 Christmas Offer : Get Flat 35% OFF on Live Classes + $999 Worth of Study Material FREE! - SCHEDULE CALL
Christmas Offer : Get Flat 35% OFF on Live Classes + $999 Worth of Study Material FREE! - SCHEDULE CALL
Christmas Offer : Get Flat 35% OFF on Live Classes + $999 Worth of Study Material FREE! - SCHEDULE CALL
Are you longing for a successful career in Microsoft SQL server? As a career in SQL has seen a rising surge in the last few years, you can also join this promising community. Data Structures and Query Language (SQL) is the standard language that almost every relational database management system uses. So, if you’re preparing for the upcoming SQL interview. In that case, the following are the most frequently asked SQL interview questions and answers for freshers, intermediate, and experienced professionals, along with top SQL interview questions and answers related to developers and PostgreSQL.
These interview questions and answers will come in handy whenever you need them. These best SQL interview questions and answers have been customized to help you familiarize yourself with the questions you may encounter during your interview.
This blog is a one-stop source that allows you to easily leverage full benefits and prepare well for your SQL interview. Let’s check out the basic SQL interview questions with answers for freshers.
We’ll start with basic questions and gradually move towards more advanced ones to take the lead. If you’re a skilled professional, these SQL server interview questions and answers help you run through your skills.
What does SQL stand for? SQL refers to “Structured Query Language”, a typical programming language often utilized for relational database management systems and a broad range of data processing jobs.
The initial SQL database was first designed in 1970. This database language is utilized for different tasks like database formation, deletion, retrieval, and updations. It’s sometimes also pronounced as “sequel.”
SQL could also be utilized to manage structured data consisting of entities and relationships among variables.
A “Database” is a system that assists in gathering, storing, and retrieving data. It could be complex, and these databases are created with the help of design and modeling methods.
The term “DBMS” represents Database Management System responsible for creating, modifying, and maintaining databases.
The term “RDBMS” refers to a Relational Database Management system, which stores data by means of a collection of tables, and the relationship between them can be described using the common fields in those tables.
Following is the command to create a table in SQL:
CREATE TABLE table_name ( column1 datatype, column2 datatype, column3 datatype, .... )
);
You can start off by providing the keywords CREATE TABLE, and then we’ll assign a name to the table. Thereafter we’ll list out all the columns, including their data types.
For instance, let's create an employee table:
CREATE TABLE employee ( name varchar(25), age int, gender varchar(25), .... );
You can delete a table in SQL using 2 commands - DROP and TRUNCATE.
The DROP [table_name] command completely deletes the table from the database. Here’s the command -
DROP TABLE table_name;
This command, as mentioned earlier, will completely delete the entire data present in the table, including the table itself.
But, if you wish to delete just the data stored in the table and not the table itself, then use the TRUNCATE command as follows
DROP TABLE table_name;
Following is ths command to change a table name in SQL:
ALTER TABLE table_name RENAME TO new_table_name;
Begin by providing the keywords ALTER TABLE, followed by the original table name, thereafter give RENAME TO and finally, provide the new table name.
For instance, if we wish to change the “employee” table to “employee_information”, here’s the command:
ALTER TABLE employee
RENAME TO employee_information;
You can use the DELETE command to delete the existing rows from the table -
DELETE FROM table_name
WHERE [condition];
Begin by giving the command “DELETE FROM, followed by the existing table name, then use the WHERE clause and give the condition based on which you would like to delete a row.
For instance, suppose you would like to delete all the rows where the employee age is equal to 25; then the following command will be given-
DELETE FROM employee
WHERE [age=25];
As mentioned above, a “Database” is an SQL archive comprising several tables. Following is the command used to create a database in SQL -
CREATE DATABASE database_name.
SQL database normalization-1nf, 2nf, 3nf, 4nf is used for decomposing a bigger and more complex table into smaller and simpler ones. It helps in removing all the redundant data.
Normally, in a table, we might have a large amount of redundant data, which isn’t required, so it's better to divide this complicated data into several smaller tables containing just unique data.
First normal form [1NF]:
A table or relation schema is in 1NF if and only if:
Second normal form [2NF]:
A table or relation schema is said to be in 2NF if and only if:
Third Normal form [3NF]:
A table or relation schema R is said to be in 3NF if and only if:
As the name specifies, “Denormalization” is the opposite of “Normalization”; redundant data is added to accelerate complicated queries with many tables that require joining.
You can optimize the read performance of a table by adding or grouping redundant data copies.
Joins in SQL are used for joining rows from 2 or more tables, depending on related columns present between them.
Different Types of SQL Joins are as follows:
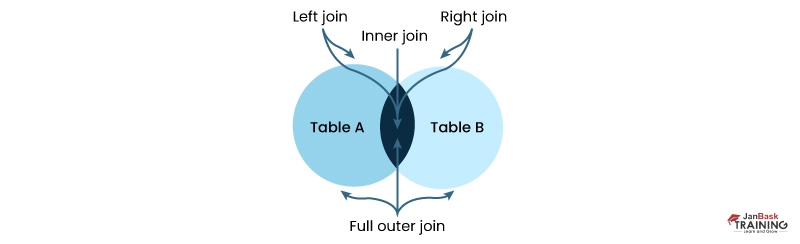
INNER JOIN:
It creates a new result table by joining the column values of two tables depending upon the join predicate. Its SQL query compares each row of Table 1 with each row of Table 2 to identify all the pairs of rows that satisfy the join predicate.
Here’s the syntax -
SYNTAX:
SELECT table1.col1, table2.col2,…, table1.coln FROM table1 INNER JOIN table2 ON table1.commonfield = table2.commonfield;
LEFT JOIN:
It returns all the values from the left table, including matched values from the right table or NULL in case of not matching join-predicate.
SYNTAX:
SELECT table1.col1, table2.col2,…, table1.coln FROM table1 LEFT JOIN table2 ON table1.commonfield = table2.commonfield;
RIGHT JOIN:
It returns all the values from the right table, including matched values from the left table or NULL values in case of no matching join-predicate.
SYNTAX:
SELECT table1.col1, table2.col2,…, table1.coln FROM table1 RIGHT JOIN table2 ON table1.commonfield = table2.commonfield;
FULL OUTER JOIN:
It combines the results of both left and right outer joins, and the joined table will have all the records from both tables and fill in NULLs for missing matches on both sides.
SYNTAX:
SELECT table1.col1, table2.col2,…, table1.coln FROM table1 Left JOIN table2 ON table1.commonfield = table2.commonfield;
Union
SELECT table1.col1, table2.col2,…, table1.coln FROM table1 Right JOIN table2 ON table1.commonfield = table2.commonfield;
SELF JOIN:
It joins a table to itself and for the time being, renames a minimum of one table in the SQL statement.
SYNTAX:
SELECT a.col1, b.col2,..., a.coln FROM table1 a, table1 b WHERE a.commonfield = b.commonfield;
This is how you can insert a date in SQL if the RDBMS is a MySQL database
INSERT INTO tablename (col_name, col_date) VALUES ('DATE: Manual Date', '2020-9-10');
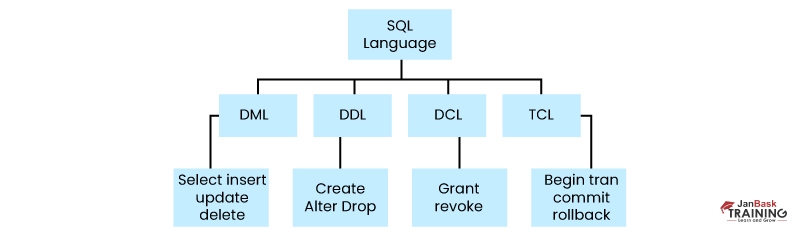
SQL queries are divided into four major categories. The top SQL commands are as follows:
Data Definition Language (DDL): These queries are created using SQL commands that could be used to state the structure of the database and modify it.
Data Manipulation Language (DML): These SQL queries are utilized in the manipulation of data in a database.
Data Control Language (DCL): These SQL queries manage the database's access rights and permission control.
Transaction Control Language (TCL): Is a set of commands that primarily manages the transactions in a table and the modifications done by the DML statements. It enables statements to be grouped together into logical transactions.
The crucial applications of SQL include:
The primary Key in SQL is a constraint in SQL. therefore, before comprehending what is a primary key, let’s first try to understand what is a constraint in SQL.
Constraints in SQL are the rules imposed on data columns on a table that are used to limit the data type that could be added to a table. These constraints could either be column level or table level.
Let’s have a look at the different types of constraints present in SQL:
|
Constraint |
Description |
|
NOT NULL |
It makes sure that a column can’t have a NULL value. |
|
DEFAULT |
Provides a default value for a column when none is specified. |
|
UNIQUE |
Makes sure that all the values in a column are not similar |
|
PRIMARY |
Distinctly identifies each and every row/record in a database table |
|
FOREIGN |
Distinctly identifies a row/record in any other database table |
|
CHECK |
It makes sure that all the values in a column fulfill certain conditions |
|
INDEX |
It is used for creating and retrieving data from the database instantly |
You could consider a Primary Key constraint in SQL a mixture of UNIQUE and NOT NULL constraints. In other words, if any column in a table is set as a primary key, then that specific column should not have any NULL values present, and all the values in all the columns should be unique.
Constrained in SQL are utilized for specifying some kind of data processing and restricting the data type that could be added to a database.
Default constraint:
This constraint is utilized for defining a default value for a column henceforth, it can be added to all new records if any other value is not specified.
For instance - if a default constraint is assigned to an E_salary column in the given table and set its value to 85000, then all the entries for this column should have the default value of 85000 unless and until any other value has been assigned at the time of insertion.
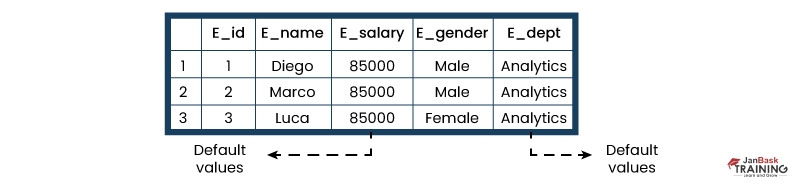
Now, let’s find out how to set a default constraint.
First, start by creating a new database and then add a default constraint to any of its columns.
Syntax:
create table stu1(s_id int, s_name varchar(20), s_marks int default 50)
select *stu1
Output:

Let’s add records.
Syntax:
insert into stu1(s_id,s_name) values(1,’ John’) insert into stu1(s_id,s_name) values(2,’ Carl’) insert into stu1(s_id,s_name) values(3,’Mathew’) select *from stu1
Output:

You can view tables in SQL by using the following command:
Show tables;
The term “Table” is referred to as organized data in the form of rows and columns. In other words, it is an accumulation of data in a table form.
The rows are referred to as tuples, and columns are referred to as attributes, and the no. of columns in a table is called a field. In a record, fields indicate the characteristics and attributes and consist of particular information related to the data.
primary key and unique key carry unique values, but a primary key can’t be a NULL value, whereas a unique key can. In a database, there can only be one primary key and multiple unique keys. Learn more about what is primary key in SQL here.
It is an attribute or a set of attributes that refer to the primary key of another table. Fundamentally, a foreign key is utilized to join together two tables -
Let’s create a foreign key for the following table:

CREATE TABLE Orders ( OrderID int NOT NULL, OrderNumber int NOT NULL, PersonID int, PRIMARY KEY (OrderID), FOREIGN KEY (PersonID) REFERENCES Persons(PersonID) )
SQL can be used to perform the following tasks:
Indexes in SQL help accelerate searching in a table. If there isn’t any index on a column in the WHERE clause, then the SQL server must flip through the complete tables and check every row to find the match, which might lead to slow operations in the big database.
Indexes are used to identify all rows matching with a few columns and then flip through just those data subsets to find the matches.
Syntax:
CREATE INDEX INDEX_NAME ON TABLE_NAME (COLUMN)
Following are the types of SQL server indexes:
Single-column Indexes: This index is created just for only one column of a table.
Syntax:
CREATE INDEX index_name
ON table_name(column_name);
Composite-column Indexes: This index is created for two or more table columns.
Syntax:
CREATE INDEX index_name ON table_name(column_name);
Unique Indexes: This index is used for maintaining the data integrity of a table, and it doesn’t allow multiple values to be added to the table.
Syntax:
CREATE INDEX index_name ON table_name (column1, column2)
Entities: An entity in SQL could be a person, place, thing, or any identifiable object for which data can be stored in a database.
For instance, in an organization’s database, employees, projects, salaries, etc., can be referred to as entities.
Relationships: A relationship between entities in SQL could be referred to as a connection between two tables or entities.
For instance, in a college database, the student and department entities are associated.
The term PL SQL refers to Procedural language constructs for Structured Query Language, which Oracle brought up to get a better of the restrictions of plain SQL. Therefore, PL SQL adds together procedural language way to plain SQL.
You should consider this because PL SQL is just for Oracle databases. If you do not have an Oracle database, you cannot work with PL SQL.
Using SQL, you’ll be able to make DDL and DML queries; using PL SQL, you can make functions, triggers, and other procedural constructs.
Different DBMS systems have different queries to view tables in SQL.
To view all the tables in MYSQL, you can use the following query -
show tables;
You can see all the tables in ORACLE using the following query:
SELECT
table_name
FROM
User_tables;You can see all the tables in SQL Server using the following query:
SELECT
*
FROM
Information_schema.tables;The term ETL refers to Extract, Transform, and Load, a three-step process that is required to begin by extracting the data from sources. Once we combine the data from various sources, we have raw data.
This raw data needs to be converted into a systematic format, which will appear in the second stage. And finally, we need to load this systematized data into tools that will help you to find insights.
SQL, i.e., Structures Query Language, isn’t something you can install. To deploy SQL queries, you’ll require an RDBMS. Different types of RDBMS are
Therefore, in order to deploy SQL queries, you’ll need to install any of these RDBMSs.
The UPDATE query in SQL comes under the Data Manipulation Language (DML) part of SQL and is utilized for updating the current data in the database.
UPDATE employees
SET last_name=‘Cohen’
WHERE employee_id=101;
The above example shows how to change the last name of the employee.
Renaming columns in SQL - with respect to the SQL server, it’s impossible to rename the column using ALTER TABLE command and use sp_rename.
Following are the four types of SQL Queries:
Let’s have a look at the various commands used under DDL and how to use function in SQL server:
|
Command |
Description |
|
CREATE |
Creates objects in the database |
|
ALTER |
Alters the structure of the database object |
|
DROP |
Deletes objects from the database |
|
TRUNCATE |
Removes all records from a table permanently |
|
COMMENT |
Adds comments to the data dictionary |
|
RENAME |
Renames an object |
SELECT region, COUNT(gender) FROM employee GROUP BY region;
Triggers can deploy DML with the help of INSERT, UPDATE, and DELETE statements. These triggers that consist of DML and identify other triggers for data manipulation are known as Nested Triggers.
With the help of BETWEEN in the where clause, it's possible to retrieve the Employee IDs of employees with salary >=30000 and <=10000.
SELECT FullName FROM EmployeeDetails WHERE EmpId IN (SELECT EmpId FROM EmployeeSalary WHERE Salary BETWEEN 30000 AND 10000)
“Order by 2” is legitimate when a minimum of 2 columns are used inside the SELECT statement. Therefore, this query will give an error because just one column is used in the SELECT statement.
The term OLTP refers to Online Transaction Processing, which is a class of software apps that are capable of assisting transaction-related programs. One of the most important attributes of an OLTP is its capability to manage concurrency.
It is the certainty of accuracy as well as consistency of data throughout its life cycle. It is an important facet in the design, deployment, and usage of any type of system that stores, processes, or retrieves data.
It also states integrity constraints to impose business rules on the data when added to an application or a table.
The term OLAP refers to Online Analytical Processing which is a class of software applications that are specified by a relatively small frequency of networked transactions. The queries are generally too complicated and contain a lot of assemblages.
Many times a user is required to identify a particular constraint information of a database. The following queries can be useful -
SELECT * From User_Constraints; SELECT * FROM User_Cons_Columns;
You can get a list of employees with the same salary using the following command -
Select distinct e.empid,e.empname,e.salary from employee e, employee e1 where e.salary =e1.salary and e.empid != e1.empid
The following are the alternatives for the TOP clause in SQL
1. ROWCOUNT function
2. Set rowcount 3
3. Select * from employee order by empid desc Set rowcount 0
It’ll give an Error. Because an operand data type NULL is invalid for the Avg operator.
The outcome of the cross-join is known as a cartesian product, which returns rows by joining each row from the first table with every row of the second. For instance, if you combine 2 tables containing 15 to 20 columns, the Cartesian product of those 2 tables would be 15 * 20 = 300 rows.
The database is composed of a number of different entities like tables, stored procedures, functions, and much more. To depict how these different types of entities interact, we’ll have to take the help of SQL schema.
Therefore, a schema can be considered a logical relationship between all the different types of entities in the table. Once we thoroughly understand a scheme, it can be helpful in various ways -
All in all, schema can be considered a blueprint for the table, which will present you with a complete picture of how various objects cooperate and which users can access various entities.
You can use the DROP COLUMN command to delete a column in SQL -
ALTER TABLE employees
DROP COLUMN age;
First, begin with ALTER TABLE sentence, and provide the name of the table, followed by DROP COLUMN and at the end give the name of the column which you would like to delete.
A Unique key is a constraint in SQL, where constraints are the rules imposed on the columns in the table and are utilized for limiting which type of data will go into that table. It could be either a column-level constraint or a table-level constraint.
Unique Key:
Whenever a unique key constraint is set on a column, it means that the column can’t have any redundant data in it. Simply put, all the records in that column must have unique values.
You can deploy multiple conditions with the help of AND, OR operators as follows -
SELECT * FROM employees WHERE first_name = ‘Steven’ AND salary <=15000;
In the above example, you can see that we’ve given 2 conditions. These conditions ensure that we list only those records where the employee's first name is “Steven,” and the second condition ensures that the employee's salary is less than 15000.
In simple words, this command will list all the records where the first name of the employee is “Steven,” and the salary of the employee must be less than 15000.
|
BASIS FOR COMPARISON |
SQL |
PL/SQL |
|
Basic |
In SQL, you can execute a single query or command simultaneously. |
In PL/SQL, you can execute a group of code simultaneously. |
|
Full form |
Structured Query Language |
Procedural Language, an extension of SQL. |
|
Purpose |
It is like a source of data that is to be displayed. |
It is a language that creates an application that displays data acquired by SQL. |
|
Writes |
In SQL, you can write queries and commands using DDL and DML statements. |
In PL/SQL, you can write a code block using the procedures, functions, packages, variables, etc. |
|
Usage |
Using SQL, you can retrieve, change, add, delete, or manipulate the data in the database. |
Using PL/SQL, you can create applications or server pages that display the information obtained from SQL in a proper format. |
|
Embed |
You can embed SQL statements in PL/SQL. |
You can not embed PL/SQL in SQL |
|
S. No. |
Where Clause |
Having Clause |
|
1 |
The WHERE clause indicates the criteria that individual records should meet to be selected by a query. It could be used without the GROUP by clause |
The HAVING clause can’t be used without the GROUP BY clause |
|
2 |
The WHERE clause selects rows before grouping |
The HAVING clause selects rows after grouping |
|
3 |
The WHERE clause can’t contain aggregate functions |
The HAVING clause can contain aggregate functions |
|
4 |
WHERE clause is used to enforce a condition on SELECT statement as well as single row function and is used before GROUP BY clause |
HAVING clause is used to enforce a condition on GROUP Function and is used after GROUP BY clause in the query |
|
5 |
SELECT Column, AVG(Column_nmae)FROM Table_name WHERE Column > value GROUP BY Column_nmae |
SELECT Columnq, AVG(Coulmn_nmae)FROM Table_name WHERE Column > value GROUP BY Column_nmae Having column_name>or |
That ends the section of basic interview questions. Let’s move on to the next section of Top SQL Interview Questions and Answers For Intermediate
SQL server operators are special characters or keywords that carry out particular tasks. They’re also utilized in SQL queries and in the WHERE clause of SQL commands. According to the given conditions, these operators filter out the data.
The operators in SQL can be categorized into the following types-
Arithmetic Operators: Used for mathematical operations on numerical data
Comparison Operators: Used for comparisons of two values and checking whether they are the same or different
Bitwise Operators: Used for bit manipulations between two expressions of type integer. It first converts integers into binary bits and then applies the operators.
Compound Operators: Used for operations on a variable before setting the variable’s result to the operation’s result
A data warehouse in SQL is a large data storehouse inside a business from various sources. This data helps make business decisions.
The FLOOR() function is used in SQL servers because it helps to identify the largest integer value to a given number, which could be equal or lesser.
Following is the difference between Clustered Vs. non-clustered indexes:
|
Parameters |
Clustered Index |
Non-clustered Index |
|
Used For |
Sorting and storing records physically in memory |
Creating a logical order for data rows; pointers are used for physical data files |
|
Methods for Storing |
Stores data in the leaf nodes of the index |
Never stores data in the leaf nodes of the index |
|
Size |
Quite large |
Comparatively, small |
|
Data Accessing |
Fast |
Slow |
|
Additional Disk Space |
Not required |
Required to store indexes separately |
|
Type of Key |
By default, the primary key of a table is a clustered index |
It could be used along with the unique constraint on the table that acts as a composite key |
|
Main Feature |
Boosts the performance of data retrieval |
Should be created on columns used in Joins |
CDC in SQL refers to Change Data Capture, which captures current INSERT, DELETE, and UPDATE activities deployed to SQL server tables. CDC maintains the record of changes made to SQL server tables in a proper format.
The full form of ACID property in a database is Atomicity, Consistency, Isolation, and Durability. Its properties are utilized for checking the accuracy of transactions.
Atomicity refers to completed or failed transactions, and a transaction refers to a single logical operation performed on data. This shows that if any facet of a transaction fails, the entire transaction fails, and the database state remains as it is.
Consistency means that the data fulfills all the credibility guidelines. The transaction never departs the database unless and until it finishes its state.
The main objective of Isolation is concurrency management.
The durability makes sure that once a transaction is committed, it’ll take place irrespective of what happens in between, like a power outage, fire, or some other type of disturbance.
Group functions in SQL work on a series of rows and returns a single result for every group. A few of the most commonly used group functions are - SQL COUNT(), MAX(), MIN(), SUM(), AVG() and VARIANCE().
Character manipulation functions in SQL are utilized for the manipulation of char. SQL Data types. A few of the char. Manipulation functions included are -
UPPER: Returns the string in uppercase.
Syntax:
UPPER(‘ string’)
Example:
SELECT UPPER(‘demo string’) from String;
Output:
DEMO STRING
LOWER: Returns the string in lowercase.
Syntax:
LOWER(‘STRING’)
Example:
SELECT LOWER (‘DEMO STRING’) from String
Output:
demo string
INITCAP: It converts the first letter of the string to uppercase and retains other letters in lowercase.
Syntax:
Initcap(‘sTRING’)
Example:
SELECT Initcap(‘dATASET’) from String
Output:
Dataset
CONCAT: Is used to concatenate two strings.
Syntax:
CONCAT(‘str1’,’str2’)
Example:
SELECT CONCAT(‘Data’,’Science’) from String
Output:
Data Science
LENGTH: Is used to get the length of a string.
Syntax:
LENGTH(‘String’)
Example:
SELECT LENGTH(‘Hello World’) from String
Output:
11
AUTO_INCREMENT in SQL is used for automatically generating a unique number at any time when a new record is added to the database.
As the primary key is distinct for each and every record, this field is inserted as the AUTO_INCREMENT field, because of which it is incremented whenever a new record is added.
The value of AUTO_INCREMENT begins with 1 and is incremented by 1 at any time when a new record is added.
Syntax:
CREATE TABLE Employee(
Employee_id int NOT NULL AUTO-INCREMENT,
Employee_name varchar(255) NOT NULL,
Employee_designation varchar(255)
Age int,
PRIMARY KEY (Employee_id)
)
Following is the difference between DELETE and TRUNCATE commands:
The syntax for the DELETE command is as follows:
DELETE FROM table_name
[WHERE condition];
Example:
select * from stu
Output:

delete from stu where s_name=’Bob’
Output:

The syntax for the TRUNCATE command is as follows:
TRUNCATE TABLE
Table_name;
Example:
select * from stu1
Output:
truncate table stu1
Output:
It deletes all the records from the specified table.
When you drop a table, all things related to that table get dropped as well. This consists of relationships described on the table with another tables, access privileges, grants, etc., that the specific database has, including integrity checks and constraints.
In order to create a table and use it again in its original form, each and every element related to the table must be redefined. But having said that, if a database is truncated, there aren’t such issues as said earlier. The database retains its original structure.
The usernames and passwords in the SQL server are stored in the main database inside the sysxlogins table.
Relationships are created by interlinking the columns of one table with the column of other tables. Following are the three types of relationships:
The third-party tools that are used in SQL server are as follows:
The expectations in the SQL server can be handled by TRY and CATCH blocks. Add the SQL statement in the TRY block and write the code in the CATCH block to manage the expectations. If there’s any error in the code inside the TRY block, the control will shift to that CATCH block automatically.
There are 2 authentication modes available in the SQL server. they are as follows:
A function in an SQL server is an SQL server database object, which is basically a group of SQL statements that lets input parameters, carry out the processing, and provide results only. It can return just a single value or table, and the potential to add, modify and delete records in tables isn’t available.
The 3 types of replication available in SQL servers are as follows:
The following command is used to find out the SQL Server versions and editions:
Select SERVERPROPERTY('productversion')
The COALESCE function in the SQL server takes up a set of inputs and outputs the first non-null value.
Syntax:
COALESCE(val1,val2,val3,……,nth val)
COALESCE function SQL server Example:
SELECT COALESCE(NULL, 1, 2, ‘MYSQL’)
Output:
1
SQL server lets the OLEDB provider, which gives the link, to connect to all database tables.
Example: Oracle, I’ve got an OLEDB provider with a link to connect with an SQL Server group.
SQL server agent plays a key role in the day-to-day working of SQL server administrator or database administrators. The objective of the SQL server agent is to deploy different tasks effortlessly with the help of a scheduler engine that lets the operations be carried out at the scheduled time.
It uses an SQL server to save information about scheduled management tasks.
Magic tables in SQL can be defined as conditional logical tables created by an SQL server for different activities like insert, delete, or update, i.e., DML operations. The operations recently performed on the rows are saved in magic tables automatically. These aren’t physical tables, but they’re just temporary internal tables.
There are a number of SELECT statement clauses in SQL; a few of the most widely used clauses with the SELECT queries are as follows:
FROM, WHERE, GROUP BY, ORDER BY, and HAVING.
The stuff() function in SQL is used to delete a part of a string and then add another part into the string, beginning at a particular position.
Syntax:
STUFF(String1, Position, Length, String2)
In the above syntax, String1 is the one that will be overwritten. The term Position represents the starting point for overwriting the string. Length indicates the length of the substitute string, and String2 is the string that will overwrite String1.
Example:
select stuff(‘DBMS Tutorial’,1,3,’Python’)
This will change ‘DBMS Tutorial’ to ‘Python Tutorial’
Output:
Python Tutorial
Views in SQL are the virtual tables that restrict the tables you wish to display. They’re nothing but the outcome of an SQL statement that has a name related to it. As views aren't present physically, they require less space to store.
Syntax:
For example: create view female_employee as select * from employee where e_gender=’Female’
select * from female_employee
Views in SQL are classified into the following 4 types -
Whether planning to switch your career to SQL or just want to upgrade your current position, this section will help you better prepare for the SQL interview. We’ve compiled a list of advanced SQL interview questions that might be frequently asked during the interview.
It is one of the hacking methods widely used by black-hat hackers to steal information from your database tables. For instance, let's say you visit a website and enter your confidential information and password; the hacker adds some malicious code there to gain your confidential information and password straight from your database. Therefore, if your table contains any crucial information, it's always essential to keep your data secure from this attack. Here’s a guide on introduction to SQL injection attacks.
A trigger in SQL refers to a stored program in a database that gives replies to a DML operation events performed using insert, modify, or delete operations, automatically. Simply put, it's nothing but an auditor of events taking place over all databases.
Let’s have a look at an example of a trigger in SQL:
CREATE TRIGGER bank_trans_hv_alert
BEFORE UPDATE ON bank_account_transaction
FOR EACH ROW
begin
if( abs(:new.transaction_amount)>999999)THEN
RAISE_APPLICATION_ERROR(-20000, 'Account transaction exceeding the daily deposit on SAVINGS account.');
end if;
End;You can insert multiple rows in SQL using below command:
INSERT INTO table_name (column1, column2,column3...)
VALUES
(value1, value2, value3…..),
(value1, value2, value3….),
...
(value1, value2, value3);
Begin with INSERT INTO query, followed by the name of the table in which you wish to insert the values. After that, give the list of the columns for which you would like to insert the values. Then add the VALUES keyword, and lastly, provide the list of values.
For example: how to insert multiple records into the table named employees
INSERT INTO employees (
name,
age,
salary)
VALUES
(
'Xavior',
21,
75000
),
(
' 'Amelia',
32,
85000 ),
(
'Mia',
26,
90000
);
82. How to find the nth highest salary in SQL?
You can use the TOP command to find the nth highest salary in SQL Server
SELECT TOP 1 salary FROM ( SELECT DISTINCT TOP N salary FROM #Employee ORDER BY salary DESC ) AS temp ORDER BY salary
You can also find the nth highest salary using the LIMIT keyword as follows:
SELECT salary FROM Employee ORDER BY salary DESC LIMIT N-1, 1
You can use the SELECT INTO statement to copy data from one database to another. You can either copy the entire data or just some particular columns.
Here’s how you can copy all the columns into a new table:
SELECT *
INTO newtable
FROM oldtable
WHERE condition;
If you wish to copy only specific columns, you can do it as in the following way:
SELECT column1, column2, column3, ...
INTO newtable
FROM oldtable
WHERE condition;
You can add a new column to a table in SQL using the ALTER command -
ALTER TABLE employees ADD COLUMN contact INT(10);
The above command will help you to add a new column named a contact in the employees’ table.
The LIKE operator in SQL server is used to check if the value of an attribute matches with the given string pattern or not.
For instance:
SELECT * FROM employees WHERE first_name like ‘Steven’;
Using this command, you’ll be able to extract all the records having their first name as “Steven”.
Yes, when we drop a table, the SQL server drops all the associated objects like constraints, indexes, columns, default, etc., but dropping a table won’t drop views and stored procedures because they exist outside the database table.
Yes, you can disable one trigger on the table with the help of
“DISABLE TRIGGER triggerName ON<>”
Another option to disable a trigger is by using the following statement -
“DISABLE Trigger ALL ON ALL SERVER”.
A Live Lock in SQL is one where an appeal regarding an exclusive lock is denied repeatedly because a series of overlapping shared locks continue interfering with it. It also appears when a read transaction creates a database table or page.
You can fetch records for both Even and Odd row numbers - when you wish to list even numbers - use the following command -
Select employeeId from (Select rowno, employeeId from employee) where mod(rowno,2)=0
To display odd numbers – use the following command -
Select employeeId from (Select rowno, employeeId from employee) where mod(rowno,2)=1
When you use a COMMIT in any transaction, all the modifications done in the transaction are stored in the database table permanently.
For Example: Delete a job candidate in a SQL server
BEGIN TRANSACTION; DELETE FROM HR.JobCandidate WHERE JobCandidateID = 20; COMMIT TRANSACTION;
Yes, you can join a table to itself with the help of self join. It is used when you wish to create a result set that combines records from table1 with records from table2 in the same table.
When 2 or more database tables are joined together with the help of the equal to operator, then it is called an equi join. We just have to focus on the condition is “=” (equal to) between the columns in the table.
Example:
Select a.Employee_name,b.Department_name from Employee a,Employee b where a.Department_ID=b.Department_ID
You can use the SELECT DISTINCT statement to get unique data from database tables using a query. The following SQL query selects just the DISTINCT values from the “Country” columns in the “Customers” table-
SELECT DISTINCT Country FROM Customers;
Here’s an example:
Select * into studentcopy from student where 1=2.
Using the above query, you can copy the data from the student table to another table, a similar structure with not a single row containing copied data.
SELECT * FROM (SELECT *, ROW_NUMBER() OVER (ORDER BY student_no) AS RowID FROM student) WHERE row_id %2!=0
When you join 2 or more tables without the “equal to” condition, that join is called Non-Equi Join. you can use operators such as <>,!=,<,>,Between.
For Example:
Select b.Department_ID,b.Department_name from Employee a,Department b where a.Department_id <> b.Department_ID;
You can delete duplicate records in a table with no primary key by using the SET ROWCOUNT command. It restricts the no. of records struck by a command.
Let’s take an example,
Suppose you’ve 2 duplicate rows, then you need to SET ROWCOUNT 1, execute the DELETE command, and then SET ROWCOUNT 0.
NVL and NVL2 functions in SQL check the value of exp1 to find whether it is NULL.
Using NVL(exp1, exp2) function, if the value of exp1 is not NULL, then the value of exp1 would be returned; on the other hand, the value of exp2 would be returned, but in case the similar data types as that of exp1.
Using NVL(exp1, exp2, exp3) function, if exp1 isn’t BULL, then exp2 is returned, else the value of exp3 is returned.
Each and every MyISAM table is stored on disk in the following 3 files:
It constricts the MyISAM tables, which minimizes their disk or memory usage.
It is a short form of the Indexed Sequential Access Method developed by IBM, to save and retrieve data on secondary storage devices such as tapes.
Database White box testing consists of Database Consistency and ACID properties Database triggers and logical views Decision Coverage, Condition Coverage, Statement Coverage Database Tables, Data Model, and Database Schema Referential integrity rules.
Following are the 3 different types of SQL sandbox:
Database Black Box Testing involves:
The Right Outer Join in SQL is used when users require all the records from the Right table (i.e., Second table) and just equal or matching records from the First or left table. The unmatched records are contemplated as NULL records.
For Example:
Select t1.col1,t2.col2….t ‘n’col ‘n.’. from table1 t1,table2 t2 where t1.col(+)=t2.col;
What is SQL subquery? It is a SQL query nested into a bigger query.
For example -
SELECT employeeID, firstName, lastName FROM employees WHERE departmentID IN (SELECT departmentID FROM departments WHERE locationID = 2000) ORDER BY firstName, lastName;
It is a prepared SQL code that could be stored and reused. Simply put, you can think of a stored procedure as a function containing a number of SQL statements to examine the database system. You can combine many SQL statements into a stored procedure and accomplish them at any time and anywhere.
Stored procedures can be used as a fact of modular programming, which means you can create a stored procedure at one time, save it and call it several times whenever required. This also helps in quicker execution when compared with multiple query execution. You can find more information about the introduction to stored procedures and its benefits here.
Syntax:
CREATE PROCEDURE procedure_name
AS
Sql_statement
GO;
To execute it use this:
EXEC procedure_name
Example:
Assume that you want to extract the age of the employees by creating a stored procedure.
create procedure employee_age
as
select e_age from employee
go
Now, we will execute it.
exec employee_age
Output:
108. Explain Inner Join with an example.
Inner join in SQL primarily provides records with similar /matching values in 2 database tables.
Syntax:
SELECT columns
FROM table1
INNER JOIN table2
ON table1.column_x=table2.column_y;
109. State the differences between views and tables.
|
Views |
Tables |
|
A view is a virtual table that is extracted from a database |
A table is structured with a set number of columns and a unlimited number of rows |
|
A view doesn’t hold data itself |
A table contains data and stores it in databases |
|
A view is used to query certain information contained in a few unique tables |
A table holds basic user information and cases of a characterized object |
|
In a view, we’ll get frequently queried information |
In a table, changing the information in the database changes the information that appears in the view |
A temporary table in SQL supports us in storing and processing transitional results. These database tables are developed and could be deleted automatically when they’re no longer needed. Temporary tables are valuable in places where temporary data must be stored.
Syntax:
CREATE TABLE #table_name();
The below query will create a temporary table:
create table #book(b_id int, b_cost int)
Now, we will insert the records.
insert into #book values(1,100)
insert into #book values(2,232)
select * from #book
Output:

OLTP: It is abbreviated as online transaction processing, and we can contemplate it as a category of software apps useful for helping transaction-related programs. One of the major attributes of this system is its potential to maintain consistency.
This normally follows decentralized planning to stay away from single points of failure. The OLTP system is often designed for a broad audience of end users to carry out small transactions.
The queries included in these tables are normally simple, require quick response time, and, in contrast, return in just a few records. Therefore, the no. of transactions per second acts as an effective method for those types of systems.
OLAP: It is abbreviated as online analytical processing and it's a division of software applications detected by a relatively lower frequency of online transactions. For these systems, the effectiveness of computing relies mainly on the response time. Therefore, these types of systems are often utilized for data mining or managing collected real data, and they’re often utilized in multiple schemas.
Hybrid OLAP or HOLAP utilizes a mixture of multiple data structures and RDBMS tables to save intricate data. The collection of a hybrid OLAP partition is saved using analysis services in a multifaceted manner, and the facts are saved in relational databases.
It is utilized for combining a table with itself. In this case, based on a few conditions, each row of a table is combined with itself and other rows of the database table.
Syntax:
SELECT a.column_name, b.column_name
FROM table a, table b
WHERE condition
A SQL database cursor is a control that lets you browse around a database’s rows or documents. It could be called a pointer for a row in a group of rows. They are highly beneficial in database traversal operations like extraction, addition, and deletion.
For example:
DECLARE @name VARCHAR(50)
DECLARE db_cursor CURSOR FOR
SELECT name
From myDB.company
WHERE employee_name IN (‘Jay’, ‘Shyam’)
OPEN db_cursor
FETCH next
FROM db_cursor
Into @name
Close db_cursor
DEALLOCATE db_cursor
The SQL INTERSECT operator helps combine 2 SELECT statements and gives only those records that are common between both statements. So, once you get Table 1 and Table 2 here, and if we implement the INTERSECT operator on these 2 tables, you’ll obtain only those records that are common to the output of the SELECT statements of these 2 database tables.
Syntax:
SELECT column_list FROM table1
INTERSECT
SELECT column_list FROM table2
The BETWEEN operator in SQL indicates rows depending on a group of values. The values could be nos., text, or dates. This operator provides the total number of values between 2 given ranges.
On the other hand, the IN operator in SQL is utilized to look for values inside the given range of values. If we’ve more than 1 value to select from, we need to use the IN operator.
You can find duplicate records in SQL using multiple ways. Here’s how you can do this:
Let’s see how can we find duplicate records using group by
SELECT
x,
y,
COUNT(*) occurrences
FROM z1
GROUP BY
x,
HAVING
COUNT(*) > 1;
Another option is using rank, as follows:
SELECT * FROM ( SELECT eid, ename, eage, Row_Number() OVER(PARTITION BY ename, eage ORDER By ename) AS Rank FROM employees ) AS X WHERE Rank>1
If you already know about other programming languages, you might have learned about if-else statements. Similarly, you can consider Case WHEN in SQL to be similar to that. In the Case WHEN statement, there’ll be more than one condition and we’ll select something based on these conditions -
Syntax for CASE WHEN:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
Begin by using CASE statement, followed by the multiple WHEN and THEN statements.
In order to delete duplicate rows in SQL, you can make use of multiple ways.
You can delete duplicate records using the rank statement, as follows -
alter table emp add sid int identity(1,1)
delete e
from emp e
inner join
(select *,
RANK() OVER ( PARTITION BY eid,ename ORDER BY id DESC )rank
From emp )T on e.sid=t.sid
where e.Rank>1
alter table emp
drop column sno
Here’s how you can delete duplicate records using groupby and min:
alter table emp add sno int identity(1,1)
delete E from emp E
left join
(select min(sno) sno From emp group by empid,ename ) T on E.sno=T.sno
where T.sno is null
alter table emp
drop column sno
You can change the data type of the column using the alter table. Here’s the command:
ALTER TABLE table_name
MODIFY COLUMN column_name datatype;
SQL refers to Structured Query Language and is mainly utilized to query data from relational database tables. When you talk about a SQL database, it’ll be a relational database table.
On the other hand, with respect to NoSQL databases, you’ll be working with non-relational tables.
You can get more information about NoSQL through the NoSQL tutorial.
The command used to change the column name in SQL differs for different RDBMS.
MYSQL:
ALTER TABLE Customer CHANGE Address Addr char(50);
ORACLE:
ALTER TABLE Customer RENAME COLUMN Address TO Addr;
In regards to SQL Server, it isn’t possible to rename the column using the ALTER TABLE command; for that, we need to use sp_rename.
Use the following command to drop a column in SQL:
ALTER TABLE employees
DROP COLUMN gender;
CHAR data type in SQL is utilized to save fixed-length character strings, whereas VARCHAR2 is utilized for storing variable-length character strings.
You can sort a column using the column alias in the ORDER BY rather than the where clause for sorting
COALESCE() function in SQL accepts 2 or more parameters, one parameter can apply 2 or as many parameters as possible, but it returns just the first non NULL parameter.
ISNULL() function in SQL accepts just 2 parameters. The 1st parameter is checked for a NULL value, and if it’s a NULL value, then the 2nd parameter is returned; else, it gives the 1st parameter.
SELECT SUM(salary) FROM employee
Aggregate functions in SQL are utilized to determine mathematical calculations and return single values. It could be calculated from the columns present in a table. whereas , Scalar functions in SQL returns a single value depending up on the input value.
For Example -.
Aggregate – max(), count – Calculated according to numeric.
Scalar – UCASE(), NOW() – Calculated according to strings.
A deadlock in SQL is an undesirable situation where 2 or more transactions are waiting endlessly for each other to emancipate locks.
The left outer join in SQL is helpful when you want each and every record from the left table (i.e., the first table) and just match records from the second table. The unequaled records are NULL records.
For example: Left outer join with “+” operator
Select t1.col1,t2.col2….t ‘n’col ‘n.’. from table1 t1,table2 t2 where t1.col=t2.col(+);
ALIAS command in SQL gives other names to a database table or a column, and it could be utilized in the SQL WHERE clause of SQL.query with the help of the “as” keyword.
A dynamic SQL can be executed as follows:
A recursive stored procedure is a procedure that calls by itself unless and until it gets to a boundary condition. This function is helpful for programmers in making using set of code many times.
BCP i.e., Bulk Copy, is a utility or a tool that exports/imports data from a table into a file and vice versa.
SELECT CURDATE();
ALTER TABLE Department ADD (Gender, M, F)
A SQL query first takes the lowest loss possible along with the smallest row level, and when more than one row is locked, the lock is raised to page lock or range, and when enormous pages are locked, it might raise to a table lock.
You can store videos inside SQL server by using FILESTREAM datatype, which was first introduced in SQL Server 2008.
SQL server is one of the most widely used database management products eversince, it released in 1989 by Microsoft Corporation. It is used across multiple industries to save and process huge amounts of data. It was mainly developed to save and process data that are created on a relational model of data.
PostgreSQL is the most widely used language for Object-Relational Database Management systems. It is primarily utilized for large web apps. PostgreSQL is an open-source, object-oriented, -relational database system that is highly powerful and allows users to expand any system without any issues.
Following are a few of the new data types in PostgreSQL
Indices in PostgreSQL allow the database server to find and retrieve specific rows in a given structure. Examples are B-tree, hash, GiST, SP-GiST, GIN and BRIN. Users can also define their indices in PostgreSQL. However, indices add overhead to the data manipulation operations and are seldom used
Tokens in PostgreSQL perform as the main ingredient of a source code and are made up of different special character symbols. Commands in PostgreSQL are made up of a series of tokens and end with a semicolon(“;”). It could be a constant, quoted identifier, other identifiers, keyword, or a constant. And they are normally separated by whitespaces.
Databases in PostgreSQL could be created using 2 methods
Syntax:-
CREATE DATABASE ;
Using the createdb command
Syntax:-
Creatdb [option…] [description]
Various other options can also be taken by the createDB command depending on the use case.
You can create a new table in PostgreSQL with by mentioning the table name, including all column names and their types as shown below:
CREATE TABLE [IF NOT EXISTS] table_name (
column1 datatype(length) column_contraint,
column2 datatype(length) column_contraint,
.columnn datatype(length) column_contraint,
table_constraints
);
A database query is basically a request for data from a database table. It can be either a select query or an action query.
SELECT fname, lname /* select query */ FROM myDb.students WHERE student_id = 1; UPDATE myDB.students /* action query */ SET fname = 'Captain', lname = 'America' WHERE student_id = 1;
A query within another query is called a subquery. It is mainly used to either restrict or make the data better than to be queried by the main query, hence restricting or making the output of the main query better.
There are two types of subquery - Correlated and Non-Correlated.
Correlated subquery: It is not considered as an independent query, but can refer to the column in a table listed in the FROM of the main query.
Non-correlated subquery: Considered as an independent query, the output of the non-correlated subquery is substituted in the main query.
It is one of the most important SQL interviews queries one needs to be prepared for.
Our Data Management Certification Courses for Freshers and Advanced Professionals assure to upskill your SQL and RDBMS fundamentals that enhances your career prospects.
There are five types of SQL queries:
Data Definition Language (DDL)
Data Manipulation Language (DML)
Data Control Language(DCL)
Transaction Control Language(TCL)
Data Query Language (DQL) Data Definition Language(DDL).
These different types of SQL queries help you define the database structure or schema. Gain a credible certified by enrolling with https://www.janbasktraining.com/. Get hands-on experience with real world projects and get trained from top industry professionals.
To get the current date in SQL Server, use the GETDATE() function.
Here is Syntax to get the first record from the table:
SELECT * FROM Table_Name WHERE Rownum = 1;
The first row of any table can be easily accessed by assigning 1 to the Rownum keyword in the WHERE clause of the SELECT statement.
Here, the delete option can be used with alias and inner join. First, go through the equality of all the matching records and then remove the row with higher EmpId.
DELETE E1 FROM EmployeeDetails E1 INNER JOIN EmployeeDetails E2 WHERE E1.EmpId > E2.EmpId AND E1.FullName = E2.FullName AND E1.ManagerId = E2.ManagerId AND E1.DateOfJoining = E2.DateOfJoining AND E1.City = E2.City;
Join the Janbask Training SQL community for better knowledge.
The MIN() function returns the smallest value of the selected column. The MAX() function returns the largest value of the selected column.
For Creating a View in SQL, we must use the Create View statement with the SELECT statement.
CREATE VIEW View_Name AS SELECT Column_Name1, Column_Name2, ..... FROM Table_Name WHERE Condition;
By using the TOP command in SQL Server:
SELECT TOP N * FROM EmployeePosition ORDER BY Salary DESC;
By using the LIMIT command in MySQL:
SELECT * FROM EmpPosition ORDER BY Salary DESC LIMIT N;
If you want to learn the concepts of DataStage to ace your upcoming interview, read our blog on top 50 DataStage Interview Questions and Answers.
To generate the first record from the EmployeeInfo table, you need to write a query as follows:
SELECT * FROM EmployeeInfo WHERE EmpID = (SELECT MIN(EmpID) FROM EmployeeInfo);
To generate the last record from the EmployeeInfo table, you need to write a query as follows:
SELECT * FROM EmployeeInfo WHERE EmpID = (SELECT MAX(EmpID) FROM EmployeeInfo);
It is one of the basic SQL queries interview questions that can be asked.
To Find Duplicate Records in the table, use the following query:
select a.* from Employee a where rowid !=
(select max(rowid) from Employee b where a.Employee_num =b.Employee_num;
To retrieve the last 3 records, write the following query:
SELECT * FROM EmployeeInfo WHERE EmpID <=3 UNION SELECT * FROM (SELECT * FROM EmployeeInfo E ORDER BY E.EmpID DESC) AS E1 WHERE E1.EmpID <=3;
To view specific records from the table, here is the query to follow:
SELECT * FROM Table_Name WHERE condition;
14. Write a query to fetch the EmpFname from the EmployeeInfo table in the upper case and use the ALIAS name as EmpName.
Syntax to fetch the EmpFname from the EmployeeInfo table in the upper case:
SELECT UPPER(EmpFname) AS EmpName FROM EmployeeInfo;
Here is the query to fetch the number of employees :
SELECT COUNT(*) FROM EmployeeInfo WHERE Department = 'HR';
To get the current date, you need write a query as follows in SQL Server:
SELECT GETDATE();
Write a query as follows in MySQL:
SELECT SYSTDATE();
Here is the Syntax to find the second highest value of the integer column:
Select MAX(Column_Name) from Table_Name
where Column_Name NOT IN (Select MAX(Column_Name) from Table_Name);
Here is the query to convert the floating-point value into the integer type.
SELECT CONVERT (int, 3025.58); ‘
19. Write a query to retrieve the first four characters of EmpLname from the EmployeeInfo table.
SELECT SUBSTRING(EmpLname, 1, 4) FROM EmployeeInfo;
By using the MID function in MySQL:
SELECT MID(Address, 0, LOCATE('(',Address)) FROM EmployeeInfo;
By using SUBSTRING:
SELECT SUBSTRING(Address, 1, CHARINDEX('(',Address)) FROM EmployeeInfo;
Here are the queries to follow:
By using the SELECT INTO command:
SELECT * INTO NewTable FROM EmployeeInfo WHERE 1 = 0;
By using the CREATE command in MySQL:
CREATE TABLE NewTable AS SELECT * FROM EmployeeInfo;
It is one of the basic SQL queries interview questions that can be asked.
The required query to fetch intersecting records of two tables:
(SELECT * FROM Worker)
INTERSECT
(SELECT * FROM WorkerClone);
Here is the required query:
SELECT * FROM EmployeePosition WHERE Salary BETWEEN '50000' AND '100000';
The required query to find the names:
SELECT * FROM EmployeeInfo WHERE EmpFname LIKE 'S%';
25. Write a query to fetch top N records.
There are two ways to fetch top N records. First, by using the TOP command in SQL Server:
SELECT TOP N * FROM EmployeePosition ORDER BY Salary DESC;
Second, through the LIMIT command in MySQL:
SELECT * FROM EmpPosition ORDER BY Salary DESC LIMIT N;
If you want to Test Your SQL Skills, Play our online SQL Quiz and find out where you stand!
If you have an auto-increment field e.g. EmpId, then you can easily follow the below query to fetch an even row-
SELECT * FROM EmployeeDetails
WHERE MOD (EmpId, 2) = 0;
If you don’t have such a field, then you need to use the below queries.
Using Row_number in SQL server and checking that the remainder when divided by 2 is 1-
SELECT E.EmpId, E.Project, E.Salary
FROM (
SELECT *, Row_Number() OVER(ORDER BY EmpId) AS RowNumber
FROM EmployeeSalary
) E
WHERE E.RowNumber % 2 = 0;
You can also use a user-defined variable in MySQL-
SELECT *
FROM (
SELECT *, @rowNumber := @rowNumber+ 1 rn
FROM EmployeeSalary
JOIN (SELECT @rowNumber:= 0) r
) t
WHERE rn % 2 = 0;If you have an auto-increment field e.g. EmpId, then you can easily use the below query-
SELECT * FROM EmployeeDetails
WHERE MOD (EmpId, 2) <> 0;
If you don’t have such a field then you need to use the below queries.
Using Row_number in SQL server and checking that the remainder when divided by 2 is 1-
SELECT E.EmpId, E.Project, E.Salary
FROM (
SELECT *, Row_Number() OVER(ORDER BY EmpId) AS RowNumber
FROM EmployeeSalary
) E
WHERE E.RowNumber % 2 = 1;
You can also use a user defined variable in MySQL-
SELECT *
FROM (
SELECT *, @rowNumber := @rowNumber+ 1 rn
FROM EmployeeSalary
JOIN (SELECT @rowNumber:= 0) r
) t
WHERE rn % 2 = 1;Need to follow the below query:
SELECT CONCAT(EmpFname, ' ', EmpLname) AS 'FullName' FROM EmployeeInfo;
This is an important answer to these kinds of SQL query interview questions.
SQL Server – Using MINUS- operator-
SELECT * FROM EmployeeSalary
MINUS
SELECT * FROM ManagerSalary;
MySQL – Since user-defined has MINUS operator so we can use LEFT join-
SELECT EmployeeSalary.*
FROM EmployeeSalary
LEFT JOIN
ManagerSalary USING (EmpId)
WHERE ManagerSalary.EmpId IS NULL;
This is a Key response to these types of SQL Query interview questions.
Here is the query-
CREATE TABLE NewTable
SELECT * FROM EmployeeSalary where 1=0;
It is one of the very basic SQL Query Interview Questions in which the interviewer wants to check if the person knows about the commonly used – Is NULL operator.
SELECT EmpId
FROM EmployeeSalary
WHERE Project IS NULL;
To fetch all the employees' details, use BETWEEN for the date range ’01-01-2025′ AND ’31-12-2025′-
SELECT * FROM EmployeeDetails
WHERE DateOfJoining BETWEEN '2025/01/01'
AND '2025/12/31';
Also, you can extract year part from the joining date by using YEAR in mySQL-
SELECT * FROM EmployeeDetails
WHERE YEAR(DateOfJoining) = '2025';
Here, you must simply use the ‘+’ operator in SQL.
SELECT EmpId,
Salary+Variable as TotalSalary
FROM EmployeeSalary;
To fetch the max, min, and average values, use the aggregate function of SQL:
SELECT Max(Salary),
Min(Salary),
AVG(Salary)
FROM EmployeeSalary;
35. Fetch all employees from EmployeeDetails who have a salary record in EmployeeSalary.
SELECT * FROM EmployeeDetails E
WHERE EXISTS
(SELECT * FROM EmployeeSalary S
WHERE E.EmpId = S.EmpId);
The SQL query has two major needs– To fetch the project-wise count and then to sort the result by that count.
For project-wise count, the GROUP BY clause is used, and for sorting, the ORDER BY clause is used on the alias of the project-count.
SELECT Project, count(EmpId) EmpProjectCount
FROM EmployeeSalary
GROUP BY Project
ORDER BY EmpProjectCount DESC;
37. Write an SQL query to fetch duplicate records from EmployeeDetails (without considering the primary key.
To fetch duplicate records from the table, the GROUP BY is used on all the fields, and then the SQL HAVING clause is used to return only those fields whose count is greater than 1 i.e. the rows having duplicate records.
SELECT FullName, ManagerId, DateOfJoining, City, COUNT(*)
FROM EmployeeDetails
GROUP BY FullName, ManagerId, DateOfJoining, City
HAVING COUNT(*) > 1;
To create a new table, the SQL CREATE TABLE syntax is:
CREATE TABLE new_table AS (SELECT * FROM old_table WHERE 1=2); For example: CREATE TABLE suppliers AS (SELECT * FROM companies WHERE 1=2);
It is one of the basic SQL queries interview questions that can be asked.
The required query to fetch duplicate records is –
SELECT WORKER_TITLE, AFFECTED_FROM, COUNT(*)
FROM TitleGROUP BY WORKER_TITLE, AFFECTED_FROMHAVING COUNT(*) > 1;
Here, you can use the left join with the EmployeeDetail table on the left side of the EmployeeSalary table.
SELECT E.FullName, S.Salary
FROM EmployeeDetails E
LEFT JOIN
EmployeeSalary S
ON E.EmpId = S.EmpId;
This is another one of the very common SQL Query Interview Questions in which the interviewer wants to check the knowledge of SQL professionals.
Use the below to show the last record from the Worker table:
Select * from Worker where WORKER_ID = (SELECT max(WORKER_ID) from Worker);
42. Write an SQL query to fetch all the Employees who are also managers.
There is Self-Join as the requirement need analyst is the EmployeeDetails table as two tables. Here, two different aliases, ‘E’ and ‘M’ for the same EmployeeDetails table.
SELECT DISTINCT E.FullName
FROM EmployeeDetails E
INNER JOIN EmployeeDetails M
ON E.EmpID = M.ManagerID;
To fetch duplicate records from the table, the GROUP BY is used on all the fields and then the HAVING clause is used to return only those fields whose count is greater than 1 i.e. the rows having duplicate records.
SELECT FullName, ManagerId, DateOfJoining, City, COUNT(*)
FROM EmployeeDetails
GROUP BY FullName, ManagerId, DateOfJoining, City
HAVING COUNT(*) > 1;
SQL is a programming language used for database systems, while MySQL is used in all the primary programming languages like C, C++, Perl, PHP, Python, Ruby, and more.
Here are two different types of case manipulation:
LOWER. The lower function converts a given string into a lower case.
UPPER: The upper Function converts the given character String to Upper Case.
A function is a set of SQL statements used to do a specific task. The main use of functions is to foster code reusability. When you are repeatedly writing large SQL scripts to do the same task, you can create a function to do that task. So, next time you do not need of rewrite the SQL, you can simply call that function.
There are five aggregate functions in SQL – MIN, MAX, COUNT, SUM, and AVG.
There are mainly three attributes of indexing: Clustered Indexing. Non-Clustered, and Multilevel Indexing.
These are the most popular and useful SQL interview questions and answers. These interview questions are created specifically to familiarise you with the questions you might encounter during your SQL interview. If you are just starting out and need a professional guide, or wondering where to start learning the highly coveted in-demand skills? Check out the courses on JanBask Training. Enroll in online SQL server training, learn the most sought after skills, and get your certification. Hurry!
Q1. How does SQL Server certification training help in cracking the SQL job interview?
SQL server training helps to build good SQL queries and helps develop team members’ logical thinking skills. And optimizing SQL queries helps you know which questions you will be asked, and how those questions should best be phrased.
Q2. What is the correct SQL career path?
SQL career path includes SQL Server Database Administration, and Development, Business intelligence professionals, Data science, and engineering will come in successful SQL career path.
Q3. How to become a SQL professional?
Here is a step-wise process to become an SQL professional:
Q4. What is the SQL developer's salary?
The average SQL developer salary is $87,125 per year in the United States and $5,000 cash bonus per year. For more details on salary check out detailed insights on SQL developer salary.
Thanks for checking this post so far. If you like these SQL interview questions, then please share this post with your friends and colleagues. If you have any questions or feedback, feel free to let us know in the comment below
Q1. How does SQL Server certification training help in cracking the SQL job interview?
SQL server training helps to build good SQL queries and helps develop team members’ logical thinking skills. And optimizing SQL queries helps you know which questions you will be asked, and how those questions should best be phrased.
Q2. What is the correct SQL career path?
SQL career path includes SQL Server Database Administration, and Development, Business intelligence professionals, Data science, and engineering will come in successful SQL career path.
Q3. How to become a SQL professional?
Here is a step-wise process to become an SQL professional:
Q4. What is the SQL developer's salary?
The average SQL developer salary is $87,125 per year in the United States and $5,000 cash bonus per year. For more details on salary check out detailed insights on SQL developer salary.
Thanks for checking this post so far. If you like these SQL interview questions, then please share this post with your friends and colleagues. If you have any questions or feedback, feel free to let us know in the comment below
Top SQL interview questions and answers for freshers, intermediate and experienced professionals will help you prepare for your SQL interview. Want to succeed in your interview

SQL Server MERGE Statement: Question and Answer
 Jul 11, 2023
Jul 11, 2023  3.5k
3.5k
Top SSRS Interview Questions And Answers
Jul 30, 2024 3.1k

Mastering INSERT and OVER DML Syntax: Interview Questions Guide
Jul 11, 2023 2.9k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment








