Grab Deal : Flat 30% off on live classes + 2 free self-paced courses - SCHEDULE CALL
In the world of data science, ensemble methods have become increasingly popular over the years. These methods involve combining multiple models to improve their accuracy and performance. Two common types of ensemble methods are bagging and boosting in data mining. In this blog post, we will explore what these terms mean, how they work, and their applications in data mining. Let's dive more into ensemble methods and learn more about their importance in data science or mining and key takeaways. You should check out the data science tutorial guide to clarify your basic concepts.
Bagging in data mining stands for Bootstrap Aggregating, which involves creating several subsets of a dataset by randomly selecting samples with replacements from the original set. Each subset is then used to train a model independently using different algorithms or parameters. The final prediction is made by averaging or voting across all models.
Bagging helps reduce variance by reducing overfitting since each model only sees a portion of the data rather than the entire dataset. It also increases stability as small changes in input do not significantly impact output due to averaging or voting across multiple models.
Applications of bagging include decision trees, random forests, neural networks, and support vector machines (SVMs). Random forests use bagged decision trees where each tree has a unique sample set that contributes to an overall prediction.
The basic idea behind the bagging in data mining is to combine several weak learners into one strong learner by averaging their predictions or taking a majority vote. The process can be broken down into five steps:
1) Randomly select N samples (with replacement) from the original dataset.
2) Train a base model on each subset.
3) Repeat steps 1-2 B times (where B = a number of base models).
4) Combine all base models by averaging their predictions or taking a majority vote.
5) Use the combined model to make predictions on unseen data.

Bagging, short for Bootstrap Aggregation, is a popular ensemble learning technique in data science that combines multiple models to improve the accuracy and stability of predictions. This guide will walk you through the step-by-step process of implementing bagging in data science.
Step 1: Choose a Base Model
The first step in implementing bagging is to choose a base model. This can be any machine learning algorithm, such as decision trees, random forests, or support vector machines (SVM). Selecting an algorithm that works well with your dataset and has low variance is important.
Step 2: Create Multiple Samples
Next, you must create multiple samples from your original dataset using bootstrap sampling. This involves randomly selecting observations from the original dataset with replacements until you have as many samples as desired. Each sample should be the same size as the original dataset.
Step 3: Train Models on Each Sample
Once you have created multiple samples from your original dataset, you must train a separate instance of your base model on each sample. For example, if you are using decision trees as your base model and have created five samples from your original dataset, then you would train five different decision tree models – one for each sample.
Step 4: Combine Predictions
After training all individual models on their respective bootstrapped datasets, it’s time to combine them into one final prediction by taking an average or majority vote, depending upon whether it's a regression or classification problem.
One major advantage of the bagging algorithm in data mining is that it reduces overfitting by creating diverse training examples for each base model. This diversity ensures no single model dominates others and helps prevent errors caused by bias-variance tradeoff issues.
Another advantage of bagging in data science includes improved accuracy due to the ensemble learning approach; combining multiple weaker learners results in better performance than any individual learner alone.
One disadvantage of bagging is that it can be computationally expensive, especially when dealing with large datasets. Training multiple models on different subsets of the data requires more computational resources and time.
Another disadvantage is that bagging may not work well with highly imbalanced datasets or noisy data. In such cases, some base models may perform poorly and negatively impact the overall performance of the combined model.
Boosting involves sequentially training weak learners on weighted versions of datasets where misclassified points receive higher weights than correctly classified ones until convergence or maximum iterations are reached. The final prediction is made by aggregating predictions from all weak learners using weighted majority voting.
Boosting improves accuracy by focusing on hard-to-classify examples while down-weighting easy ones during training iterations leading to better generalization performance on unseen test sets compared to single-model approaches like logistic regression or SVMs without any ensemble techniques applied.
Applications of boosting include AdaBoost (Adaptive Boosting), Gradient Boosted Trees (GBTs), and XGBoost (Extreme Gradient Boosting), among others. GBTs use boosting to sequentially add decision trees that correct errors made by previous models.
To illustrate how boosting can improve model performance, let's consider a binary classification problem where we want to predict whether a customer will buy a product based on age and income level. We have collected data from 1000 customers with equal distribution between buyers and non-buyers.
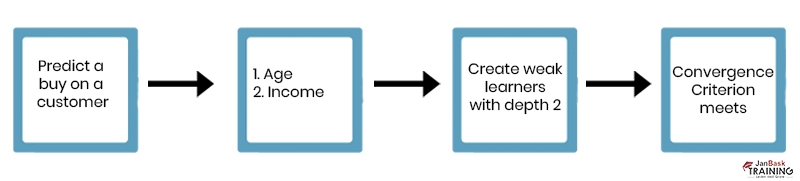
We first create two weak learners using decision trees with depth=1 (i.e., one split). These models have low accuracy because they only use one feature for splitting nodes; however, they serve as starting points for boosting iterations.
In the first iteration, we assign equal weights to all instances in our dataset and train both weak learners on this weighted data version. We then calculate errors made by each model and adjust weights assigned to misclassified instances accordingly (i.e., increase weight if misclassified).
In the second iteration, we re-weight our dataset based on updated instance weights from the previous iteration and train both weak learners again. This process continues until convergence criteria are met (e.g., the maximum number of iterations reached).
Finally, we combine all strong learners into one ensemble model by taking weighted average predictions across all models. This approach results in higher accuracy than any single decision tree used alone or bagged together without adjusting instance weights during training iterations.
Bagging and boosting have numerous applications in data science, including:
1) Classification Problems - Both techniques are commonly used for classification tasks where the goal is to predict a categorical variable based on input features.
2) Regression Problems - In regression analysis, bagging and boosting can help improve prediction accuracy when dealing with noisy or complex datasets.
3) Anomaly Detection - Ensemble methods like bagging and boosting can also be useful for detecting anomalies or outliers within large datasets.
4) Natural Language Processing (NLP)- NLP involves analyzing text data using machine learning algorithms. Ensemble methods like bagging and boosting have been shown to significantly improve the accuracy of NLP models.

Bagging and boosting are ensemble methods used to improve model performance, but they differ in their approach.
Bagging focuses on reducing variance by averaging or voting across multiple independently trained models, while boosting aims to reduce bias by iteratively training weak learners on weighted versions of datasets until convergence or maximum iterations are reached.
Bagging is more suitable for unstable algorithms like decision trees, where small changes in input can lead t significant changes in output, whereas boosting works well with stable algorithms like SVMs, where the margin between classes remains constant even with minor perturbations in input data.
Regarding computational efficiency, bagging is faster than boosting since each model trains independently without any dependencies on previous iterations. However, it may not always result in better accuracy compared to boosting due to its focus on reducing variance rather than bias. You can learn the six stages of data science processing to grasp the above topic better.
Although bagging and boosting have different approaches to improving classification accuracy, they share some commonalities:
1) Both Use Ensemble Learning - Ensemble learning combines multiple machine learning models into one predictive system that performs better than its individual components.
2) Both Involve Creating Multiple Models - In both cases, several models are created instead of just one using bootstrapping or sequential training methods.
3) Both Aim to Reduce Errors - Bagging reduces variance by averaging predictions from multiple models while boosting reduces bias by iteratively correcting errors made by previous models.
4) Both Can be Used With Various Machine Learning Algorithms - Bagging and Boosting are not limited to specific algorithms. They can be applied to any algorithm that supports ensemble learning.

Regarding machine learning, two popular techniques often used for improving the accuracy of models are bagging and boosting. Bagging is a technique where multiple models are trained on different subsets of the data, and their predictions are combined to make a final prediction. This method helps reduce overfitting and increases model stability. Boosting, conversely, involves sequentially training weak learners in an iterative manner to create a stronger overall model.
There are certain scenarios where one technique may be more appropriate than the other. For example, if you have a lot of noisy data or outliers in your dataset, bagging could help improve model performance by reducing variance. On the other hand, boosting may be more suitable if your goal is to minimize bias and increase accuracy even further than what you can achieve with bagging alone.
Research has shown that bagging and boosting can significantly improve the performance of machine learning algorithms across various domains, such as image classification and natural language processing (NLP). For instance, an NLP task involving sentiment analysis on customer reviews of hotels from the TripAdvisor dataset showed better results after applying ensemble methods like Random Forests(bagging) & Gradient Boosting Machines(Boosting).
Choosing between bagging or boosting depends mainly on factors such as the data type being analyzed and the desired accuracy level required from our predictive model. Understanding when each technique should be applied will enable us to optimize our modeling efforts effectively while avoiding common pitfalls like underfitting or overfitting, which leads to poor generalization ability during deployment time.
Using Bagging and Boosting Together
While both techniques work well independently, they can be combined for even better results. This approach is known as "bagged-boosted" or "boosted-bagged" ensemble learning. The idea behind this combination is that it takes advantage of both approaches' strengths while minimizing their weaknesses simultaneously.
For example, you could use bagging first to create several subsets of your dataset before boosting each subset sequentially. This would help reduce overfitting while allowing you to correct errors made by previous models through iterative training methods like gradient descent or the AdaBoost algorithm.
Ensemble methods have several advantages over single-model approaches, such as improved accuracy, stability, and generalization performance due to combining multiple models' strengths while mitigating their weaknesses. They also help reduce overfitting and increase robustness against outliers or noisy data points that may negatively affect individual models' predictions.
However, ensemble methods come at the cost of increased complexity and computational resources required for training multiple models simultaneously. They also require careful tuning of hyperparameters such as learning rates or regularization parameters that can impact overall performance significantly if not optimized correctly.

Data Science Training
Ensemble methods like bagging and boosting in data mining have become essential tools for improving machine learning model performance across various domains ranging from finance, healthcare, and marketing, among others. Understanding how these techniques work can help data scientists choose appropriate strategies depending on the dataset's characteristics and problem domain requirements. While there are trade-offs involved when using ensemble techniques compared to single-model approaches, their benefits outweigh the costs in most cases, leading to better predictive accuracy and robustness. You can also learn about neural network guides and python for data science if you are interested in further career prospects in data science.

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  10.1k
10.1k Mar 03, 2023 9.7k
Mar 03, 2023 9.7k

Rule-Based Classification in Data Mining
Mar 27, 2023 9.6k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







