the server. Handlers provide a way to respond to specific events or changes in the system, ensuring precise and controlled actions are taken in response to defined triggers. They play a crucial role in orchestrating tasks in an Ansible playbook.
Q76: How does the Ansible synchronize module work?
Ans:- Ansible synchronizes module functions akin to the rsync command in Linux, offering a convenient tool for playbook usage. While it shares similarities with rsync, such as archive, compress, and delete functionalities, there are some important considerations:
Example of Synchronize Module:
yaml
Copy code
tasks:
- name: install nginx
apt: pkg=nginx state=installed update_cache=true
notify:
- start nginx
handlers:
- name: start nginx
service: name=nginx state=startedIn this example, files from the /var/tmp/sync_folder on the local machine are synchronized to the /var/tmp/ folder on the remote machine, showcasing the practical use of the synchronize module in Ansible playbooks.
Q77: How does the Ansible firewall module operate?
Ans:- This particular question is quite crucial in Ansible interviews, forming an essential part of Ansible interview questions and answers. Make sure your response is detailed and well-structured.
The Ansible Firewalld module serves as a tool for managing firewall rules on host machines, mirroring the functionality of the Linux firewalld daemon. It revolves around two key concepts:
Setting up a firewall through Ansible involves tasks like:
Example 1: Permitting traffic in the default zone for the HTTPS service
- name: permit traffic in the default zone for HTTPS service
ansible.posix.firewall:
service: https
permanent: yes
state: enabled
Example 2: Disallowing traffic in the default zone on port 8081/tcp
- name: do not permit traffic in the default zone on port 8081/tcp
ansible.posix.firewall:
port: 8081/tcp
permanent: yes
state: disabled
In these examples, the Firewalld module is employed to enable or disable traffic based on specific services or ports, providing a straightforward way to configure firewall rules in an Ansible playbook.
Q78: How does the Ansible set_fact module differ from vars, vars_file, or include_var?
Ans:- In Ansible, the set_fact module is distinct in its ability to dynamically set variable values on a host-by-host basis. Unlike vars, vars_file, or include_var, where values are known beforehand, set_fact allows the creation of variables during runtime based on specific tasks or conditions, leveraging filters or extracting subparts of existing variables. Here's a breakdown of the differences:
Usage:
Availability:
Dynamic Value Assignment:
Example:
- set_fact:
one_fact: value1
second_fact: value2
In this example, the set_fact module is utilized to dynamically assign values to one_fact and second_fact during runtime, showcasing the flexibility of this module in contrast to the static nature of vars, vars_file, or include_var.
Q79: What is the Ansible register and how does it work?
Ans:- The Ansible register serves as a mechanism to capture and store the output from task execution in a variable. This proves valuable when dealing with distinct outputs from multiple remote hosts. The register value persists throughout playbook execution, allowing manipulation of data using set_fact for subsequent tasks. Here's an explanation:
Usage:
register is employed to store the output of a task for later use in the playbook.
Scope:
The registered variable is accessible throughout the playbook, facilitating data manipulation and input for subsequent tasks.
Example:
- hosts: all
tasks:
- name: find all txt files in /home
: "find /home -name *.txt"
register: find_txt_files
- debug:
var: find_txt_files
In this example, the playbook searches for all .txt files in the remote host’s home folder. The output is captured in the find_txt_files variable using the register directive. This variable can then be utilized in subsequent tasks or manipulated using set_fact as needed. This flexibility is especially useful when dealing with diverse outputs from different hosts within the playbook.
Q80: How can tasks be delegated in Ansible?
Ans:- Ensure your response showcases your extensive expertise, making it a standout in Ansible interview questions and answers for experienced professionals.
Task delegation is a crucial aspect of Ansible, especially when there's a need to perform a task on one host with reference to others. This can be achieved using the delegate_to keyword. Here's an explanation and an example:
Usage:
The delegate_to keyword is utilized to specify a different host for the execution of a particular task.
Example:
- hosts: webservers
serial: 5
tasks:
- name: Take machine out of ELB pool
ansible.builtin.command: /usr/bin/take_out_of_pool {{ inventory_hostname }}
delegate_to: 127.0.0.1
- name: Actual steps would go here
ansible.builtin.yum:
name: acme-web-stack
state: latest
- name: Add machine back to ELB pool
ansible.builtin.command: /usr/bin/add_back_to_pool {{ inventory_hostname }}
delegate_to: 127.0.0.1
In this example:
Shorthand Syntax - local_action:
tasks:
- name: Take machine out of ELB pool
local_action: ansible.builtin.command /usr/bin/take_out_of_pool {{ inventory_hostname }}
It's important to note that certain tasks like include, add_host, and debug cannot be delegated. However, for most other tasks, the delegate_to or local_action syntax provides flexibility in managing task execution across hosts in Ansible.
Q81: What exactly are registered variables in Ansible?
Ans:- In Ansible, think of registered variables as bookmarks that stay with you throughout the playbook journey. Once you register them, they remain relevant on the host for the playbook's entire run—just like facts do in Ansible. They act as reliable sources for collecting and holding essential information.
Now, here's the interesting part: when you use 'register' with a loop, the variable gets a special 'results' tag. It's essentially a compilation of all the responses from the module, neatly organized for your convenience. So, in essence, registered variables become your systematic tools for capturing and utilizing critical details throughout your Ansible playbook, contributing to a well-orchestrated and efficient execution.
Q82: How does Ansible come into play in a Continuous Delivery pipeline?
Ans:- This question is a noteworthy component of Ansible interview questions and answers for experienced candidates. Your reply should not only demonstrate your experience but also align seamlessly with the expectations of experienced roles in Ansible interview questions and answers for experienced.
Ansible steps into the scene by smoothing out the collaboration between development and operations in the DevOps world – a vital piece of the puzzle for the seamless flow of modern, test-driven applications along the pipeline.
As we shift towards treating infrastructure as a core part of the application (you might hear this referred to as Infrastructure as Code or IaC), the focus becomes ensuring stability and performance.
IaC is all about managing computing infrastructure and configurations through straightforward definition files, ditching the old-school reliance on hardware configurations or complicated interactive tools. Enter Ansible, stealing the spotlight with its knack for automation and standing tall among its counterparts.
In the Continuous Delivery pipeline, the tag team between Sysadmins and developers tightens. This tag team not only amps up development speed but also frees up more time for the good stuff – think performance tuning, experimentation, and ticking off tasks – while keeping the troubleshooting and problem-solving hurdles to a minimum.
Ansible's automation chops are the unsung hero here, making the Continuous Delivery process not just efficient but also a breeze for everyone involved.
Q83: How do you test Ansible projects?
Ans:- Ansible testing involves three methods, each serving a unique purpose:
Question 1: What is Ansible used for?
Ans:- Ansible is used for automating IT tasks, including configuration management, application deployment, and orchestration. It allows administrators and developers to define and manage infrastructure as code, making it easier to scale, maintain, and ensure consistency across systems.
Question 2: Why is Ansible used?
Ans:- Ansible is chosen for its simplicity, scalability, and agentless architecture. It simplifies the process of managing complex infrastructures by using declarative language, eliminating the need for agents on target systems. Ansible's ability to automate repetitive tasks and enforce desired configurations makes it a popular choice for IT automation.
Question 3: What kind of tool is Ansible?
Ans:- Ansible is categorized as a configuration management and orchestration tool. It falls under the umbrella of DevOps tools, which streamline the collaboration between development and operations teams. With its focus on automation, Ansible helps maintain consistency, speed up deployments, and improve overall infrastructure management.
Question 4: How would you explain Ansible in an interview?
Ans:- In an interview, you can explain Ansible as an open-source automation tool that simplifies the management and provisioning of IT infrastructure. Its core principle revolves around defining infrastructure as code using a declarative language. Ansible's agentless architecture, extensive library of modules, and ability to work across different operating systems and cloud platforms make it a versatile and widely adopted tool in the DevOps ecosystem. Its use cases range from simple configuration management to complex application deployment and orchestration tasks.
Question 5: How does Ansible handle security and authentication?
Ans:- Ansible supports multiple methods for authentication and securing communication with target hosts. It can use SSH for connecting to remote hosts securely, and authentication can be handled through SSH keys or usernames/passwords. Additionally, Ansible supports vaults for encrypting sensitive data, such as passwords or API keys, within playbooks.
Question 6: What is the primary use case of Ansible?
Ans:- Ansible serves as a versatile tool with various applications, but its main use cases include:
By exploring the fundamental concepts of Ansible, such as playbooks, roles, modules, inventory management, and best practices, you have gained a comprehensive understanding of this powerful automation tool. Additionally, we delved into scenario-based questions that require practical application of Ansible in real-world situations.
Ansible continues to be a sought-after skill in the DevOps and IT operations domain, as organizations seek to streamline and automate their workflows. Join our devops training course to master ansible and contribute to the efficiency and scalability of infrastructure management, while also advancing your career prospects.
Good luck with your Ansible journey, and may it open up new opportunities for professional growth and success!
DevOps Training & Certification Course



Ultimate Guide to Mastering Docker Interview Questions in 2024
 May 10, 2024
May 10, 2024  2.3k
2.3k
Top Nagios Interview Questions & Answers in Linux
May 31, 2024 2.2k
Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment











