Month End Offer : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
Data integration is the process of bringing together data from many sources within an organization to produce a full, accurate, and up-to-date dataset for business intelligence (BI), data analysis, and other applications and business processes. It involves the replication, ingestion, and transformation of data in order to merge various forms of data into standardized formats before their storage in a destination repository such as a data warehouse, data lake, or data lakehouse.
Currently, Data Integration expertise is in great demand and most IT professionals are working on improving their skills and thereby Data Science Online Certification has become necessary for greater acumen!
The data integration methodologies are formally characterized as a triple G, S, M>, where
G stand for the global schema,
S stands for the heterogeneous source of schema,
M stands for mapping between the queries of source and global schema.
Let's dive more into the topic of Data Integration and learn more about its importance in data science or data mining and key takeaways. You should check out the data science tutorial guide to brush up your basic concepts.
Data integration may be carried out using one of five distinct strategies, often known as patterns. These strategies are called ETL, ELT, streaming, application integration (API), and data virtualization. Data engineers, Data scientist, Data architects, and developers can either manually code an architecture using SQL to implement these processes, or, more commonly, they can set up and manage a data integration tool, which streamlines development and automates the system. Manually coding an architecture is the more time-consuming option.
The diagram below depicts their place in a contemporary data management process, which converts unprocessed data into information that is clean and ready for use in business.
Below are the five primary approaches to execute data integration:
Extract, transform, and load are the three stages that make up the ETL pipeline, which is a conventional type of data pipeline that conforms raw data to the specifications of the destination system. Before being put into the repository of interest, data goes through a series of transformations in a staging area (typically a data warehouse). This enables quick and precise data analysis in the target system, and it is best suited for use with tiny datasets that call for sophisticated transformations.
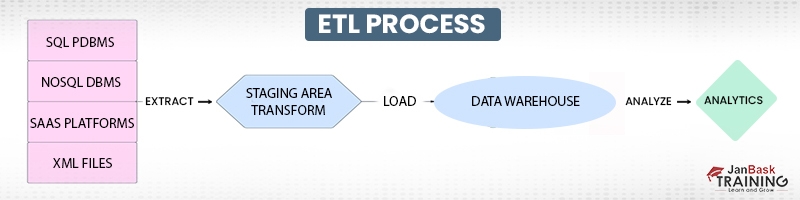
Change data capture, often known as CDC, is a technique that is used in ETL and refers to the process or technology that is used to recognise and record the modifications that are made to a database. After that, these alterations can be implemented into a different data repository or made accessible in a format that can be consumed by ETL, EAI, or any other kinds of data integration tools.
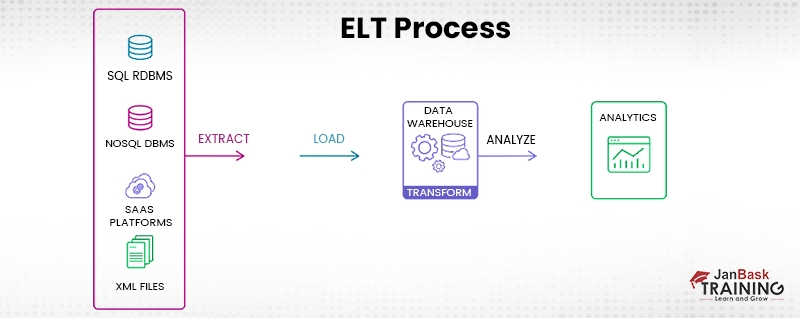
In the more current ELT pipeline, the data is imported into the target system, which is often a cloud-based data lake, data warehouse, or data lakehouse, instantly, and then the data is converted within the target system. Because loading is often faster using this method, it is better suited for use in situations in which the amount of time available is of critical importance. ELT can work on a micro-batch or change data capture (CDC) period, depending on the situation. Micro-batch, also known as "delta load," loads just the data that has been changed since the most recent successful load. On the other hand, the CDC consistently loads new data whenever there is a new version available from the source.
Streaming data integration transports data constantly and in real-time from its source to its goal, as opposed to the traditional method of loading data into a new repository in batches. Platforms for modern data integration (DI) have the capability to provide data that is ready for analytics into streaming and cloud platforms, data warehouses, and data lakes.
Application programming interfaces, or APIs, make it possible for disparate software programmes to communicate with one another and share data by transferring and synchronizing it. The most common use case is to support operational needs, such as making sure that your HR system and your financial system have the same data. This is an example of a typical use case. Therefore, the application integration has to guarantee that the data sets are consistent with one another. Additionally, each of these different apps often have their own APIs for providing and getting data; therefore, SaaS application automation solutions may assist you in developing and maintaining native API interfaces in an effective and scalable manner.
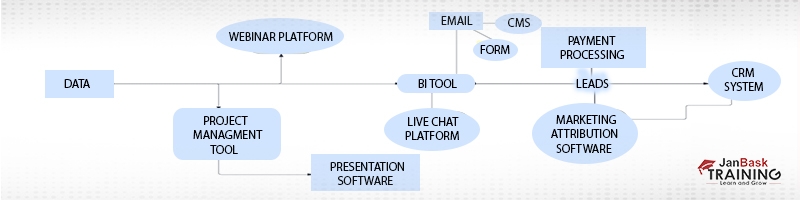
The following is an illustration of a flow of B2B marketing integration:
Similar to streaming, data virtualization also sends data in real time, but it does so only when a user or application specifically requests it to do so. By digitally merging the data from several systems, this may still produce a unified picture of the data and make the data available on demand. Transactional systems that are designed for high performance queries benefit greatly from the utilization of virtualization and streaming.
Each of these five approaches continue to evolve with the surrounding ecosystem. Historically, data warehouses were the target repositories and therefore data had to be transformed before loading. This is the classic ETL data pipeline (Extract > Transform > Load) and it’s still appropriate for small datasets which require complex transformations. However, with the rise of modern cloud architectures, larger datasets and the need to support real-time analytics and machine learning projects, data integration is shifting from ETL to ELT, streaming and API.
There are two major approaches to dat aintergation- “tight coupling” and “loose coupling”.
This approach stores integrated data in a data warehouse. Data is taken from numerous sources, processed, and fed into a data warehouse. Data is integrated in a closely connected way, which means that it is integrated at a high level, such as the level of the complete dataset or schema. This approach, sometimes known as data warehousing, ensures data consistency and integrity, but it can be rigid and hard to adapt.
A data warehouse retrieves information. Through the use of ETL (Extraction, Transformation, and Loading), data from several sources is merged into a single physical place in this coupling.
This approach includes integrating data at the record level. Data is integrated in a loosely connected way, which allows data to be integrated without the need for a central repository or data warehouse. This approach is also known as data federation, and it allows data flexibility and quick changes, but it can be challenging to maintain consistency and integrity across many data sources. An interface takes the user's query, modifies it so the source database can understand it, and delivers it straight to the source database to get the response. And the data only stays in the source databases.
When integrating data from numerous sources, several problems can occur, including:
Data Quality: Inconsistencies and mistakes make data difficult to assemble and interpret.
Data Semantics: Different sources may use different phrases or definitions for the same data, making it hard to integrate and interpret.
Data Heterogeneity: Different sources may utilize different data formats, structures, or schemas, making it difficult to aggregate and evaluate the data.
Privacy and Security: Integrating data from many sources might be tricky.
Scalability: Integrating big volumes of data from numerous sources can be time-consuming and computationally expensive.
Data Governance: Integrating data from numerous sources may be problematic, especially when it comes to accuracy, consistency, and timeliness.
Integration with Current Systems: Integrating new data sources with existing systems can be difficult and time-consuming.
Complexity: Integrating data from numerous sources can be challenging, requiring specific knowledge and abilities.
Here we’ll focus on the four primary use cases: data ingestion, data replication, data warehouse automation and big data integration data mining.
Moving data from its many sources into a storage facility such as a data warehouse or data lake is part of the process known as "data intake." Ingestion can take place in real time as a stream or in batches, and it often involves cleaning and standardizing the data in order to get it suitable for analysis using a data analytics tool. Migration of your data to the cloud or the construction of a data warehouse, data lake, or data lakehouse are all examples of data intake.
During the process of data replication, data is replicated and transferred from one system to another. For instance, data may be moved from a database located in a data center to a data warehouse located in the cloud. This guarantees that the appropriate information is backed up and that it is synced to the operational usage. It is possible for replication to take place in bulk, in batches on a predetermined schedule, or in real time across many data centers and/or the cloud.
By automating the many stages of the data warehouse lifecycle, the data warehouse automation process speeds up the availability of data that is ready to be analyzed. These stages include data modeling, real-time data intake, data marts, and governance. This graphic outlines the primary processes involved in the automation and ongoing refining of the process of creating and operating a data warehouse.
In order to move and manage the enormous amount, diversity, and velocity of structured, semi-structured, and unstructured data that is associated with big data, improved technologies and strategies are required. The purpose of this exercise is to furnish your big data analytics tools and any other applications you may be using with an accurate and up-to-date picture of your company. This indicates that your system for integrating big data needs sophisticated big data pipelines that can automatically transfer, combine, and convert large amounts of data from many data sources while still keeping the data's lineage. In order for it to manage real-time and continuously streaming data, it has to have strong scalability, performance, profiling, and data quality characteristics.
In the end, data integration will break down the data silos that you have and provide you the ability to study and act upon a trustworthy, one source of controlled data that is dependable. Ad platforms, CRM systems, marketing automation, web analytics, financial systems, partner data, and even real time sources and IoT are just some of the sources that are flooding organizations with large and complex datasets. Our self-learning data-science courses offer an excellent opportunity to become proficient in data integration by immersing oneself in a comprehensive study of data engineering and science.
These datasets come from a wide variety of sources that are not connected to one another. All of this information can't be put together to paint a comprehensive picture of your company unless analysts or data engineers put in numerous hours compiling the data for each report.
Integration of data pulls together different data silos and delivers a dependable, one source of controlled data that is current, comprehensive, and accurate throughout its lifecycle. This makes it possible for analysts, data scientists, and businesspeople to utilize business intelligence (BI) and analytics tools to explore and analyze the whole dataset in search of trends, and then to derive actionable insights that enhance performance as a result of their findings.
Accuracy and Trust Have Been Improved: You and the other stakeholders no longer need to question whether key performance indicator (KPI) from which tool is accurate or whether or not particular data has been included. You also run a far lower risk of making mistakes and having to redo work. Integrating several sources of data produces a trustworthy, centralized repository of consistent, authoritative, and audited information, sometimes known as "one source of truth."
More Data-Driven and Collaborative Decision-Making: Once raw data and data silos have been turned into accessible and analytics-ready information, users from throughout your company are much more likely to engage in analysis. This opens the door to more data-driven decision-making. They are also more inclined to work across departments since the data from every element of the company is merged, and they can see clearly how their activities affect each other. This makes it more probable that they will collaborate across departments.
Efficiency : When analysts, developers, and IT personnel don't have to spend their time manually collecting and processing data, or constructing one-off connections and individualized reports, they have more time and mental bandwidth to devote to more strategic endeavors.
Integration of applications and integration of data are closely similar concepts, yet there are significant distinctions between the two. Let's go through some of the fundamental processes and definitions:

Application programming interfaces, or APIs, make it possible for disparate software programmes to communicate with one another and share data by transferring and synchronizing it. The most common use case is to support operational needs, such as making sure that your HR system and your financial system have the same data. This is an example of a typical use case. Therefore, the application integration has to guarantee that the data sets are consistent with one another. Additionally, each of these different apps often have their own APIs for providing and getting data; therefore, SaaS application automation solutions may assist you in developing and maintaining native API interfaces in an effective and scalable manner.
As was just said, the process known as data integration (DI) involves moving data from several sources into a single consolidated place. The most common use case is to provide support for business intelligence and analytics solutions. In the past, data integration mostly concentrated on moving static relational data from one data warehouse to another, but modern data integration technologies and methods can manage live, operational data in real time.

Data Science Training
To put it simply, data integration allows businesses to have all of their information in one place is an understatement. It is, in fact, the first and most important step that enterprises must take in order to realize their full potential. It is difficult to imagine the many benefits of this topic unless you go deeply into it. Begin our data science online certification course today to improve your skills and set yourself out from the crowd.

Basic Statistical Descriptions of Data in Data Mining
 May 11, 2023
May 11, 2023  12.1k
12.1k
What is Model Evaluation and Selection in Data Mining?
Mar 28, 2023 12.1k

Rule-Based Classification in Data Mining
Mar 27, 2023 11.7k
Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Download Syllabus
Get Complete Course Syllabus
Enroll For Demo Class
It will take less than a minute
Tutorials
Interviews
You must be logged in to post a comment










