
 Apr 25, 2020
Apr 25, 2020  6k
6k

25
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Data Science Blogs -
Autoencoders are a particular kind of feed-forward neural systems where the input is equivalent to the output. They pack the input to a lower-dimensional code and afterward reproduce the output from this portrayal. The code is a smaller “summary” of the input, likewise called the latent space representation. Autoencoders are trained similarly like ANNs. 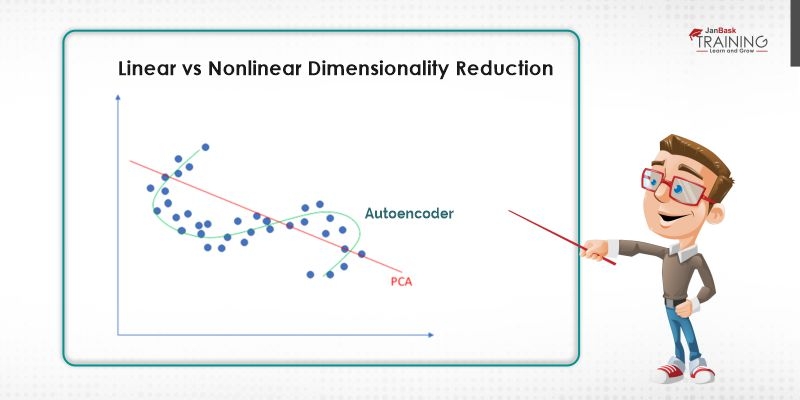
Autoencoder, by configuration, reduces information measurements by figuring out how to ignore the noise in the information. An encoder consist of three components and these components are as follows:
For the construction of an autoencoder, we require 3 things: an encoding strategy, decoding strategy, and a loss function which is used to compare the output and the objective.
Data Science Training - Using R and Python

Autoencoders are chiefly a dimensionality reduction calculation with two or three significant properties:
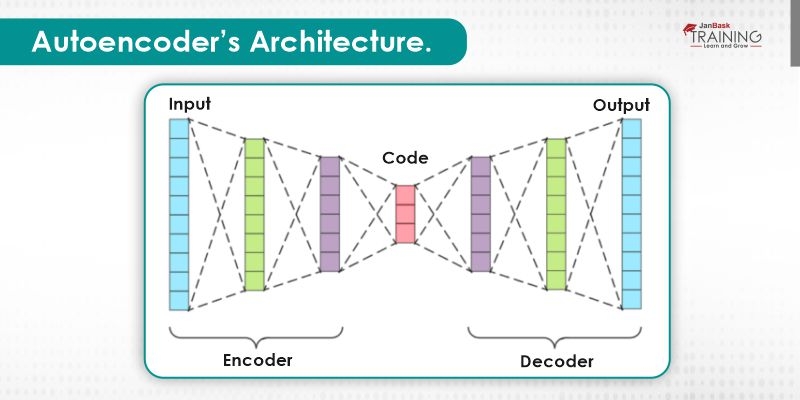
Both the encoder and decoder are completely associated with feed-forward neural systems, basically the ANNs. Code is a single layer of an ANN with our preferred dimensionality. The number of nodes in the code layer or can say code size is a hyperparameter that we set before preparing the autoencoder. This is a progressively visualized representation of an autoencoder. First, the data goes through the encoder, which is a completely associated ANN, to create the code. The decoder, which has the comparative ANN structure, at that point creates the input by just utilizing the code. The objective is to get an output indistinguishable with the data. Note that the decoder design is the identical representation of the encoder. This isn't a necessity however it's ordinarily the situation. The main prerequisite is the dimensionality of the data and output should be the equivalent. Anything in the center can be played with.
Data Science Training - Using R and Python

There are four hyperparameters that we need to set before training an autoencoder:
There are mainly 6 types of autoencoders

Autoencoders are found out naturally from information models. It particulates that there is anything but difficult to prepare particular examples of the calculation that will perform well on a particular sort of information and it doesn't require any new technology, just the preparing information which fits the autoencoder.
Data Science Training - Using R and Python

Since autoencoders consist of encoder and decoder both. The former one is used to transform the input by generating codes which are crisp and short from the high dimensional image whereas the latter one is used to transform the generated code into the high dimensional image.
When one is working with autoencoders, one must have known the dimensionality of the image. For a p-dimensional code, the encoder will be:

And the decoder will be:

On combining both encoder and decoder, full autoencoder will be:

Autoencoders are prepared to save however much data as could be expected when information is gone through the encoder and afterwards the decoder, but at the same time are prepared to cause the new portrayal to have different decent properties. Various types of autoencoders intend to accomplish various types of properties.
Importing libraries:
from keras.layers import Input, Dense
from keras.models import Model
from keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
(X_train, _), (X_test, _) = mnist.load_data()
X_train = X_train.astype('float32') / 255.
X_test = X_test.astype('float32') / 255.
X_train = X_train.reshape((X_train.shape[0], -1))
X_test = X_test.reshape((X_test.shape[0], -1))INPUT_SIZE = 784 ENCODING_SIZE = 64 input_img = Input(shape=(INPUT_SIZE,)) encoded = Dense(ENCODING_SIZE, activation='relu')(input_img) decoded = Dense(INPUT_SIZE, activation='relu')(encoded) autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adam', loss='mean_squared_error')
autoencoder.fit(X_train, X_train, epochs=50, batch_size=256, shuffle=True, validation_split=0.2)
decoded_imgs = autoencoder.predict(X_test)
plt.figure(figsize=(20, 4))
for i in range(10):
# original
plt.subplot(2, 10, i + 1)
plt.imshow(X_test[i].reshape(28, 28))
plt.gray()
plt.axis('off')
# reconstruction
plt.subplot(2, 10, i + 1 + 10)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
plt.axis('off')
plt.tight_layout()
plt.show()
There are several usages of autoencoders, some major usages are:
Autoencoders is used for colouring of any black and white picture. Depending on the picture it can be easily identified that which colour should be used for colouring.
Autoencoders are used to reconstruct a given image by reducing its dimensions. Dimensionality reduction using autoencoders results from a similar image with reduced pixel values. Loss of picture information is almost minimal.
Autoencoders are used to remove noises from input images. In this process, the original input image was reconstructed from the noisy image.
One can extract the required feature of an image using autoencoder and generates the desired output by eliminating the noise or unnecessary interruption from the image.
Using autoencoders, one can also remove the watermarks present in an image.
Data Science Training - Using R and Python

Autoencoders are a valuable dimensionality reduction technique. They are well known as an encouraging material in early on deep learning courses, in all likelihood because of their straightforwardness. An autoencoder is a neural system design fit for finding structure inside information so as to build up a compressed representation of the input. A wide range of variations of the general autoencoder design exist with the objective of guaranteeing that the compressed representation speaks to important properties of the first data input; commonly the greatest test when working with autoencoders is getting your model to really gain proficiency with a significant and generalizable latent space representation. Since autoencoders figure out how to compress the data-dependent on traits (i.e. relationships between the info include vector) found from data during preparing, these models are commonly just fit for remaking information like the class of perceptions of which the model saw during preparing.
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Gen AI

Agentic AI

AI in Automation Testing

Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Data Science Course
Interviews









 Mar 06, 2024
Mar 06, 2024 633.7k
633.7k

 633.7k
633.7k