Grab Deal : Flat 30% off on live classes + 2 free self-paced courses - SCHEDULE CALL
Machine learning has revolutionized the way we analyze data and make decisions. It is a subset of artificial intelligence that involves building algorithms that can learn from data without being explicitly programmed. One such algorithm is the Birch clustering algorithm, which is widely used for unsupervised learning tasks.
Birch clustering is an efficient hierarchical clustering algorithm that can handle large datasets with ease. In this blog post, we will explore what is birch clustering in data mining, how it works, and its applications in machine learning. For an in-depth understanding of BIRCH clustering, our data scientist course online helps you explore more about BIRCH in data mining, the most effective tool of data science.
Using hierarchies, BIRCH (Balanced Iterative Reducing and Clustering) is able to cluster enormous amounts of numerical data in an effective and economical manner because to the combination of hierarchical clustering (during the basic microclustering step) and additional clustering algorithms, including iterative partitioning (at the later macroclustering stage). Agglomerative clustering methods have been plagued by issues relating to scalability and undoability, however this solution overcomes such issues.
BIRCH suggests the concepts of clustering feature and clustering feature tree in order to summarise cluster representations (CF tree). The utilisation of these frameworks renders the clustering method effective for incremental and dynamic clustering of incoming items, in addition to performing admirably while working with large datasets.
Let's take a more in-depth look at some of the structures that we've already covered. When we have a cluster of n data items or points with d dimensions, we may define its centroid as x0, its radius as R, and its diameter as D using the formulas below.
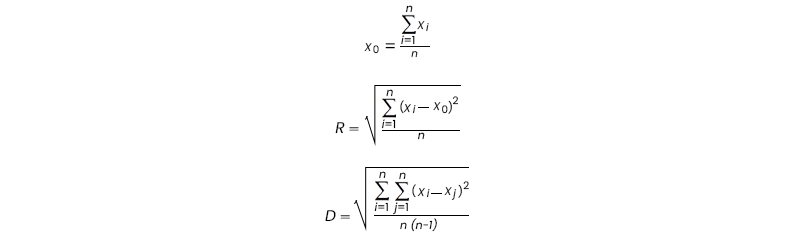
In where R represents the average distance travelled by members of the cluster to reach the cluster's centre and D represents the average distance travelled by any two items inside the cluster. The values of R and D indicate the degree to which the cluster is concentrated around its nucleus. A clustering feature, also known as a CF, is a summary vector that has three dimensions and is used to define groupings of things. If we have a collection of n d-dimensional points or objects that are designated by xi, then we can define the centre of mass of that collection as
CF = (n, LS, SSi),
where LS represents the linear sum of the n points (i.e., n I equals 1 xi), SS represents the square sum of the data points (i.e., n I equals 1 xi 2), and n is the total number of points in the cluster.The zeroth, first, and second moments of a cluster are summed up by the clustering properties of that cluster if we look at it from a statistical point of view.The components that go into the clustering process are cumulative. Let's say, for the sake of illustration, that there are two distinct clusters, C1 and C2, each with its own individual set of features that are diagnostic of clustering (CF1 and CF2). When clusters C1 and C2 come into contact with one another, they produce a bigger cluster that possesses the clustering feature CF1.
All of the metrics that are required for making judgements on clustering may be computed using only the clustering characteristics that are provided by BIRCH. BIRCH successfully utilises storage space by eliminating the requirement to store all objects by employing the clustering characteristics to summarise information about the clusters of things. This allows BIRCH to eliminate the need to keep all of the objects.
Birch clustering is particularly useful for large datasets that do not fit into memory. It uses a two-phase approach to cluster the data: first, it builds an in-memory summary of the dataset by computing statistics such as the means and variances of each feature. This summary is called a Clustering Feature (CF) and allows Birch to quickly identify candidate clusters.
In the second phase, BIRCH iteratively reduces and merges clusters until it reaches a stopping criterion defined by the user. The reduction step involves merging small clusters with their nearest larger neighbor based on distance metrics such as Euclidean or Manhattan distance. The merging step involves combining two CFs into a new one that represents their union.A limitation of Birch clustering is that it assumes spherical-shaped clusters with similar sizes and densities, which may not always hold true for real-world datasets. Additionally, since it relies on summarizing statistics rather than individual data points' distances, it may lose some information about local structures within clusters.
Overall, birch clustering offers an efficient way to cluster large datasets while providing some robustness against noise. Its use cases include image segmentation, document classification, and customer segmentation in marketing analysis.
The effectiveness of prior clustering approaches deteriorated as the size of the datasets being processed grew, and the prospect that a dataset would be too large to be stored in main memory was not well considered. Before arriving at any particular conclusion on clustering, the majority of BIRCH's predecessors, including BIRCH itself, first conduct an exhaustive investigation of all data points that are now accessible, as well as of all clusters that are already in existence. That is to say, they do not employ the utilisation of the distance between data points as a surrogate for the heuristic weighting process. As a result, a significant amount of work was required to maintain a high level of clustering quality while maintaining a low level of IO (input/output) expenses.
Example: Suppose that there are three points, (2, 5), (3, 2), and (4, 3), in a cluster, C1. The clustering feature of C1 is CF1 = h3,(2+3+4,5+2+3),(2 2 +3 2 +4 2 ,5 2 +2 2 +3 2 )i = h3,(9,10),(29,38)i. Suppose thatC1 is disjoint to a second cluster,C2, whereCF2 = h3, (35, 36), (417, 440)i. The clustering feature of a new cluster,C3, that is formed by mergingC1 andC2, is derived by adding CF1 and CF2. That is, CF3 = h3+3,(9+35,10+36),(29+417,38+440)i = h6,(44,46),(446,478)i.
A hierarchical clustering can save the clustering characteristics it uses in a height-balanced tree structure that's known as a CF tree. This format is used to store the clustering characteristics. The example shown is quite normal. A nonleaf node in a tree is distinguished from a leaf node by the fact that it can produce more nodes, sometimes known as "children." The information on their offspring's clustering is summed up by the nonleaf nodes, which do this by storing the total number of CFs for their children. The branching factor B and the threshold T are the two variables that may be used to tailor the appearance of CF trees. The branching factor determines the maximum number of progeny that can emerge from each nonleaf node in the tree. The threshold parameter determines the maximum size of the subclusters that are stored in the leaf nodes of the tree. These two parameters have an effect on the total size of the tree that is created.BIRCH will, wherever it is practicable to do so, employ all of the methods at its disposal to produce the most effective clusters. When working with a limited amount of main memory, it is essential to cut down on the amount of time spent on input and output as much as possible. BIRCH employs a multiphase clustering strategy; after the initial scan of the data set, an acceptable clustering is achieved, and one or more more scans can be utilised to (optionally) boost the quality of the clustering. The following are the primary stages:
During the first step of the procedure, BIRCH will scan the database in order to build an initial CF tree in memory. One way to think about this is as a multilayer compression of the data, one that makes an effort to keep the natural clustering structure of the data intact.

In the second phase, BIRCH applies a clustering approach on the leaf nodes of the CF tree. This method eliminates sparse clusters as outliers and combines dense clusters into larger clusters.
Items are being dynamically added to the CF tree as it is being developed in real time at this early stage. As a direct consequence of this, this plan is carried out in stages. An item is kept in the leaf entry that is geographically closest to it (subcluster). If the diameter of the subcluster that was stored in the leaf node after insertion is larger than the threshold value, then the leaf node, as well as maybe some other nodes, are split. When a new node is added to a tree, the information about that node is sent upstream to the nodes that are immediately next to it. The size of the CF tree is sensitive to changes in the threshold value. A lower threshold value can be specified in order to reconstruct the CF tree in the event that the amount of space needed to store the CF tree is more than the quantity of main memory. During the process of rebuilding, a new tree is formed with the leaf nodes of the previous tree serving as the construction blocks. As a direct consequence of this, it will not be necessary to reread any of the points or objects in order to finish the process of tree reconstruction. This process is comparable to inserting and splitting nodes when it comes to the construction of B+ trees. As a result, the data need only be read through once in order to form the tree. In order to manage outliers and improve the overall quality of CF trees, a number of heuristics and methods that undertake additional data scans have been put into place. In the second phase, you will use the CF tree in conjunction with whatever clustering strategy you choose, such as a basic partitioning algorithm.
The computational difficulty of the approach may be expressed as O(n), where n refers to the total number of items that are clustered. Experiments have shown that the approach has a high clustering quality and that its scalability is linear with respect to the number of items. Owing to the fact that each node in the CF tree may only hold a limited number of items due to its size, it is possible that a CF tree node will not necessarily correspond to what a user may believe to be a natural cluster. Additionally, because it leverages the idea of radius or diameter to limit the borders of a cluster, BIRCH does not fare well if the clusters are not spherical in shape. This is one of the reasons why BIRCH is not as popular as it once was.
Birch clustering is a hierarchical clustering algorithm that can handle large datasets efficiently. It uses a tree-based data structure called the Clustering Feature Tree (CFT) to represent the dataset in memory. The CFT consists of internal nodes and leaf nodes, where each leaf node stores a subset of the original data points.
The initialization stage sets up an empty CFT with one root node containing no data points initially. In this stage, birch also requires two parameters: the branching factor B and the threshold T. The branching factor determines how many children each internal node can have, while the threshold determines when to split a leaf node into two child nodes.
In the merging stage, birch reads each input point one by one and inserts it into the appropriate leaf node based on its distance from existing centroids' mean value. If any leaf node exceeds a predefined threshold size or radius limit during insertion, it gets split into two new child nodes using K-means clustering until all leaf nodes satisfy these constraints.
Example: Suppose we have 1000 data points and set B=10 and T=0.5 as our parameters for birch clustering. In this case, we start with an empty CFT consisting of only one root node at level zero. We then read each of our 1000 input points one by one and insert them into their corresponding leaf nodes based on their distances from existing centroids' mean values.
Suppose after inserting some number of input points; we find that some of our leaf nodes exceed either B or T thresholds - say Leaf Node A has reached its maximum capacity due to having more than ten input points assigned to it or has exceeded its radius limit due to being too far away from other centroid clusters in space compared to other leaves around it). Then Birch will split Leaf Node A into two new child notes using K-means clustering until both meet these constraints again.
Finally, in pruning stage birch removes redundant centroids by recursively merging them if their distances are below another predefined threshold value until only one centroid remains at each level of hierarchy within CFT. This step helps to eliminate any noise in the data and ensures that all clusters are well-defined.
BIRCH clustering algorithm that offers several advantages for clustering tasks. Here are some of the key advantages of using BIRCH clustering:
Birch clustering has several applications in machine learning, including:
Data Science Training For Administrators & Developers

BIRCH clustering is a powerful unsupervised learning algorithm that can handle large datasets efficiently and accurately. Its ability to create a hierarchical structure of clusters makes it useful for various applications such as image segmentation, customer segmentation, anomaly detection, and text classification.By understanding how birch clustering works and its potential applications in machine learning, data scientists and analysts can leverage this algorithm's capabilities to gain valuable insights from complex data sets. Understanding BIRCH clustering in data mining begins with understanding data science; you can get an insight into the same through our data science training.

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  10.1k
10.1k Mar 03, 2023 9.7k
Mar 03, 2023 9.7k

Rule-Based Classification in Data Mining
Mar 27, 2023 9.6k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







