
 Jan 22, 2020
Jan 22, 2020  5.9k
5.9k

04
JulMonth End Offerl : Get 30% OFF + $999 Study Material FREE - SCHEDULE CALL
- Data Science Blogs -
Trees form the basis of any human life. They are pillars for sustaining human life. The same can be said about trees in decision making. Everyone has been in a scenario where he or she has to say a yes or no to a particular question and that question will form the basis of the next question like an interview or a viva-voce. Thus, it is no different than decision trees have also found an extremely comfortable position in the world of machine learning and have positioned themselves as extremely useful in classification as well as regression. As the name suggests, this algorithm uses a tree-like model for making decisions.
In this blog, we will be going through trees with a focus on their use in the domain of data science. First of the representation of an algorithm as a tree will be discussed followed by the terminologies used in then. This will be followed by the use of decision in modern-day machine learning covering its use and code part. Finally, the advantages and disadvantages of this algorithm will be presented.
Now, one of the biggest questions which we encounter is the representation of an algorithm in the form of a tree. Image calling a customer support center of a mobile phone repair center with an “intelligent computerized assistant”. The first thing that is asked is the language preference i.e. the machine will say something like press 1 for English and press 2 for Hindi. This will be followed by a number of more questions like press 1 for a new complaint, press 2 for existing complain, press 3 for repair status. This whole analogy can be represented as a tress as shown in the following figure:
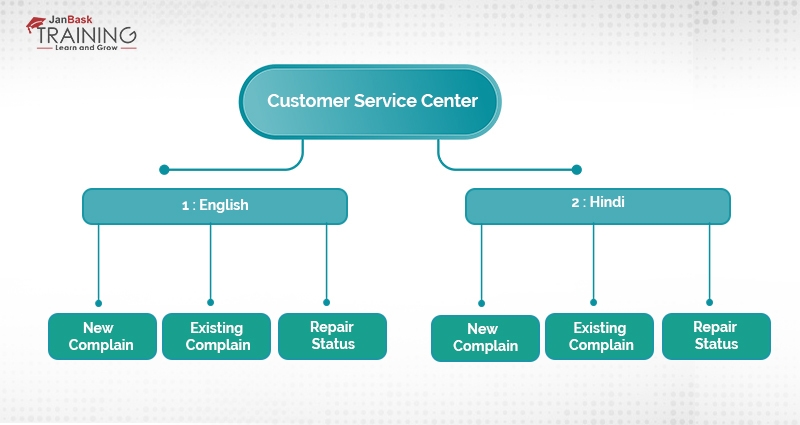
If we look closely at figure 1: Analogy to a tree, it can be observed that the flow of the intelligent computerized assistant has been depicted as an inverted tress. In this fashion, all the problems in the domain of classification, as well as regression, can be depicted as the tree.
Terminologies in decision trees:
Read: The Best Data Science Projects (Beginner To Advanced)
As it can be observed in any domain, that there exist terminologies and owing to the widespread use of decision trees in numerous domains the terminology is quite widespread. The following is most commonly used terms in about decision trees:
In the domain of machine learning, there are two main types of decision trees which are based upon the data they are intended for. These are:
Working of decision trees:
There are a few well-known algorithms for decision trees like ID3, CART. While explaining the working of decision trees, ID3 (Iterative Dichotomiser 3). Iterative dichotomiser starts with the native dataset as the root and with each iteration it the algorithm transverses through an unused attribute and calculates the entropy for that attribute. Entropy is defined as the measure of uncertainty in the data and is calculated as:
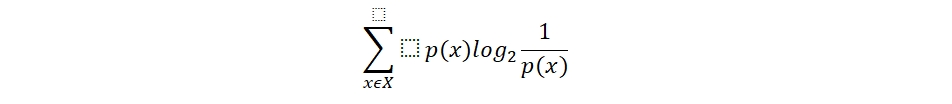
Once the entropy for all the unused attributes is calculated the attribute with the smallest entropy value is selected. The set is then split into further sub-sets for processing. This is a recursive process done until we reach a null set.
Read: What is Data Science? Learn from This Data Science Tutorial
The practical implication of this method using sklearn is quite easy and the generated tree can be visualized by using Graphviz.
First of all, let's import the libraries and iris dataset (it comes with sklearn and is a classical dataset which is openly available.
from sklearn.datasets import load_iris from sklearn import tree import Graphviz
Now, the model for classification based decision tree is to be created. Command for regression tree is also the same; the only difference is that the data being supplied into machine is continuous in nature.
train_iris, target_iris = load_iris(return_X_y=True) model_tree = tree.DecisionTreeClassifier() model_tree = model_tree.fit(train_iris, target_iris)
This will train and model and decision tree can be visualized by using graphviz as
dot_data = tree.export_graphviz(model_tree, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("d:\iris")
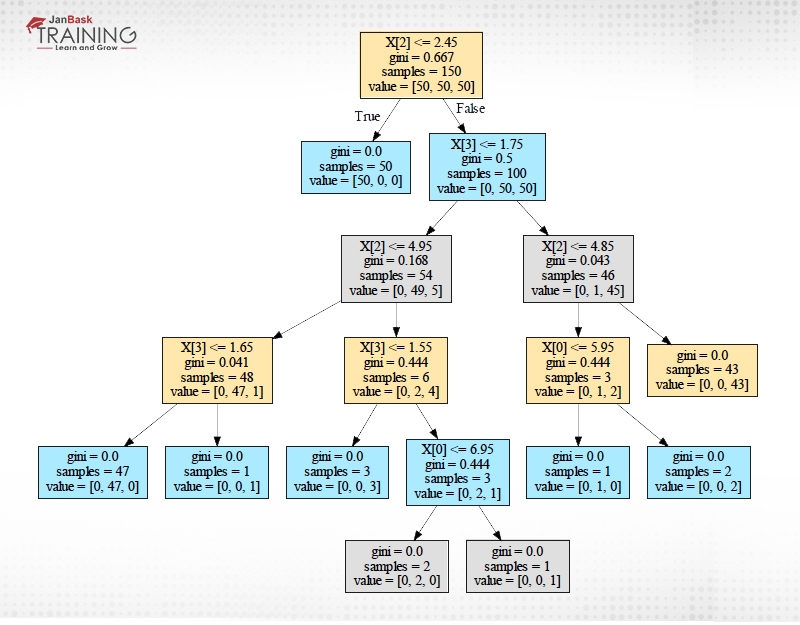
This will save a pdf file in D: as iris.pdf which will contain the following decision tree:
Read: How Online Training is Better Than In-Person Training?
Pros and cons of decision trees
Advantages
Disadvantages
Concluding Remarks:
As can be observed from the study of decision trees, they are quite handy stuff owing to ease of use as well as the white box approach. There are scenarios where they don’t make a good fit. Whatever the case may be but these models assist in evaluating the possible outcomes and provide a visual representation of these outcomes. Hence, these remain a very handy tool.
Please leave the query and comments in the comment section.
Read: What is Hypothesis Testing | Steps, Types, and Applications
 FaceBook
FaceBook
 Twitter
Twitter
 LinkedIn
LinkedIn
 Pinterest
Pinterest
 Email
Email
The JanBask Training Team includes certified professionals and expert writers dedicated to helping learners navigate their career journeys in QA, Cybersecurity, Salesforce, and more. Each article is carefully researched and reviewed to ensure quality and relevance.




Cyber Security

Data Science

QA

Salesforce Service Cloud

AWS
Search Posts
Related Posts
Receive Latest Materials and Offers on Data Science Course
Interviews












 Feb 09, 2024
Feb 09, 2024 6.8k
6.8k

 6.8k
6.8k