
 Mar 21, 2018
Mar 21, 2018  146.1k
146.1k

31
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Hadoop Blogs -
Hadoop developers are very much familiar with these two terms, one is YARN and other is MapReduce. Though some newbies may feel them alike there is a huge difference between YARN and MapReduce concepts. Where one is an architecture which is used to distribute clusters, so on another hand Map Reduce is a programming model.
This article is written to give you a detailed explanation of both the concepts and a short comparison between the two. YARN is also known as dummy resource scheduler and MapReduce involve a process to decide that what should be done with any resource?
YARN is included in Hadoop 2.0, it is basically used to separate processing components and resource management process. YARN is given to provide an advantageous platform or an option for distributed processing layer, used in earlier versions of Hadoop. YARN is known as:
In the above-shown YARN architecture, there is a global resource manager which runs as a master daemon, it tracks the total live nodes and resources on the cluster and manages the allocation task of these resources. It works in a multi-tenant, secured, and shared manner. 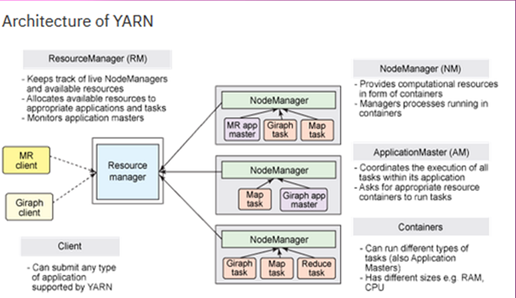 If we talk about the complete process of its execution then on submission of an application, the lightweight process ApplicationMaster coordinates execution of the applications. The task of this Application Manager is to monitor, restarting, running, and slowing the tasks. All tasks related to its applications are controlled by the Node Manager.
If we talk about the complete process of its execution then on submission of an application, the lightweight process ApplicationMaster coordinates execution of the applications. The task of this Application Manager is to monitor, restarting, running, and slowing the tasks. All tasks related to its applications are controlled by the Node Manager.
Node Manager is an efficient version of Task Tracker, even it has dynamically created resource containers. Size of the container may vary from one application to another and it depends on the certain factors like size of memory, CPU, and network I/O. Nowadays MRv1 runs on the top of YARN.
Read: An Introduction to the Architecture & Components of Hadoop Ecosystem
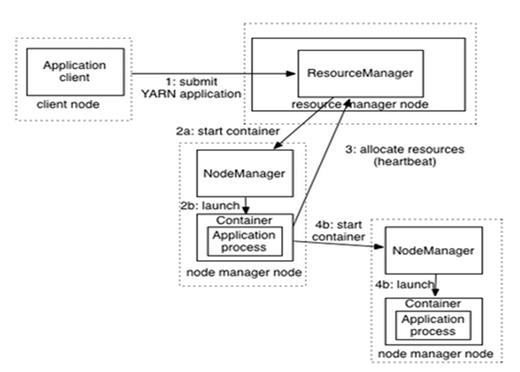 As per above diagram, the execution or running order of an Application is as follow:
As per above diagram, the execution or running order of an Application is as follow:
MapReduce framework is used to write applications which can process a large amount of structured and unstructured data. The data processed by these applications are stored in HDFS. MapReduce is basically used for batch processing which may include petabyte and terabyte of Apache Hadoop data. MapReduce offers following listed benefits:
| Listicle Benefits | Description |
| Simple to Use | Since in MapReduce the developers can write the application in any language like Java, C, C++ or Python, it is easy for developers to run Map-Reduce jobs. |
| Scalable Applications | MapReduce can process petabytes of data, which is stored on HDFS cluster. |
| Fast | MapReduce can solve the problems which may take a number of days in solving and even they can be solved by MapReduce in several hours or minutes. |
| Easy to Recover | If in case of any failure copy of data is unavailable then in MapReduce the data can be taken from another machine, which will have a similar copy with same key/value pair and it can then be used to solve sub-task. JobTracker is used to keep track of these problems. |
| Minimal data movement | In MapReduce, the complete process of computation is moved to HDFS and the task of processing can occur on physical nodes itself where the data resides. In this way, network I/O patterns are also reduced and Hadoop processing speed is increased significantly. |
MapReduce is the core building block of Hadoop framework, it allows parallel and distributed processing of data in huge amount. It consists of the following tasks and components:
MapReduce has the following advantages that you should know –
1). Parallel Processing In MapReduce, the full job is divided into multiple nodes and they are processed in a parallel manner simultaneously. So, it works basically in divide and conquers manner and the data is processed among multiple machines in a parallel manner. As the processing is done in a parallel manner, so the processing time is reduced drastically.
Read: Scala VS Python: Which One to Choose for Big Data Projects
2). Locality of Data Instead of moving data for processing, in MapReduce, the complete process is moved to each node. As now the data is available in a huge amount so it may become difficult to move it from one place to another and therefore this technique is considered as beneficial and the best one.
It offers the following advantages:
It is quite cost-effective to move processing unit from one node to another rather than moving data.
After discussing YARN and MapReduce, let’s see what are the differences between YARN and the MapReduce?
As listed, above are the different components used to process any task or job in YARN and MapReduce.Though they are completely separate concepts, the user can easily see and check the advantages of both the concepts which are used in data processing.
Read: A Beginner's Tutorial Guide For Pyspark - Python + Spark
Scalability. availability, utilization, and multitenancy are a few other factors to compare the performance of these systems. Where YARN is just a Resource manager so MapReduce is the process to distribute the data processing task and to manage the complete task. A set of resources is used in MapReduce for the complete task. Resource allocation is a subpart of MapReduce jobs.
Final Words:
Today, Hadoop is a huge platform and is used by many organizations to process the big or huge amount of data. MapReduce and YARN are just two concepts which are part of huge data processing.
Hadoop developers get many advantages of this platform and the complete architecture become quite simple and easier due to its processing way and the ability to process the huge amount of data.
Hadoop data processing involve many steps to process data YARN and MapReduce processes make the complete processing faster and efficient. As the use of parallel and distributed processing makes the task easier.
Read: Top 10 Reasons Why Should You Learn Big Data Hadoop?
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Hadoop Course
Interviews









 Oct 13, 2017
Oct 13, 2017 616.5k
616.5k

 616.5k
616.5k