Introduction
Engrossment in machine learning algorithms has skyrocketed since a Harvard Business Review article titled ”Data Scientist- the Sexiest job of the 21st century.” All over the world, where all the physical work is being automatized, the meaning of the term manual is changing.
As we live in an age of continuous technological advancements, different types of ml algorithms are being helpful in getting smarter and more efficient, like automating surgeries, computers playing chess, etc.
Also, computing has developed over the course of time, which helps in making predictions about what’s to come in the days ahead. One of the significant aspects of this evolution is how machine learning tools and techniques have been standardized. And in order to solve several real-world complex challenges, a number of different kinds of machine learning algorithms types have been designed and developed by data scientists in these dynamic times.
If you’ve completed data science courses and machine learning, it won’t be difficult for you to learn machine learning algorithms. Without further ado, let’s delve into the list of machine learning algorithms you should know and how they’re classified.
Before that, let's first understand,
The Principle Behind Machine Learning Algorithms
There’s a standard principle that supports every supervised ml algorithm for predictive analytics.
Machine learning algorithms could be defined as learning a target function, “f,” that correctly depicts input variables,” X,” to an output variable “Y” -
Y= f(X)
It is a regular learning task where we choose to foretell future, “Y,” considering new examples of machine learning algorithm input variables, “X.” we’ve got no idea how the function, “f,” looks like or its created. In case we did, it would be used directly if we did, and we won’t require to learn it using data with the help of machine learning algorithms.
The predominant kind of ml is learning aligning Y= f(X) to forecast Y for new X. It is known as “Predictive modeling” or “Predictive analytics,” and the aim should be to forecast absolutely right forecasts.
Machine Learning Algorithms Types
Machine learning algorithms types can be categorized into 3 types-
- Supervised Learning Algorithms
It makes use of labeled training data in order to understand the mapping function that transforms input variables, “X,” into output variable, “Y.” to put it in another way, it resolves, “ f” in the equation given below
Y = f (X)
It facilitates us to produce outputs when new inputs are provided precisely.
There are 2 types of Supervised Learning Algorithms - Classification and Regression.
Classification-supervised learning algorithms are used to forecast the output of a specified sample when the output variable is in the style of categories. This model could look at input data and try to forecast labels like “sick” or “healthy.”
Regression-supervised learning algorithms are used to forecast the output of a specified sample when the output variable is in the shape of actual values. For instance, this model could analyze input variables to forecast the amt. of rainfall or the height of a specific person.
Examples of Supervised learning algorithms include - Linear Regression, Logistic Regression, CART, Naïve-Bayes, and K-Nearest Neighbors (KNN)
Another type of Supervised learning algorithm is -Ensembling. It means merging forecasts of numerous ml models that are discretely weak to generate more precise forecasts on a fresh sample. For example - Bagging with Random Forests, Boosting with XGBoost.
- Unsupervised Learning Algorithms:
These machine learning algorithms types are utilized when we just have input data or variables, i.e., “X” and no respective output variables. The unsupervised learning algorithms are used for unlabeled training data to prototype the primary structure of the data.
There are 3 types of Unsupervised Learning Algorithms - Association, Clustering, and Dimensionality Reduction.
Association unsupervised learning algorithms are used to determine the possibility of the concurrence of components in a group. It is utilized mainly in market-based research. For instance, this model could be utilized in identifying whether a consumer is buying bread or he/she is 80% might also buy eggs.
Clustering unsupervised learning algorithms are utilized to assemble samples such that objects within a similar cluster are more related than objects from other clusters.
Dimensionality reduction unsupervised learning algorithms are used to minimize the quantity of variables of a dataset at the same time making sure that the significant information is still communicated.
It can be carried out with the help of Feature Extraction techniques and Feature Selection techniques. Feature Selection chooses a subset of features of the actual variables. Feature Extraction carries out data transformation from a high dimensional to a low dimensional space. For instance, the PCA algorithm is a Feature Extraction technique.
Examples of Unsupervised learning include - apriori, K-means, etc. Explore more about machine learning career paths using machine learning tutorial with examples.
- Reinforcement learning algorithms:
It is a kind of ml algorithm that permits an agent to choose the best next move depending on the existing state by understanding the behaviors that’ll increase a reward.
These algorithms generally learn absolute actions via trial and error. Assume, for instance, a video game where a player must displace to particular places at particular times to collect points. When this algorithm is playing, that game is likely to begin by traversing randomly, but as time passes, via trial and error, it would understand where and when it’s required to move the in-game character to increase its total points.
Top ML Algorithms List You Need To Know
1. Linear Regression
As discussed earlier, it is a Supervised learning algorithm that aims to model the association between a continuous target variable and more than one individual variable by befitting an exponential equation to the data.
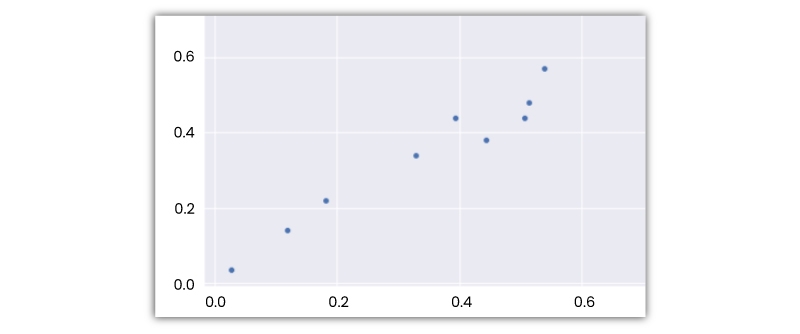
For a linear regression algorithm to be the best option, there requires to be a linear relationship between the target and independent variable (s). The relationship between variables like scatter plots, and correlation matrices can be explored using a number of tools. For instance, the scatter plot shown below represents a positive correlation between a separate variable, the “X-axis,” and a dependent variable, the “Y-axis.” when one variable increases, other variables also increase. 
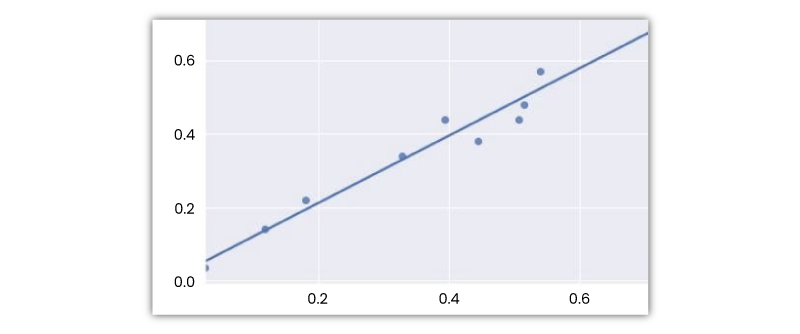
This model attempts to fit a regression line to the variable points that best showcase the relations or interrelations. The most popular method to make use of is OLE (i.e., Ordinary-least Square).
Using this technique, the best regression line can be found by reducing the sum of squares of the distance between the data points and the regression line. A regression line acquired with the help of OLE for the data points shown above looks like -
2. Support Vector Machine
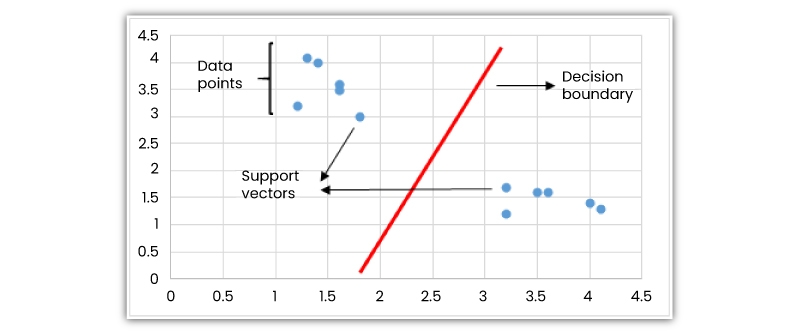
The SVM algorithm is a type of supervised learning algorithm commonly used for classification activities, but it is also best for regression activities. The support vector machine differentiates the classes by applying a decision boundary.
One of the most crucial parts of SVM algorithms is determining how to draw or evaluate a decision boundary. Before drawing the decision boundary, every observation or data point is formed in an n-dimensional space, where “n” is the number of features used.
Example of machine learning algorithm- if we make use of “length” and “width” to categorize various “cells,” data points or observations are plotted in a 2-dimensional space, and the decision boundary is plotted as a line.
If 3 features are used, the decision boundary is a plane in 3-dimensional space. And if more than 3 features are used, then the decision boundary will become a hyperplane which is actually difficult to see.
A decision boundary in 2D space is a line
A decision boundary is plotted in a manner that the distance upholds the vector maximizes. If the decision boundary is very close to a support vector, it’ll be extremely susceptible to noises and not established properly. In fact, a tiny change in independent variables might result in misclassification.
The above figure shows that the data points aren’t always linearly separable. In this situation, the SVM algorithm uses the Kernel trick, which determines the similarities or closeness between the data points in a higher dimensional plane to make them linearly distinguishable.
The kernel function is a type of similarity metric. The input variables are real features, and the output is a similarity metric in the new feature plane. Here, similarity means a degree of proximity. It's an expensive task in order to actually convert the data points into a new, higher-dimensional feature plane.
A kernelized SVM determines decision boundaries with reference to similarity measures in a higher dimensional feature plane without really carrying out the transformation. Because of this, it might be referred to as the Kernel trick.
This machine learning algorithm is specifically effective in situations where the no. of dimensions is more than the no. of samples. When identifying the decision boundary, SVM utilizes a subset of training points instead of each and every point, which helps in making it memory effectual.
On the contrary, training times reduce for massive datasets, which negatively affects performance.
3. Naive Bayes
Is a supervised learning algorithm utilized for classification activities. Therefore, also referred to as a “Naive Bayes Classifier.” this algorithm presumes that features aren’t dependent on each other and there’s no interrelation between them. But having said that, it's not the reality. This naive presumption of unrelated features is why this machine learning algorithm is referred to as “naive.”
The intent behind this ml algorithm is Bayes’s theorem -
Where
p(A|B): Is a probability of event ‘A’ given event ‘B’ has already taken place
p(B|A): Is a probability of event ‘B’ given event ‘A’ has already taken place
p(A): Is a probability of event ‘A’
p(B): Is a probability of event ‘B’
Naive Bayes classifier evaluates the probability of a class when provided with a set of feature values (i.e., p (yi | x1, x2, …, xn)).
Add this into Bayes’ theorem:
p(x1, x2, …, xn | yi) means the probability of a particular mix of features, i.e., an observation or row in a dataset, given a class label. We need extensive datasets to estimate the probability distribution for all combinations of feature values. To overcome this issue, the naive bayes algorithm assumes that all features are independent of each other. Furthermore, the denominator (p(x1,x2, …, xn)) can be removed to simplify the equation because it only normalizes the value of the conditional probability of a class given an observation ( p(yi | x1,x2, …, xn)).
The probability of a class ( p(yi) ) is elementary to calculate:
Under the presumption of features being separate, p(x1, x2 , … , xn | yi) could be written as:
For one feature provided with a class label i.e. p(x1 | yi) the conditional probability could be more effortlessly calculated from the data.
The respective machine learning algorithm needs to store probability distributions of features for every class separately. For instance, if there’re 5 classes and 10 features, different 50 probability distributions are required to be stored.
Adding everything up, it becomes a simple task for this algorithm to estimate the probability of finding a class given values of features (p(yi | x1, x2, …, xn))
The presumption that entire features are distinct makes this algorithm very fast as against complex algorithms. In a few cases, speed is chosen over greater accuracy. On the contrary, the `same assumption makes this algorithm less precise as compared to the complex algorithms.
4. Logistic Regression
It is a supervised learning algorithm commonly used for binary classification algorithms. Even though “Regression” differs from “Classification,” the center of attention here is on the word “logistic,” implying to logistic function that carries out the classification activity in the logistic regression algorithm.
This ml algorithm is an easy yet very efficient classification algorithm, so it's usually used for several binary classification activities. Different areas where this algorithm provides strong solution includes - consumer churn, spam email, website, or ad click forecasts.
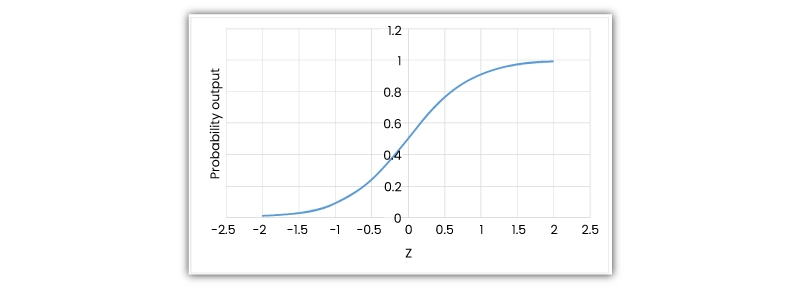
The foundation of this ml algorithm is the logistic function, also known as the sigmoid function, which takes in any actually valued no. and aligns it to a value amidst o and 1.
Assume that we need to solve the following linear equation
This machine learning algorithm takes a linear algorithm as input and utilizes logistic function and log odds to carry out a binary classification activity. Then, you’ll get the popular “S” shaped graph of this algorithm
We can make use of the calculated probability ‘as is.’ For instance, the result could be “the probability that this email is 95% spam or “the probability that a consumer would click this ad is 75%.”
But having said that, in many cases, probabilities are utilized to categorize data points. For example, if the probability is more than 50%, the prediction is a positive class, i.e., ‘1’. Or else it is a negative class, ‘0’.
It's not always wanted to select a positive class for each and every probability value of more than 50%. With respect to the spam email case, we need to be constantly assured so as to classify an email as spam.
As emails identified as spam are directly sent to the spam folder, we don’t wish the user to miss out on vital emails. Emails aren’t categorized as spam unless and until we’re entirely sure. On the contrary, we need to be more sensitive when categorizing a health-related issue. Even if we’re slightly doubtful that a cell is cancerous, we don’t wish to miss it.
Therefore the value that acts as a doorway between positive and negative classes depends on the problem. The positive thing is that the logistic regression algorithm enables us to alter this threshold value.
5. Nearest Neighbors (kNN)
It is a type of Supervised learning algorithm, that could be utilized to resolve both classifications as well as regression tasks. The basic thought behind kNN is that the value or class of a data point is evaluated using the data points in its vicinity of it.
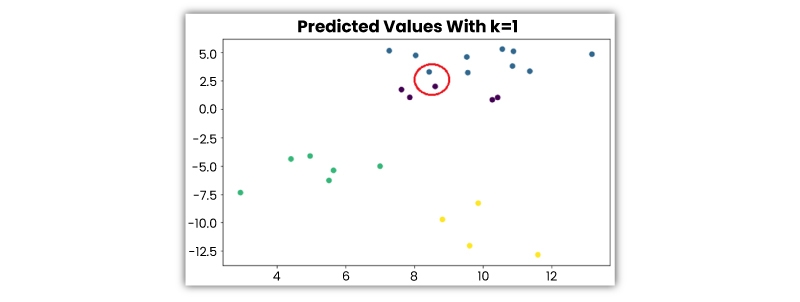
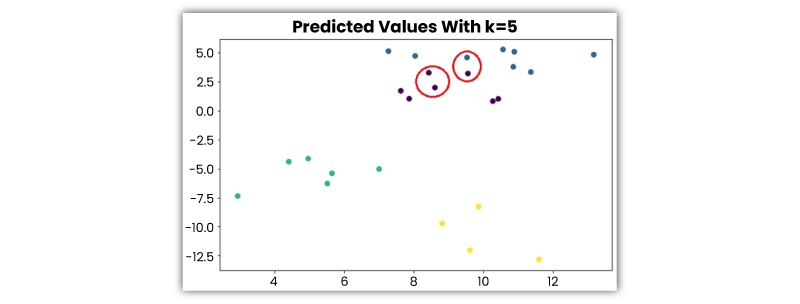
Using majority rule kNN classifiers evaluate the data point’s class. Let’s consider an example of machine learning algorithm- if a value of k is 5, then the classes of 5 closest data points would be checked. As per the majority class, predictions are made.
Likewise, kNN regression takes up the middlemost value of the 5 closest data points. Let’s look at the following example – assume that the data points given below belong to 4 distinct classes -
Let’s check out how the predicted classes changes as per the value of k:
It's very crucial to evaluate an absolute k value. If the value is low, the model is more specific and not generic well. Also inclined to be perceptive toward the noise. The Nearest Neighbors model achieves great accuracy on the training set but will poorly predict new, earlier unperceived data points.
Thus, we probably end up with an overfitting regression model. On the contrary, if the value of k is exceedingly significant, the model is too generic and a bad predictor on both trains as well as test sets. This condition is known as underfitting.
This ml algorithm is straightforward and easy to explicate. It doesn’t make any prediction so it could be installed in non-linear activities. This model becomes too slow when the number of data points increases because this model requires saving each and every data point. It's not memory-efficient. Another drawback of kNN is that it's susceptible to outliers.
6. Decision Trees
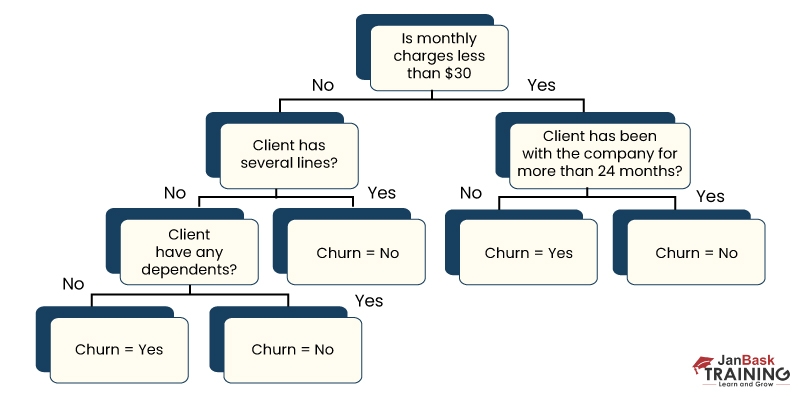
Decision tree develops upon repetitively asking questions to separate data or partition data. Its simple to envision the partitioning data using a graphical representation of a decision tree.
Above is a decision tree to forecast client churn. The first segregation is in accordance with the amount of the monthly charge. Then the machine learning algorithm keeps on asking questions to individual class labels. The questions tend to become more precise as the decision tree gets deeper.
The objective of this ml algorithm is to improve the predictiveness as much as feasible as every partitioning in order that the model continues to gain information regarding the dataset.
Arbitrarily dividing the features abstains us typically from giving us valuable insights within the dataset. Splits that lead to an increase in the purity of nodes are considered highly informative. The pureness of a node is inversely proportionate to the distribution of various classes under that node.
The questions to be asked are selected in such a manner that they increase the purity or decrease the impurity. How many questions can you ask? When should you stop? When is the decision tree enough to resolve classification issues?
The solution to all these questions takes us to a most prominent concept in ml – “Overfitting.” The decision tree model can continue asking questions unless and until each and every node becomes pure.
But having said that, it would be too generic a model and won’t generalize as well. It accomplishes higher precision using a train set but performs poorly on the new train set, earlier unperceived data points that show overfitting.
The depth of the decision tree is handled by the max_depth variable for the corresponding algorithm in scikit-learn. This ml algorithm usually doesn’t require to be normalized or scale features. Its also convenient to work on a combination of feature data types such as continuous, categorical, and binary.
On the other downside, it's liable to overfitting and must be assembled to generalize well.
7. Random Forest
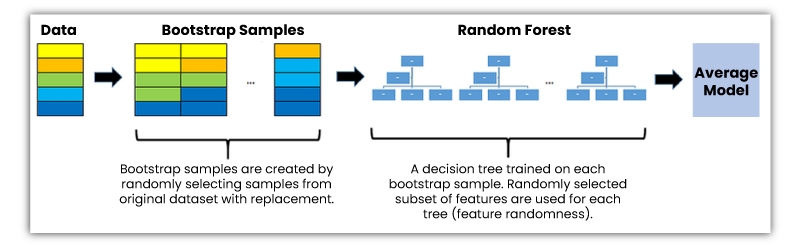
This ml algorithm is an assemblage of numerous decision trees. With the help of bagging, random forests are created where decision trees are utilized as parallel estimators. When utilized for classification issues, the outcome depends on the plurality vote of the outputs obtained from every decision tree.
For regression, the forecast of a leaf node is the midmost value of the target values within that leaf. Random forest regression receives the midmost value of the outcomes from decision trees.
This algorithm minimizes the threat of overfitting, and the precision is relatively higher as compared to a single decision tree. Additionally, decision trees within a random forest are executed simultaneously so that the time doesn’t become a blockage.
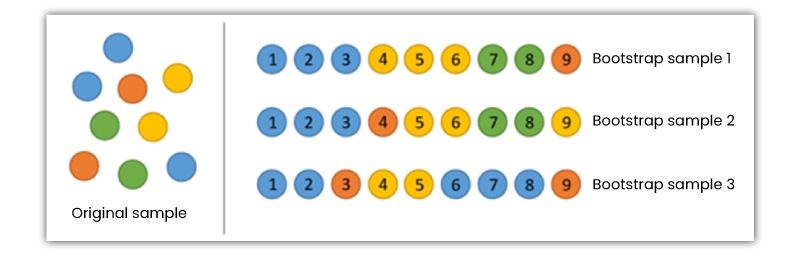
The accomplishment of a random forest is mainly based on making use of irrelevant decision trees with bootstrapping and feature randomness.
So, what is Bootstrapping?
It means randomly choosing samples from the train data sets using replacement, which are called bootstrap samples.
Bootstrap samples (Figure source)
Feature randomness can be accomplished by choosing features randomly for every decision tree within a random forest. Using the max_features parameter, the no. of features utilized for each decision tree within a random forest could be controlled.
Feature randomness
It is an extremely precise model for several types of problems and doesn’t need normalization or scaling. But having said that, it's not the best choice for multi-dimensional data sets, i.e., text classification as compared to Naïve Bayes.
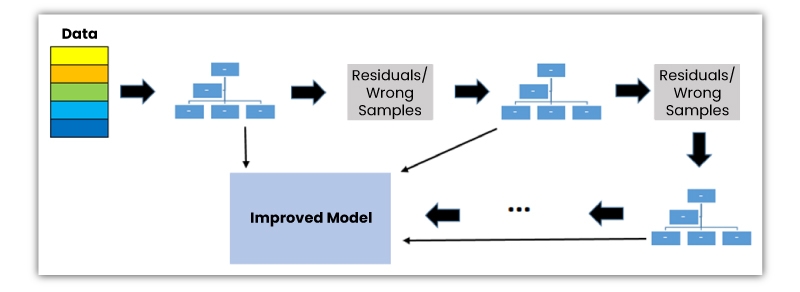
8. Gradient Boosted Decision Trees (GBDT)
It is a composite algorithm that makes use of boosting techniques to join separate decision trees. The meaning boosting is merging a learning algorithm in sequence to accomplish a solid learner from a number of the successively connected weak learner.
Speaking of GBDT, weak learners are decision trees, and every decision tree tries to reduce the errors of the earlier tree. Decision trees in boosting are weak learners, but combining several decision trees in sequence and making each tree focus on the errors from the earlier one helps make boosting a very effective and precise model.
Contrary to bagging, boosting doesn’t include bootstrap sampling. Each time a new decision tree gets added, it blends into an altered version of starting data set.
As decision trees are combined sequentially, boosting algorithms understand slowly. In arithmetical learning, the models which learn slowly produce better results.
An error function is utilized to ascertain the residuals. Another example of machine learning algorithm is MSE (Mean Squared Error) which could be utilized for regression analysis, and log loss, i.e., logarithmic loss, could be utilized for classification activities.
It should be noted that ongoing trees within the model won’t change when any new decision tree gets added. The newly added decision tree best fits the residuals from the existing model.
Two of the most crucial hyperparameters for the GBDT algorithm include - Learning rate and n_estimators.
The learning rate is noted as α, which basically means how fast a model can learn. Every new decision tree changes the overall model. The Learning rate regulates the extent of changes.
N_estimator is the no. of trees utilized in the model.
If the Learning rate is low, training more trees will be essential. But having said that, we must be very particular about choosing the number of trees. It could create a significant risk of overfitting with the help of excessive trees.
This machine learning algorithm is very effective for both classification and regression activities and offers highly precise predictions as compared to the random forests algorithm. It can control diverse features and doesn’t require any pre-processing.
This algorithm needs cautious tuning of hyperparameters to avoid the model being overfitted. It is also so strong that numerous upgraded versions of it have been installed, like XGBOOST, LightGBM, etc.
Understanding Overfitting -
A significant difference between random forests and GBDT is the no. of decision trees utilized in the model. When the number of trees in random forests increases, it doesn’t lead to overfitting. After some time, the correctness of the model doesn’t increase by including more trees. Still, it doesn’t get negatively affected by adding extra trees.
You don’t want to include irrelevant no. of trees because of computational reasons, but still, there’s no chance of overfitting related to the no. of trees in random forests. But having said that, the no. of decision trees in GBDT is highly critical with reference to overfitting.
Including multiple trees will lead to overfitting; therefore, it's necessary to cease adding decision trees at one point.
9. K-Means Clustering
It is a method to categorize data point sets in such a way that the same data points are combined together. Hence, the K-Means Clustering algorithm search for similarities or differences between data points.
It is an unsupervised learning algorithm method therefore, there’s not a single label related to data points. These ml algorithms try to identify the primary structure of the data. It isn’t classification.
Data points or observations in a classification activity have labels. Every data point or observation is classified as per similar measurements. These ml algorithms attempt to model a relationship between features or measurements on data points and their allotted class. After that, the model forecasts the class of new data points/observations.
This ml algorithm aims to divide data into k clusters in such a way that data points in the similar cluster are the same and data points in the dissimilar clusters are poles apart. Hence, it's a partition-based clustering algorithm technique. The resemblance of two points is calculated by the distance between them.
This ml algorithm tries to reduce the distances inside a cluster and increase the distance between various clusters. This algorithm isn’t capable of evaluating the no. of clusters. We must state it when building a KMeans object that might be a challenging activity.
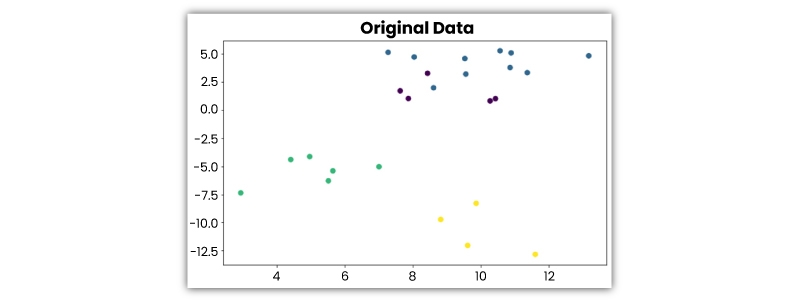
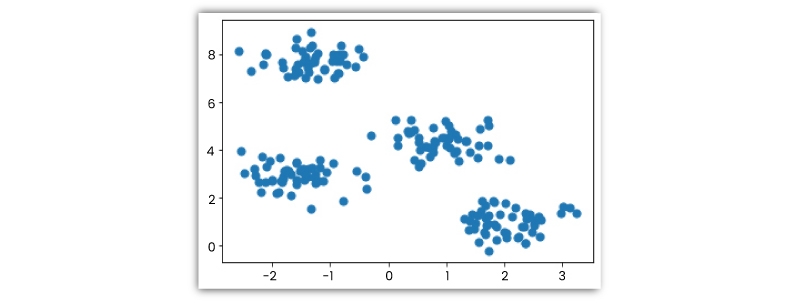
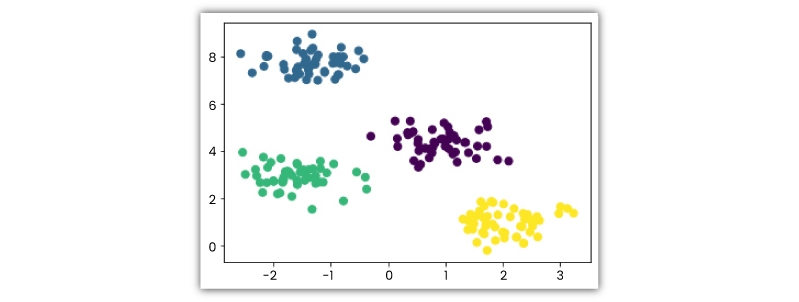
Look at the following 2-D visualization of a dataset -
It could be categorized into 4 different clusters as follows -
The real-world datasets are far more complex, wherein clusters aren’t segregated clearly. But having said that, the ml algorithm operates in a similar fashion. K-means is a repetitive procedure. It’s developed on an algorithm - expectation-maximization.
Once the number of clusters has been determined, it operates by performing the following steps
- Arbitrarily choose the center of cluster or centroids for every cluster.
- Evaluate the distance of all data points to the cluster's center.
- Allots data points to the nearest cluster.
- Identifies the new center of a cluster of every cluster by taking the mean of overall data points inside the cluster.
- Repeat steps 2,3 and 4 unless and until all data points connect and the centers of the cluster stop moving.
The K-Means Clustering algorithm is pretty fast and straightforward to explicate. It’s also capable of choosing the positions of the earlier centers of clusters in a bright way which speeds up the connections.
One threat with the k-means algorithm is that the no. of clusters should be preestablished. It isn’t capable of guessing how many clusters exist inside the data. And k-means clustering algorithm won’t be an excellent choice if there are a non-linear structure partitioning groups in the data.
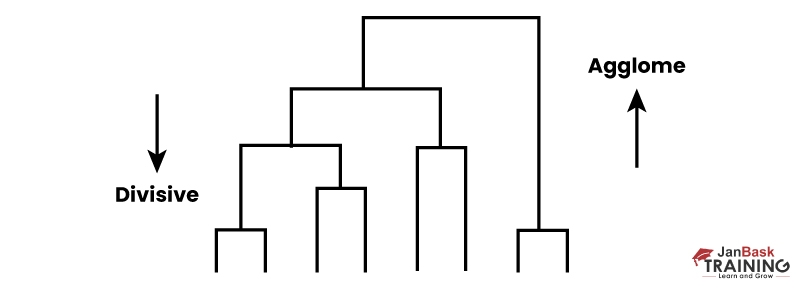
10. Hierarchical Clustering
It means developing a tree of clusters using repetitive grouping or partitioning data points.
The two types of hierarchical clustering include -
- Agglomerative clustering
- Divisive clustering
One key advantage of hierarchical clustering is that it's unnecessary to mention the no. of clusters (Still, we can).
Agglomerative clustering is a type of upside-down approach. Every data point is believed to be a distinct cluster in the beginning. Then the same clusters are combined repetitively.
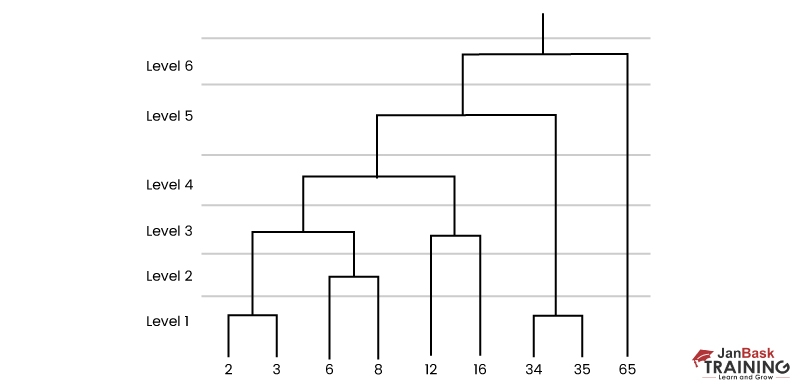
The above figure is referred to as a dendrogram, a diagram showcasing a tree-based method. In this clustering, dendrograms are utilized for visualizing the relationship between clusters.
Another major importance of hierarchical clustering is that we don’t need to mention the no. of clusters previously. regardless of it, it's not clever to connect all data points in one cluster. We must stop connecting clusters at one point.
Scikit-learn offers 2 options for it
- Stop after a particular no. of clusters are reached (n_clusters)
- Set a starting value for linkage i.e. distance_threshold. In case the distance between 2 clusters is more than the threshold value, then the clusters won’t merge.
Divisive Clustering isn’t used regularly in actual life. Therefore, we’ll be explaining it in brief:
A straightforward explanation is that this ml algorithm is the opposite of agglomerative clustering. We begin with one huge cluster containing all the data points and then these data points are partitioned into various clusters, which is an up-to-bottom approach.
A Hierarchical clustering consistently produces similar clusters. K-Means clustering might result in diverse clusters based on how the center of the cluster i.e. centroids, started off. Despite that, it's a slower ml algorithm as compared to K-Means clustering.
Hierarchical clustering takes a lot of time to execute, mainly for big data sets.
11. DBSCAN Clustering
Hierarchical and Partition-based clustering methods are quite effective with typically shaped clusters. But having said that, when it comes to arbitrarily shaped clustering or finding outliers, density-based methods are highly effective.
Arbitrarily-shaped Clusters
DBSCAN represents density-based spatial clustering of apps with noise. It's capable of finding arbitrarily-shaped clusters, along with clusters with noise, for example, outliers.
The major idea behind this clustering is that a data point is part of a cluster if it is near several data points from that specific cluster.
2 Major parameter of DBSCAN is
- eps: It's the distance that states the neighborhoods. Two data points are treated as neighbors if the distance among them is not greater than eps.
- minPts: It’s the min. No. of data points to define a cluster.
Depending on these 2 parameters, data points are categorized as core points, border points, or outliers -
- Core point: A point is considered a core point if there are at least minPts no. of points along with the data point itself in its neighboring area, including radius eps.
- Border point: A point is considered a border point if its reachable from a core point, and there are lower than minPts no. of points inside its neighboring area.
- Outlier: A point is considered an Outlier if it's not a core point and not reachable from any core points.
DBSCAN algorithm doesn’t need to mention the no. of clusters previously. It's powerful to outliers and capable of detecting the outliers.
In a few cases, evaluating a suitable distance of eps or neighborhood isn’t easy, and it needs knowledge of the domain.
12. Principal Component Analysis (PCA)
Its a dimensionally reduction algorithm that fundamentally acquires new features from existing ones by commensurating as many details as possible. It's an unsupervised learning algorithm. Still, it’s also mostly utilized as a pretreating step for supervised learning.
This ml algorithm acquires new features by identifying the relationships between features inside a dataset.
Important Note: PCA algorithm is a linear dimensionally reduction algorithm, and also, there are non-linear methods available.
The objective of the PCA algorithm is to interpret the difference inside the real dataset as quickly as possible with the help of fewer features or columns. The newly obtained features are referred to as principal components.
The sequence of principal components is evaluated as per the fraction of variance of the real dataset they describe. These principal components are linear combinations of the original dataset’s features.
The benefit of this ml algorithm is that a substantial amount of variance of the actual dataset is kept with the help of a much fewer no. of features than the actual dataset. The principal components are systematized as per the quantity of variance they explain.
13. XGBoos
It is a decision tree algorithm that makes use of a Gradient Boosting framework that is created as a research project at Washington University. It’s the most prominent Gradient Boosting R package and has been used widely in state-of-the-art industrial applications and dataset competitions.
This algorithm also stands for “Extreme Gradient Boosting,” an advanced distributed gradient boosting library developed to be more effective, resilient, and transferable than gradient-boosted decision trees.
The standard XGBoost features include standardized learning, which helps smoothen the final accomplished weights to prevent model overfitting. Also, the decision tree accumulation can’t be enhanced with the help of conventional optimization techniques like Euclidean space, so the model is made ready in an add-on way.
XGBoost like an open-source application pertains to an expansive collection of tools within the Deep or Distributed Machine Learning Community on GitHub.
What is it meant for?
As per the researchers who invented it, the most prominent aspect of this ml algorithm is its flexibility and speed, with a system that performs greater than 10 times faster as compared to current well-known solutions on a single machine when allowing data scientists to manage a couple of hundred million examples on a conventional desktop.
14. GBM (Gradient Boosting Machine)
Its an original boosting framework for decision trees brought in 2001 by a professor of statistics from Stanford University, Jerome H. Friedman; and also referred to as Multiple Additive Regression Trees (MART) and Gradient Boosted Regression Trees (GBRT).
This ml algorithm finds out weak learners with the help of gradients inside the loss function (y=ax+b+e, where ‘e’ stands for an error term).
The loss function evaluates how exceptional a model’s coefficients are at connecting with the core data. Simply put, a loss function showcases the discrepancies between actual and predicted values.
15. LightGBM
It is another free and open-source Gradient boosting framework for decision tree algorithms, which Microsoft earlier created. This machine learning algorithm has numerous advantages, same as the XGBoost ml algorithm, containing sparse organization, parallel training i.e., training various layers of a model on diverse GPUs to minimize the training time, several loss functions, regularization, which is a method used for tuning functions, and early stopping.
The significant difference between XGBoost and LightGBM resides in the development of decision trees. LightGBM doesn’t grow a decision tree row by row as the majority of other implementations do. Instead, it selects the terminal node or leaf, which it assumes to catapult reduction in loss, which is an important goal of Gradient Boosting.
16. CatBoost
This is yet another open-source gradient boosting library for decision trees, designed and developed by Yandex researchers and engineers, which is a Russian-Dutch internet company. This library is utilized for search, recommendation systems, personal assistance, self-driving cars, weather prediction, and a number of other activities at Yandex and other companies.
Cloudflare, a website security company, made use of this ml algorithm to develop a machine learning model that would prevent credential stuffing bots, i.e., cybersecurity attacks that tries to log into and take control of a user’s account by invading the password forms with the help of initially stolen credentials. It offers excellent results using the default parameters. Therefore, there’s no requirement to dwell too much time on parameter tuning.
You could also utilize non-numeric factors rather than needing to pre-process the data and convert it into numbers.
Why Doing A Machine Learning Course Is Beneficial?
Indeed, machine learning is an excellent career path. As per a recent report by Indeed, Ml Engineer is a top job in the US with respect to salary, advancement of postings, and regular demand. Learn more about the machine learning engineer job description so as to pursue a career in it.
The no. of positions for Machine Learning Engineer has grown to approximately 350 percent, with the base salary surpassing $140,000.
If you’re enthusiastic about data science with ml, automation, algorithms, etc., then machine learning is your best career path. Your day will be jam-packed with a huge amount of raw data, deploying ml algorithms to process that raw data and then automatizing the optimization process.
Another reason why pursuing a career in machine learning is interesting? Because there are several machine learning career paths that ml professionals could select inside the industry. Having a machine learning background can get you a well-paying job like Machine Learning Engineer, Data Scientist, NLP Scientist, BI Developer, etc.
These job positions are so worthwhile because individuals with ml skills are in great demand and have low supply.
The machine learning online certification training course by JanBask Training will help you grasp the ml concepts to develop vital skills required to excel in your career graph. You’ll also gain end-to-end practical experience with machine learning concepts such as supervised and unsupervised learning algorithms, regression, and lots more.
Which Machine Learning Algorithm Should You Use?
When selecting a machine learning algorithm, always consider these factors - accuracy, training time, and convenience. The majority of the users put accuracy first, whereas freshers try to concentrate on ml algorithms that they know best.
When given a dataset, the foremost thing to consider is - how to get results, regardless of what those outcomes could look like. Freshers try to select ml algorithms that are simple to deploy and give results quickly.
This functions properly so long as it's just the first stage in the process. When you get few results and become acquainted with data, you might devote more time to more complicated ml algorithms to build your understanding of the data, thus, further enhancing the results.
Even at this step, the best al algorithms may not be the methods that have obtained the highest accuracy because an ml algorithm mainly needs careful tuning and immense training to get outstanding results.
How Learning The ML Algorithm Can Boost Your Ml Skills?
Even though ml is evolving continuously using several of the latest technologies, it has been utilized in different sectors.
Machine learning algorithms are necessary because they provide businesses with a view of the latest trends in consumer behavior and operational business standards and also provide support in the development of advanced products.
A majority of today’s top companies, like Facebook, Google, Uber, etc., have made machine learning a significant part of their tasks. ML has also become a critical competing determiner for a number of businesses.
Machine learning has many functional applications that bring real business benefits like saving time and money. Simply put, it has the potential to impact your organization’s future drastically. Especially we can see a considerable impact taking place inside the customer support sector, in which ml is facilitating customers to complete things more easily and efficiently.
Conclusion
As of now, I’m confident that you must have got an idea of frequently used machine learning algorithms types through this comprehensive list of machine learning algorithms. Our sole intention behind writing this blog is to help you get started with it right away.
Are you keen to master ml algorithms? then start straight away. Take up issues, grow a physical understanding of this process, deploy codes, and enjoy the process!
Key Takeaways
- We’re now well-acquainted with a few of the best Machine Learning algorithms used in the industry.
- We learned what are the main types of Machine Learning algorithms.
- We learned how to choose the right Machine Learning algorithm.
If you’ve any queries regarding this demanding machine learning career or a list of machine learning algorithms, get in touch with our experts at JanBask Training today!
FAQs
1. Which ml algorithm is most commonly used in machine learning?
|Ans:- While the best machine learning algorithm is mostly based on the issue, Gradient Boosted Decision Trees are the most commonly used machine learning algorithms in order to balance performance and explicability.
2. What is the difference between supervised and unsupervised ML algorithms?
|Ans:- A significant difference between the supervised and unsupervised learning models is that, in supervised learning, the labels related to the features are given, whereas, in unsupervised learning, no labels are mentioned for the model.
3. What are the main 3 types of Machine Learning algorithms?
|Ans:- The 3 significant types of ML models are based on Supervised Learning, Unsupervised Learning, and Reinforcement Learning.
4. What is the objective of Machine Learning online?
|Ans:- The major objective of online machine learning training is:
- To give you an experience similar to offline classrooms & save you from the daunting daily traveling daily to physically located training classes by exempting expenses and expending time as well as energy.
- To teach you to complete the Machine Learning discipline by covering all the concepts, skills & techniques that this job role demands.
5. What skills will I learn through this Machine Learning online?
|Ans:- If you are enthusiastic to know what skills & knowledge we deliver in detail, then sign up for our brief Machine Learning demo class. Here’s all that you’ll learn:
- Introduction to Machine Learning & Python
- Supervised Learning
- Unsupervised Learning
- Time Series Forecasting
- Statements Loops
- A regular expression, Exceptional Handling & Debugging
6. What all topics will be covered in the beginner-level Machine Learning training online course?
|Ans:- Our Machine Learning training course begins with the fundamentals of the Machine Learning discipline. After the first week, you’ll be taught:
- Overview of Machine Learning.
- Machine Learning types
- What are the features of Machine Learning?
- Machine Learning Categories & Technique
- Automation tools in Machine Learning.
- Analyze data using a machine learning algorithm.
- Overview of Python.
7. Can I pay the course fee in installments?
|Ans:- We aim to provide industry-specific learnings that help candidates establish satisfying careers. We also know that the capacity of every learner isn’t the same; that’s why we’ve kept flexible fee payment options.
If you find it uncertain or difficult to pay the lump-sum amount, you can opt for the “Payment in Installment” option.
8. What job roles can I look forward to in my future path of a Machine Learning Career?
|Ans:- Here are some of the top-notch industry-demanded job roles in the ML sector that you must aim for through our comprehensive Machine Learning course online
- Data Scientist
- NLP Scientist
- Business Intelligence Developer
- Human-Centered Machine Learning Designer
- Data Analyst
- Video Game Programmer
- Robotics Programmer
- Software Engineer
- Machine Learning Researcher
9. What essential skills should I pursue in a Machine Learning job?
|Ans:- For this Machine Learning centric job role, the individuals are required to master the following skills:
Technical skills
- Applied Mathematics
- Neural Network Architectures
- Physics
- Data Modeling and Evaluation
- Advanced Signal Processing Techniques
- Audio and Video Processing
- Natural Language Processing
- Reinforcement Learning
Personality Skills
- Critical thinking
- Systematic, Analytical & logical thinking
- Communication & Collaboration Skills
- Detail-oriented
- Result-driven
- Insightful/intuitive
- Problem-solving mentality
- Writing skills
10. What are the typical roles & responsibilities of Machine Learning professionals?
|Ans:- Here are some of the roles and responsibilities that Machine Learning professionals are required to perform.
- To write, test, and deploy code, design machine learning systems, and extend existing ML libraries and frameworks.
- To research and implement appropriate ML algorithms and tools and develop machine learning applications as per custom needs.
Trending Courses
Gen AI
- Introduction to Generative Models
- Generative Adversarial Networks (GANs)
- The Art and Science of Prompt Engineering
- MLOps: Deploying Generative AI Models
Upcoming Class
8 days 11 Aug 2026
Agentic AI
- Introduction to Agentic AI
- Multi-Agent Setup with LangGraph Context Handling in Graphs
- Performance Benchmarking Advanced Prompt Engineering for Agents
- Agent Behavior Tuning Project and Mock Session
Upcoming Class
4 days 07 Aug 2026
AI in Automation Testing
- Intro to AI & ML in Automation
- Playwright + JS (JavaScript) + API Tesng
- Automaon with Using ChatGPT & Playwright MCP server
- GitHub Copilot, AI Tools & Interview preparation
Upcoming Class
-0 day 03 Aug 2026
Cyber Security
- Introduction to cybersecurity
- Cryptography and Secure Communication
- Cloud Computing Architectural Framework
- Security Architectures and Models
Upcoming Class
4 days 07 Aug 2026
Data Science
- Data Science Introduction
- Hadoop and Spark Overview
- Python & Intro to R Programming
- Machine Learning
Upcoming Class
11 days 14 Aug 2026
QA
- Introduction and Software Testing
- Software Test Life Cycle
- Automation Testing and API Testing
- Selenium framework development using Testing
Upcoming Class
-0 day 03 Aug 2026
Salesforce Service Cloud
- Industry Knowledge Introduction
- Adoption and Maintenance
- Interaction Channels Introduction
- Integration and Data Management
Upcoming Class
11 days 14 Aug 2026
AWS
- AWS & Fundamentals of Linux
- Amazon Simple Storage Service
- Elastic Compute Cloud
- Databases Overview & Amazon Route 53
Upcoming Class
8 days 11 Aug 2026


 Dec 05, 2024
Dec 05, 2024  5.6k
5.6k


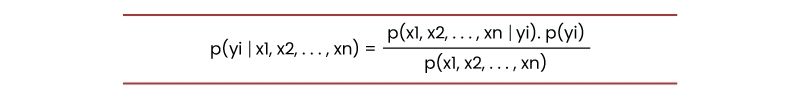

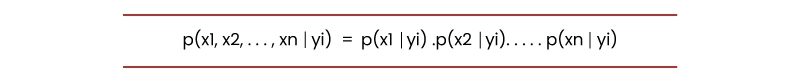

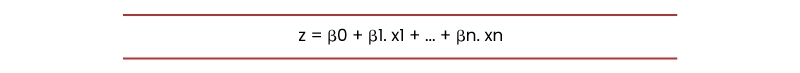
 Bootstrap samples (
Bootstrap samples (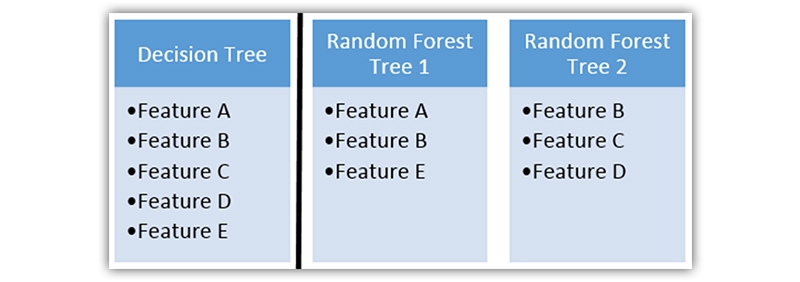



















![How to Write Machine Learning Resumes to Get Interview Calls [Free Samples] image](https://assets.janbasktraining.com/blog/uploads/images/Top_10_Tips_to_Crack_Growth_Opportunities_at_Work_1.jpg)
 Dec 06, 2021
Dec 06, 2021 8.4k
8.4k

Emilio Davis
Awesome compilation on machine learning algorithms!! Thank you.
JanbaskTraining
Thank you for your feedback
Knox Miller
Thank you for this very useful and excellent compilation of machine learning algorithms. I’ve already bookmarked this page.
JanbaskTraining
Thank you for your feedback
Adonis Smith
Straight, Informative, and effective blog on ml algorithms list!!
JanbaskTraining
Thank you for your feedback
Aidan Johnson
Very useful information in just one blog. Can anyone help me to run the codes in R? Help is appreciated.
JanbaskTraining
Thank you for reaching out to us! Drop your email id here, and our experts will get back to you.
Kaden Brown
Great Article... Helps a lot as a fresher in Machine Learning.
Paul Wilson
Very good article. Thanks! But one simple point that you can explain what is the reason for taking the log(p/(1-p)) in Logistic Regression?
JanbaskTraining
Thank you for reaching out to us! Drop your email id here, and our experts will get back to you.
Omar Moore
I‘ve taken an ML class, but I appreciate this real-world analog.
JanbaskTraining
Thank you for reaching out to us! Drop your email id here, and our experts will get back to you.
Brian Taylor
This is a superb blog on the ml algorithms list, with good examples of machine learning algorithm and codes, which are helpful. Just can you add Neural Network in simple terms with examples and code?
JanbaskTraining
Thank you for your feedback
Louis Anderson
This is a great resource on ml algorithms list and the product of a lot of work.
JanbaskTraining
Thank you for your feedback
Caden Thomas
Thank you. Very nice and helpful article on machine learning algorithms.
JanbaskTraining
Thank you for your feedback