Grab Deal : Flat 30% off on live classes + 2 free self-paced courses - SCHEDULE CALL
The idea of Rough sets were introduced in Z Pawlak's foundational paper which was published in 1982. (Pawlak 1982). It is a formal theory constructed after years of research on the logic behind computer systems. Rough set theory has been utilized for database mining and finding new information in relational databases for a long time. It's a new subfield of uncertainty mathematics with a lot in common with fuzzy theory, conceptually speaking.
Understanding rough set approach in data analysis begins with understanding data science; you can get an insight into the same through our data science training. In this blog, we will delve deeper into the concept of Rough Set theory, its underlying principles, and explore some real-world applications of this powerful data analysis tool. We will discuss how Rough Set theory can be used for feature selection, data reduction, rule induction, and decision-making. By the end of this blog, you will have a better understanding of how Rough Set theory can be applied to solve real-world problems in data science.
The rough set approach is a technique that may be utilized to discover previously unknown structural connections when working with incomplete or noisy data. Rough sets and fuzzy sets, which are helpful extensions of classical set theory, are also examples. The rough set theory deals with sets with a large number of members, in contrast to the fuzzy set theory, which focuses on only partial memberships. Because of the rapid pace at which they have evolved, these two approaches serve as the foundation for "soft computing," a phrase conceived by Lotfi A. Zadeh. Rough sets are just one component of Soft Computing; other components include fuzzy logic, neural networks, probabilistic reasoning, belief networks, machine learning, evolutionary computing, chaos theory, and more. Rough sets are just one component of Soft Computing. Rough sets are just one component.
Discovering hidden patterns in data that is either unreliable or noisy can be accomplished through classification utilizing rough set theory. This rule applies to variables with a predetermined set of potential values to take. This indicates that the discretization of continuous-valued attributes is necessary prior to their application for them to be used.Determining comparable classes included in the currently accessible training data serves as the basis of rough set theory. Each and every tuple that constitutes an equivalence class has the same values for the characteristics employed in the process of characterizing the data. When working with data from the real world, it is fairly unusual for certain classes to lack good differentiating traits. This is especially typical when dealing with financial data. Using rough sets allows such categories to be established in a "rough" fashion.
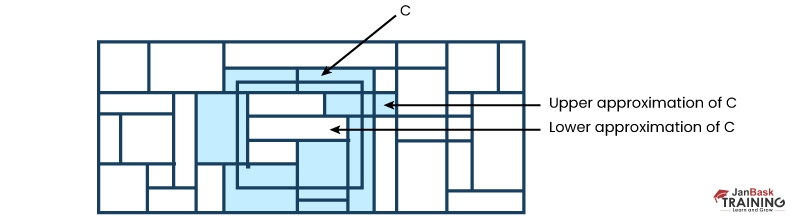
An upper approximation of class C and a lower approximation of class C are used to approximate a rough set definition for a given class called C. These two sets are higher and lower approximations of class C, respectively. The lower approximation of C is represented by the collection of data tuples that, on the basis of an in-depth comprehension of C's characteristics, are able to be recognized beyond a shadow of a doubt as being a component of C. The upper approximation of C comprises all of the tuples that, based on the information provided by the attributes, it is impossible to portray as not belonging to C. In Figure 1, the rectangles represent equivalence classes with lower and higher approximations for class C. These values are shown in the figure. It is possible to design the decision rules for each class.
In most cases, the rules are presented as a decision table.
Rough sets can be used for attribute subset selection (also known as feature reduction), which allows for identifying and removing attributes that do not contribute to the classification of the given training data. Rough sets can also be used for relevance analysis, which evaluates the contribution or significance of each attribute in relation to the classification task. Both of these analyses can make use of rough sets. On the other hand, strategies have been developed that lighten the computational workload. One method, for instance, is using a discernibility matrix to document the changes in attribute values for each pair of data tuples. The matrix, as opposed to the entire training set, is inspected to seek the same traits.Remember that what you're looking at in the table columns are called illustrations (objects, entities). U is a set of non-empty finite objects, and A is a set of non-empty finite attributes; the two sets that make up an information system are denoted by the letters U, and A. Statements that follow an if-then format make up the many elements that make up A. When an information table has one or more choice characteristics, people often refer to such a table as a decision table. Each component of a pair in a decision system (U, A union d) stands for a criterion considered while making a choice (instead of one, we can consider more decision attributes).
A table's sections containing graphics are called rows (objects, entities). U is a set of non-empty finite objects, and A is a set of non-empty finite attributes; the two sets that make up an information system are denoted by the letters U, and A. Statements that follow an if-then format make up the many elements that make up A. When an information table has one or more choice characteristics, people often refer to such a table as a decision table. Each component of a pair in a decision system (U, A union d) stands for a criterion considered while making a choice (instead of one, we can consider more decision attributes).When objects are similar in a table, it might be difficult to differentiate between them. One strategy for lowering the amount of space required by a table is just to record the presence of a single instance of each item across all groups of things with the same qualities. Tuples, often known as indiscernible objects, are another name for these items. Any subset A of P is connected with an equivalence relation called IND(P), which states were IND(P) is called indiscernibility of relation. Here x and y are indiscernible from each other by attribute P.
The rough set approach is a mathematical tool used in data analysis, which aims to identify patterns and relationships within complex datasets.
Overall, the goals of rough set approach are centered around improving decision-making processes through accurate and efficient data analysis techniques.
Rough set theory is an innovative approach developed to address the apparent fuzziness and ambiguity in the decision-making process. The field of study known as data mining makes a significant contribution to the analysis of data, the unearthing of new and valuable information, and the process of autonomous decision-making.
Rough set theory is a mathematical paradigm that efficiently deals with data uncertainty and ambiguity. It is a powerful data analysis tool that extracts critical information from vast and complex datasets. There are different areas where rough set theory aids in data processing:
Overall, rough set theory provides a paradigm for dealing with data's uncertainty and ambiguity, critical for data analysis, and helps in making informed decisions and drawing conclusions.
Rough set theory is a mathematical approach to data analysis that has gained significant attention in recent years. It is an essential tool for data scientists who deal with large and complex datasets, as it provides a unique way of analyzing the information contained within them. The primary goal of rough set theory in data science is to extract useful knowledge from raw data.The first objective of rough set theory is to reduce the complexity of large datasets by eliminating redundant or irrelevant attributes, thereby simplifying the overall structure of the dataset. This process involves defining equivalence classes based on similarity rules and identifying which attributes are necessary for distinguishing between these classes.Once attribute reduction has been achieved, another crucial goal of rough set theory in data science is classification. Classification refers to assigning objects into predefined categories based on their features or characteristics. Rough sets provide a powerful method for classifying objects by exploiting relationships among attributes that have been identified through attribute reduction.
Another important application area where rough set theory plays a vital role in data science is feature selection. Feature selection refers to selecting only those features that are most relevant for solving a particular problem while discarding irrelevant ones. In this context, rough sets help identify subsets of features that contribute significantly toward achieving high accuracy levels while avoiding overfitting problems due to excessive feature redundancy.In summary, the goals of rough set theory in data science include reducing dataset complexity by eliminating redundant or unnecessary attributes, facilitating classification tasks by exploiting relationships among remaining attributes and enabling efficient feature selection techniques for improving model performance without sacrificing accuracy levels. By achieving these objectives effectively, researchers can gain valuable insights into complex datasets and make informed decisions based on accurate predictions generated from such analyses using various machine learning algorithms like decision trees and neural networks etcetera .
Data Science Training For Administrators & Developers

The Rough Set approach is a valuable tool for data analysis and decision-making in various fields. It allows us to extract essential information from complex datasets by simplifying them into smaller subsets of relevant attributes. By using this approach, we can identify patterns and relationships that might have been missed otherwise. However, it's important to note that this method has its limitations and may not be suitable for all types of data.
If you're interested in exploring the Rough Set approach further, we recommend trying out Janbask Training certification courses that incorporate this technique. Additionally, keep in mind that combining different methods and techniques can often produce more robust results than relying on just one.Overall, the Rough Set approach provides a powerful way to analyze large volumes of data while minimizing complexity. Whether you're working with customer data or scientific research findings, incorporating this method into your workflow could help you make better decisions based on accurate insights. So why not give it a try?
What is The Difference Between Fuzzy Set and Rough Set in Data Mining?
Ans. The rough set in data mining and the fuzzy set determine two basic and mutually perpendicular features of erroneous data. Fuzzy sets allow that things correspond to a certain set or connections to a specified degree, but rough set in data mining gives approximations of ideas on the basis of imperfect data or knowledge.
What are The Objectives for Rough Set in Data Mining?
Ans. The prime motive is the estimation of ideas. It also provides calculative tools to detect hidden data patterns. Another goal for rough set in data mining is that it aims at choosing feature, retrieving it and reducing the data. The rough set also aims at retrieving patterns such as templates from the data. Besides this,the rough set also detects partial or entire reliance in data, eradicates useless data, and offers a shape to missing data as well.
Mention The Advantages of Rough Set in Data Mining?
Ans. The prime benefit of rough set theory in data mining contributes to the fact that it does not require any primary or extra details about the data such as probability concerns, required in statistics or the value of probability required in a fuzzy set.
Is it Difficult to Learn Data Mining?
Ans. Data mining can seem to be a challenging method to learn. However, grasping this vital field is not much hard. Enroll today at Janbask Training and get a comprehensive guide on data mining techniques to proceed further in this field. You can get proper guidance from top mentors through online sessions, and establish yourself as an expert in this field in future.
What are The Stages Involved in The Process of Data Mining?
Ans. The stages of data mining include:

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  10.1k
10.1k Mar 03, 2023 9.7k
Mar 03, 2023 9.7k

Rule-Based Classification in Data Mining
Mar 27, 2023 9.6k
Cyber Security

QA

Salesforce

Business Analyst

MS SQL Server

Data Science

DevOps

Hadoop

Python

Artificial Intelligence

Machine Learning

Tableau
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment







