Christmas Offer : Get Flat 50% OFF on Live Classes + $999 Worth of Study Material FREE! - SCHEDULE CALL
Imagine those busy weekends before Diwali when your mom asks you to clean your room and rearrange all your belongings in proper order. Your room otherwise is cluttered, with belongings lying anywhere and everywhere. It is very difficult to find anything in that mess. But after the day-long work of removing the unnecessary things and moving around the rest of your belongings properly, you realize searching for things has become very easy. The same thing can happen to your data if you do not properly store them. There can be data loss, redundancy, and duplicity. To avoid all this, we have normalization. Understanding the SQL normalizations begin with the understanding of SQL Server; you can get an insight about the same through our online SQL server training.
So, let’s get to know what is normalization in SQL. Normalization is the process of organizing data in a database. This includes creating tables and establishing relationships between those tables according to rules designed to protect the data and make the database more flexible by eliminating redundancy and inconsistent dependency.
A large database defined as a single relation may result in data duplication. This repetition of data may result in the following:
To handle these problems, we should analyze and decompose the relations with redundant data into smaller, simpler, and well-structured relations that satisfy desirable properties. Normalization is a process of decomposing relations into relations with fewer attributes.
The main reason for normalizing the relations is to remove these anomalies. Failure to eliminate anomalies leads to data redundancy and can cause data integrity and other problems as the database grows. Normalization consists of a series of guidelines that helps to guide you in creating a good database structure.
Normalization works through a series of stages called Normal forms. The normal forms apply to individual relations. The relation is said to be in particular normal form if it satisfies constraints. Let's dive more into the topic of DML commands and learn more about their importance in SQL and key takeaways. You should check out the SQL career path guide to help you explore all your career options.

|
Normal Form |
Description |
|
1NF |
A relation is in 1NF if it contains an atomic value. |
|
2NF |
A relation will be in 2NF if it is in 1NF and all non-key attributes are fully functional and dependent on the primary key |
|
3NF |
A relation will be in 3NF if it is in 2NF no transition dependency exist |
|
BCNF |
A stronger definition of 3NF is known as Boyce Codd's normal form |
|
4NF |
A relation will be in 4 NF if it is in BCNF and has no multi-valued dependency |
|
5NF |
A relation is in 5NF if it is in 4NF and does not contain any join dependency, joining should be lossless. |
Next, we will discuss the above-mentioned normal forms in more detail and we will describe what are normalizations in sql with example to make you grasp the concept better and also we will elaborate the concept of normalization in sql server.
First Normal Form
The first normal form says a table's attribute (column) cannot hold multiple values. It should only contain atomic values.
Let us assume an Empfirstnormal table containing fields called Empid, Emp_Name, Emp_Address, and Emp_mobile. The query will be as follows.
create table EmpFirstnormalform ( Emp_id varchar(100), Emp_name varchar(100), Emp_Address varchar(100), Emp_mobile varchar(100) )
Let us also insert some data into it. The insert query is as follows.
insert into EmpFirstnormalform(Emp_id,Emp_name,Emp_Address,Emp_mobile) select '101',' Rick',' Delhi', '88859121' union select '101',' Rick',' Delhi', '86251028,8677892410' union select '123',' Maggie',' Agra', '88845555' union select '166',' Glenn',' Chennai', '87445577,87465542'
The final output looks like the one below.
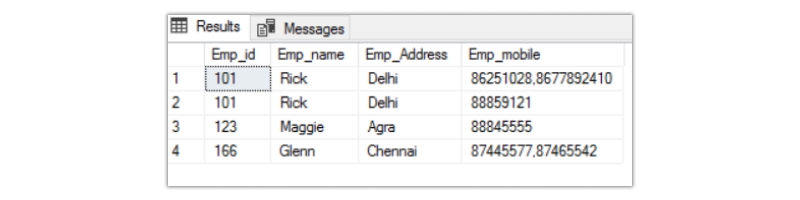
As you can see, in the Emp_mobile column, multiple phone numbers are separated by a comma. The first normal form does not allow that. So the modified table will look like the one below.
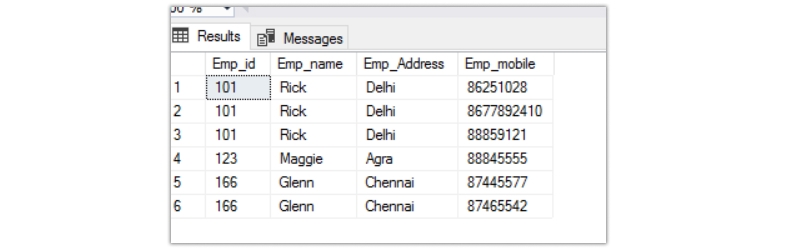
The query to create the table is as below.
create table EmpFirstnormalformmodified ( Emp_id varchar(100), Emp_name varchar(100), Emp_Address varchar(100), Emp_mobile varchar(100) )
And the following are the insert statements.
insert into EmpFirstnormalformmodified(Emp_id,Emp_name,Emp_Address,Emp_mobile) select '101',' Rick',' Delhi', '88859121' union select '101',' Rick',' Delhi', '86251028' union select '101',' Rick',' Delhi', '8677892410' union select '123',' Maggie',' Agra', '88845555' union select '166',' Glenn',' Chennai', '87445577' union select '166',' Glenn',' Chennai', '87465542'
The second normal form says
For this, let us assume a table called Teachersecondnormalform with the fields like teacher_id, subject, and teacherage. The query for creating the tables is as follows:
create table Teachersecondnormalform ( teacher_id varchar(100), subject varchar(100), teacherage varchar(100), )
And the query to enter data is as follows
insert into Teachersecondnormalform(teacher_id,subject,teacherage) select '101',' Maths',38 union select '111', 'Physics',40 union select '222',' Biology',50 union select '333',' Physics',50 union select '333', 'Chemistry',50
The output is as follows
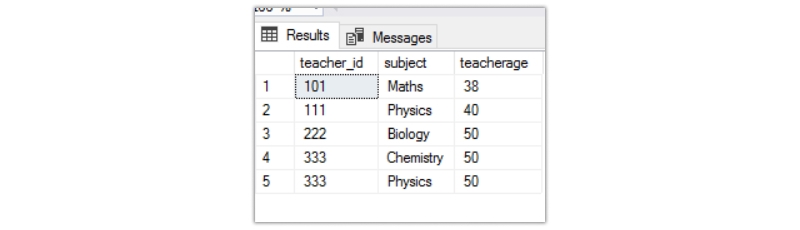
Here, the subject and the teacherage column are individually dependent on the teacher_id column. The second normal form does not allow this. To bring the table into the second normal form, we must break the single table into two separate tables. The output will be as below.
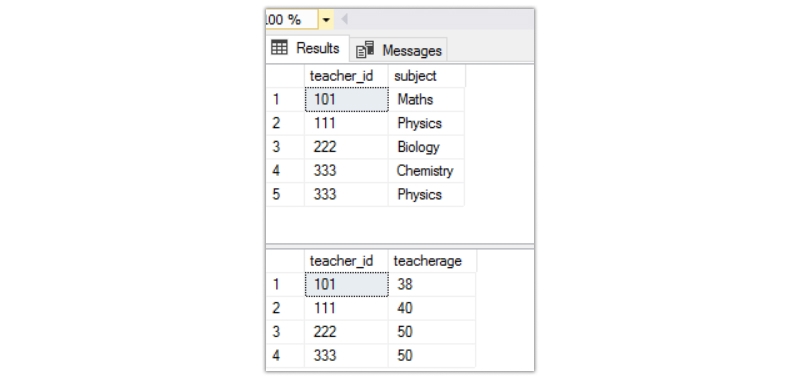
The query to create the table and insert the data into those two tables is as below.
create table Teachers ( teacher_id varchar(100), teacherage varchar(100), ) create table teachers' subject ( teacher_id varchar(100), subject varchar(100), )
insert into teachers subject(teacher_id,subject) select '101',' Maths' union select '111', 'Physics' union select '222', 'Biology' union select '333', 'Physics' union select '333', 'Chemistry' insert into Teachersage(teacher_id,teacherage) select '101',38 union select '111',40 union select '222',50 union select '333',50
The third normal form says
To discuss this, let us take the example of the table emp-third-normal-form with the following fields emp-id,emp-name,emp-zip,emp-state,emp-city,emp-district. The query for the table creation is as follows.
create table empthirdnormalform ( empid varchar(100), empname varchar(100), empzip varchar(100), empstate varchar(100), empcity varchar(100), empdistrict varchar(100) )
And the query to enter data is as follows
insert into emp-third-normal-form (emp-id,emp name,emp-zip,emp-state,emp-city,emp-district) select '101',' John', '282005',' UP', 'Agra', 'Dayalbagh' union select '111', 'Sara', '282006',' West Bengal',' Kolkata',' Lake Gardens' union select '112', 'Sara1', '282007', 'Maharastra',' Mumbai',' Bandra' union select '113', 'Sara2', '282008',' Tamil Nadu', 'Chennai',' RT Nagar'
The output of the table looks like below
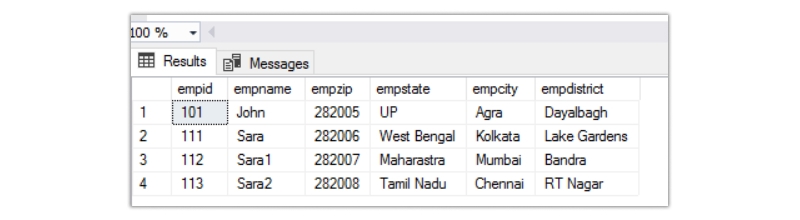
If you look closely at the table, the fields estate,emp-city, and emp-district are individually dependent on emp-zip.To remove this anomaly, we must create two separate tables, employee and employee-zip, one containing emp-id,emp-name, and emp-zip and the other emp-zip,emp-state,emp-city, and emp-district.
The query for the two new tables is as follows.
create table employee
(
empid varchar(100),
empname varchar(100),
empzip varchar(100),
)
create table employee_zip
(
empzip varchar(100),
empstate varchar(100),
empcity varchar(100),
empdistrict varchar(100)
)
Following are the query to insert data in those two tables.
insert into employee(emp-id,emp-name,emp-zip) select '101',' John', '282005' union select '111',' Sara', '282006' union select '112', 'Sara1', '282007' union select '113', 'Sara2', '282008' and insert into employee_zip(emp-zip,emp-state,emp-city,emp-district) select '282005',' UP',' Agra', 'Dayalbagh' union select '282006',' West Bengal',' Kolkata',' Lake Gardens' union select '282007', 'Maharastra', 'Mumbai', 'Bandra' union select '282008',' Tamil Nadu', 'Chennai',' RT Nagar'
A database anomaly is a fault in a database that usually emerges as a result of shoddy planning and storing everything in a flat database. In most cases, this is removed through the normalization procedure, which involves the joining and splitting of tables.
There are namely three types of anomalies:
Let us now understand them in more detail. For that, let us create a table called Emp and fill it up with some data. Following is the code to create the table and insert data into it.
To create the table Emp
create table Emp ( Emp_id varchar(100), Emp_name varchar(100), Emp_Address varchar(100), Emp_dept varchar(100) )
To insert data into the EMP table
insert into Emp(Emp_id,Emp_name,Emp_Address,Emp_dept) select '101',' Rick',' Delhi',' D001' union select '101',' Rick',' Delhi',' D002' union select '123', 'Maggie', 'Agra', 'D890' union select '166',' Glenn',' Chennai',' D900' union select '166',' Glenn',' Chennai',' D004'
The output looks like below:
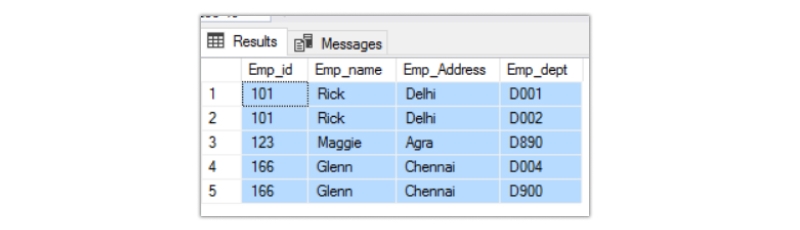
An insertion anomaly is an inability to add data to the database due to the absence of other data.Here in this example, if a person joins as a trainee who has not been assigned a department, it will be very difficult to enter his data into the table based on the current design as all the fields in the current table are mandatory and for the new joiner there is no department assigned.
An update anomaly is a data inconsistency that results from data redundancy and a partial update.Glenn currently looks after two departments and lives in Chennai. Suppose Glenn decides to change his address from Chennai to Kolkata. Since Glenn works in multiple departments and there are multiple entries for him in the table, data for all the rows have to be changed. If we miss out on one of the rows, it will create an error which we term an update anomaly.
A deletion anomaly occurs when you delete a record that may contain attributes that shouldn't be deleted. In the above example, if we delete department D890, all the data related to that department will be deleted.To remove all these above-mentioned anomalies, we implement normalization.
The normalization process in database management systems has various benefits. Here is a list of some of the advantages that the normalizations in dbms method offers:
SQL Training For Administrators & Developers

Over the last few paragraphs, we have learned about different aspects of normalization, its utility, advantages, and disadvantages with practical examples. This blog will help you understand what is normalization and and various types of normalisations in sql with example, and give you enough interest to learn normalization in more detail with our professional certification course.
FAQ’s
What are The Benefits of Sql Server Certification Course?
Ans: There are various advantages of opting for the sql server certification course. The online sql certification course allows you to take the sessions from the comfort of your home. Also, the sql server certification course allows you to handle database solutions and different operations existing on database, transfer them to the cloud, and scale them as per requirements.
What are The Different Career Opportunities That Can be Gained Through Sql Server Certification Course?
Ans: You can easily learn online sql from the comfort of your place withou the need to travel to distant places and take sessions. Also, the online sql certification course allows you to opt for various career paths including Data Scientist, Data Analyst, Business Analysts, Business Intelligence Developer, Software Developer, Database Architect and Database Administrator. So, learn online sql and become a professional in this field.
What are The Prerequisites Necessary to Receive The Sql Server Certification?
Ans: There are no such prerequisites to enroll for the online sql certification course. All you need to have is a fundamental knowledge related to relational DBMS that will let you understand everything about MS SQL Server.
Can You State The Five Rules Related to Normalizations in DBMS?
Ans: The five rules for the normalizations in dbms are :- Eradicate Repeating Groups, Eradicate Useless Data, Eradicate Columns Independent of Key, Abandon Independent Multiple Relationships, and Abandon Semantically Connected Multiple Relationships.
What do You Mean By Normalization in SQL?
Ans: Precisely speaking, normalization in SQL refers to the method of evading data redundancy and highlighting data integrity across the table. The sql normalization also assists in arranging the data present in the database. The normalization in sql server constitutes a multi-step method that arranges the data in a tabular way, wiping off the identical data from the relational tables.

Database Files-Heart of SQL Server Database
 Apr 26, 2023
Apr 26, 2023  5k
5k
Data Definition Language (DDL) Commands in SQL
May 15, 2023 4.6k
Different Types of DBAs and Their Roles
Aug 22, 2023 4.5k
What is Schema in SQL With Example: All You Need to Know
May 24, 2023 4.2k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







